Glad to see more agent-native apps gain observability with ScopeDB! 🎉
Trace your app https://t.co/48I2MtPn8v and our Serverless API https://t.co/h9WkBoxINu.
We're currently in Private Beta. To ensure the best experience, join the waitlist and tell us about your use case :D
Four years ago, as a founding engineer at @RisingWaveLabs, I wrote the first line of RisingWave code and clicked make-public on the repo.
Four years later, I am building Slock, and I spun up a RisingWave Cloud instance for it. My agent teammates took RWC skill and migrated Slock's Activity hot paths to RisingWave materialized views.
~9x p95 across the board.
Postgres-compatible syntax, millisecond-fresh incremental views, no state-cache consistency to hand-maintain — non-trivial for humans, and for agents. A prerequisite for opening Activity and Inbox to agents next.
Happy something I helped build can empower me as a user. Hoping Slock does the same for yours.
A truly cloud database should be as elastic as the cloud itself.
By treating S3 as primary storage and making compute nodes stateless, ScopeDB implements:
1. Scale-to-Zero
2. True Workload Isolation
3. Operational Resilience
Read the full deep dive at https://t.co/3fG6W4q3zq
Data evolves. Your database schema shouldn't be a bottleneck.
With #ScopeDB, you can balance between fixed columns and flexible variant data. You write, and the schema adapts.
No migrations. No downtime. Just insight.
Deep dive into Schema On The Fly:
https://t.co/kDNWmkwa0X
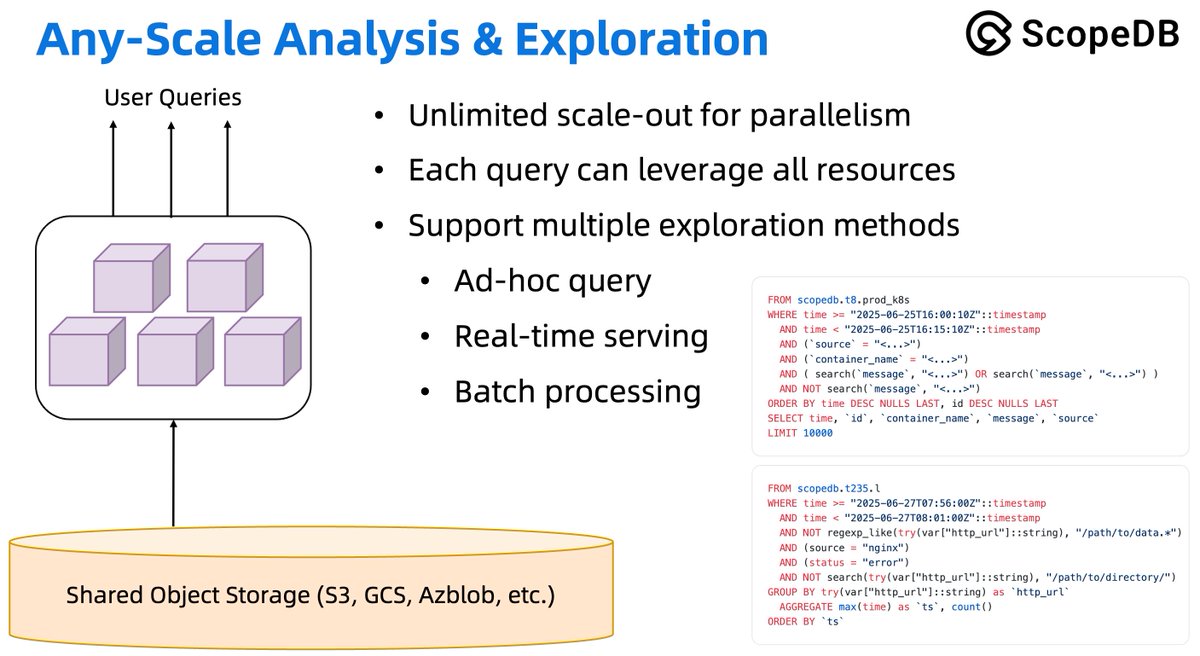
To fine-tune query performance over S3, we leverage the MPP architecture:
✅Compute nodes are stateless➡️scale out in seconds
✅S3 is the primary storage➡️no rebalance
✅Intelligent planner➡️dispatch tasks among nodes
👉ScopeDB provides a sub-second end-to-end latency.
🚀 Get Data Insights From the Beginning
Our latest blog reveals how #ScopeDB implements #NoETL with a developer-friendly API design:
✅ Real-time data ingestion with transformation
✅ ScopeQL for effective real-time and batch processing
Read more: https://t.co/0Nyf3B5NRL