Instruction Hierarchy defines how LLMs prioritize conflicting instructions. Our IH RL training dataset can makes models more robust to prompt injections, IH attacks, and better follow in-context safety specs while maintaining capabilities and helpfulness 🧵https://t.co/WFOkxfp9o7
@himbodhisattva I don't think I did, sorry. IIRC was looking for a cite for this paper: [https://t.co/vZZC17Tnuf]. But seems like it didn't make it to the final paper.
I'm trying to figure out who came up with the term "prompt injection". According to Twitter's advanced search, this seems to be the earliest Tweet that uses the term, from May 2022. What about outside of Twitter?
for services that wrap GPT-3, is it possible to do the equivalent of sql injection? like, a prompt-injection attack? make it think it's completed the task and then get access to the generation, and ask it to repeat the original instruction?
@sirbayes@docmilanfar I think this part encapsulates the idea well. He's not saying that we should have stopped working on new ASR algorithms in the 90s and scaled up HMMs ("scale is all you need"). He's saying that HMMs were directionally the right idea because they improve with compute & data.
@sirbayes@docmilanfar Do you disagree with the original essay?
https://t.co/IcuAVq2C1b
I often hear it summarized as "don't work on new algorithms; just add compute!"
It doesn't say that at all, though. It's a call for new ideas that scale with compute, not a polemic against new ideas in general.
In the world of agents, understanding the computational structure of the problem that you're trying to solve is an essential part of "understanding the data". Without that understanding it is difficult to extrapolate eval results to more complex, realistic tasks.
Wanna argue that LLMs *can* plan?
Pick a domain with a high branching factor of unenumerated actions; where the inter-action interactions are low.
Wanna argue that LLMs *can't* plan?
Pick a domain with few enumerated actions, but the action interactions are nontrivial.
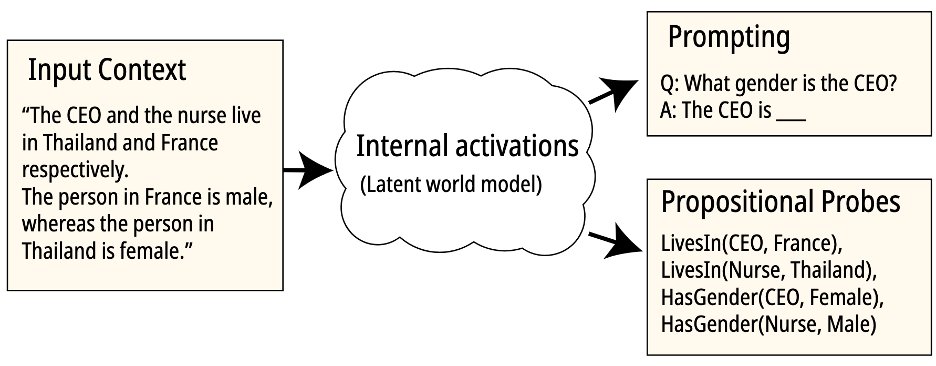
New preprint! We build on the hypothesis that language models construct latent world models of their inputs, and seek to extract latent world states as logical propositions using “propositional probes”.
New paper! We introduce Covert Malicious Finetuning (CMFT), a method for jailbreaking language models via fine-tuning that avoids detection. We use our method to covertly jailbreak GPT-4 via the OpenAI finetuning API.
Excited to share a unifying formalism for the main problem I’ve tackled since starting my PhD! 🎉
Current AI Alignment techniques ignore the fact that human preferences/values can change. What would it take to account for this? 🤔
A thread 🧵⬇️
♟️Do chess-playing neural nets rely purely on simple heuristics? Or do they implement algorithms involving *look-ahead* in a single forward pass?
We find clear evidence of 2-turn look-ahead in a chess-playing network, using techniques from mechanistic interpretability! 🧵
My first PhD paper!🎉We learn *diffusion* models for code generation that learn to directly *edit* syntax trees of programs. The result is a system that can incrementally write code, see the execution output, and debug it. 🧵1/n
@GoogleDeepMind@mmmbchang Or get Astra to display its output as text on a screen, record the screen, and ask Astra about the recording of itself speaking in real time.
WE NEED TO GO DEEPER!
@GoogleDeepMind@mmmbchang Actually, no better: set up a camera pointing at the back of your head, then ask Astra "do you know what this video is about?" and see how long it takes to figure out that the video is of you interacting with it.
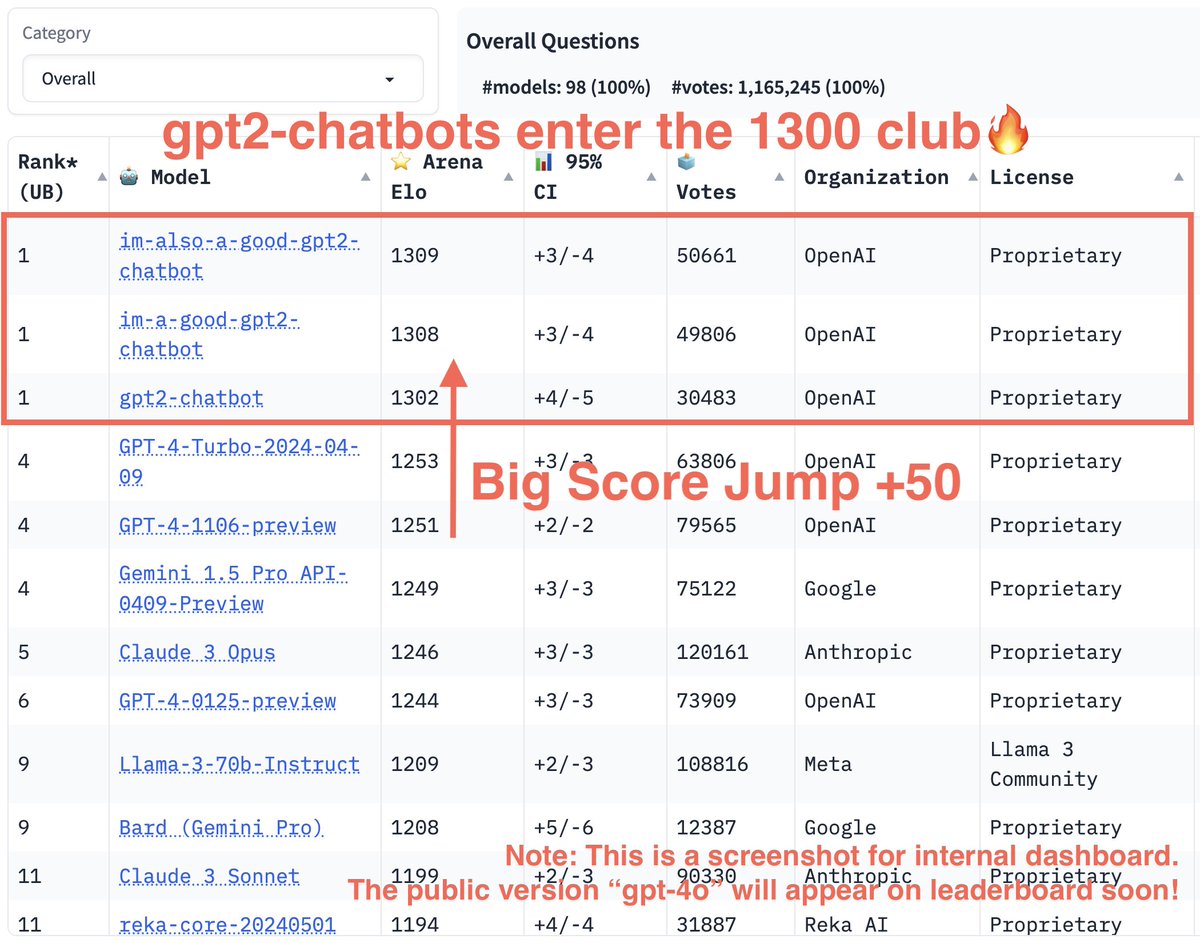
Breaking news — gpt2-chatbots result is now out!
gpt2-chatbots have just surged to the top, surpassing all the models by a significant gap (~50 Elo). It has become the strongest model ever in the Arena!
With improvement across all boards, especially reasoning & coding capabilities, we're excited to see what app can build on top.
Huge congrats to @OpenAI for this incredible milestone!
Note: this is an internal screenshot. Its public version "gpt-4o" is now in Arena and will soon appear on the public leaderboard!
My university requires you to file your PhD thesis through a 3rd party (@ProQuest) that charges $95 if you want to let people outside wealthy first-world universities read it. $95 to host a PDF is a rort, and sadly this will keep happening unless universities fight back.
The deep RL world focuses too much on algorithms and not enough on understanding its own benchmarks. What makes an algorithm do well or poorly on a given environment? Is it actually measuring what we want to measure? Cassidy's work does a great job of answering these questions.
Last year we showed that deep RL performance in many *deterministic* environments can be explained by a property we call the effective horizon. In a new paper to be presented at @iclr_conf we show that the same property explains deep RL in *stochastic* environments as well! 🧵
Introducing the Instruction Hierarchy, our latest safety research to advance robustness for prompt injections and other ways of tricking LLMs into executing unsafe actions. More details: https://t.co/cUZaaMRdEG
@thegautamkamath I'd love to see an experiment where they get high schoolers to write reviews and then compare them against the quality of the average review. I'm genuinely unsure whether the high schoolers would end up above or below the mean!