✨ Introducing Audioflare ✨
The ultimate open source playground to master @Cloudflare AI Workers.
Audioflare transcribes, summarizes, analyzes, and translates 30-second audio clips into 9 languages.
#buildinpublic
Supabase has raised $500M at a $10B valuation
In this round we are giving @supabase employees the opportunity to cash out 25% of their vested options. We have done this in every round since inception.
We do it as a “cashless transaction” so that employees don’t need to front any cash to exercise their options. This is the friendliest way we could design it until we can offer RSUs.
On top of that, we give employees a 10 year exercise window: whether they stay or leave the company. The typical/default window is 3 months. IMO, equity is earned and employees shouldn't be penalized because they don't have the cash to exercise within 3 months of leaving a job (often that's the time they need the cash/certainty the most).
Agents now deploy the majority of databases on Supabase. Claude Code is our single biggest contributor since January.
That sentence would've sounded made up a year ago.
Today it's part of why we raised $500M at a $10.5B valuation. Databases up 600% YoY.
Still early. https://t.co/IUkMDj26UF
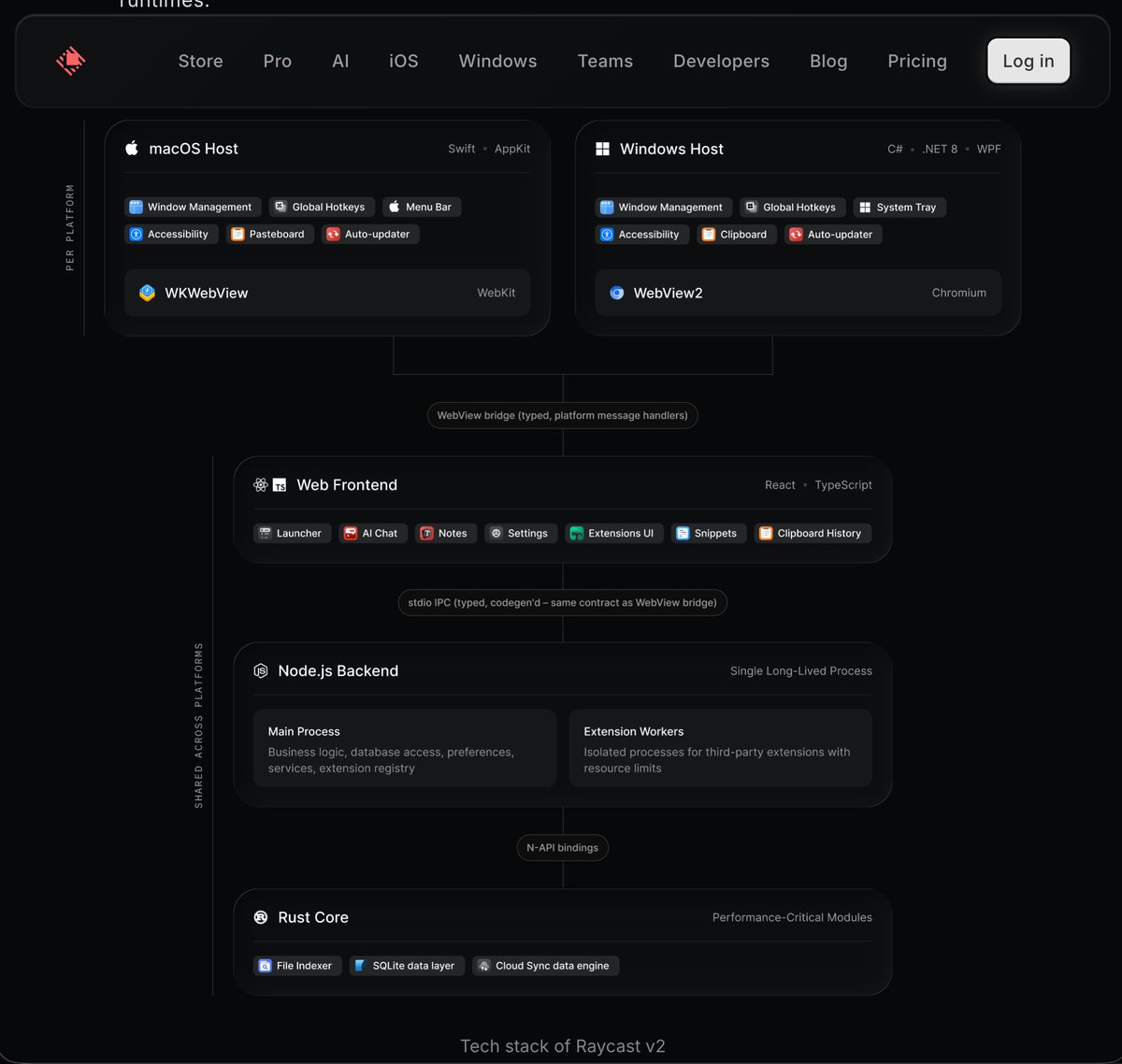
beautiful tech stack writeup, one of the best i've ever seen in my career.
I always advocate that devtools companies write these up, because it fulfils multiple purposes:
- tell users the care that goes into the product
- tell hires that there's SOTA work here
- tell competitors to give up
- gives back to community
- (nuanced) tell non-fits why they can't have what they want when they think it's an easy request
few actually do this mostly because they don't actually have sufficient depth, or aren't sufficiently good at notetaking/systematic about problemsolving ('its just vibes' or 'honestly we just went with the first thing that worked' doesn't come across as well, so rather not say anything)
so when you've done the work, show the work.
bravo Raycast
Raycast 2 is built on React?!
Been using Raycast 2.0 for a few days and its noticeably very snappy
Today I was shocked to see they have built it with Web Views and a Node.js backend. You know I had to crack it open.
Light native wrapper. Rust where it matters. No electron of Tauri.
Google is spending billions building @GeminiApp into search.
I'm looking at movie showtimes. There are 11 screen formats. 3D 4DX. DBOX XD. 3D DBOX XD. Barco PX RPX.
Zero explanations. Not even a tooltip.
I don't need AI to summarize Reddit threads. I need it to tell me what the hell DBOX XD is and whether it's worth $8 more than DBOX.
Been doing this for a while without realizing what it was.
Repos for my kids, family docs, finance stuff, medical records. Just trying to keep life from being a mess. Making it all searchable and maintained.
Karpathy nailed it. The second brain dream always had this fatal flaw: documenting your life takes more time than living it.
LLMs finally flip that. The tool actually matches the ambition now.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Você sabia que, embora o destino seja o mesmo, a trajetória para chegar até lá evoluiu muito? No vídeo, podemos ver a diferença visual entre as estratégias de voo:
• Apollo 8 (1968): A primeira missão tripulada a orbitar a Lua utilizou uma trajetória de aproximação direta para entrar em órbita lunar. A nave permaneceu relativamente próxima da superfície, em uma órbita baixa, ajudando a preparar o caminho para os pousos que viriam depois.
• Artemis I (2022): Já a missão Artemis utilizou uma Órbita Retrógrada Distante (DRO). Como mostra o gráfico, a nave Orion viajou muito mais longe da Lua, testando os limites de distância para missões tripuladas e aproveitando uma órbita gravitacionalmente estável, ideal para missões de longa duração.
Essas trajetórias não são apenas desenhos no espaço; elas representam um salto tecnológico. Saímos de missões de exploração mais curtas para a preparação de uma presença sustentável na Lua com o Programa Artemis.
Qual dessas trajetórias você achou mais impressionante: a precisão da Apollo ou a amplitude da Artemis?
The coolest orbital animation I've seen of Artemis 2
Just really shows you how far away they're flying today and also how precise they need to be to go to the moon
We spent 30 years building GUIs to escape the terminal.
Now the terminal has mouse events, smooth animations, and better UX than half the web apps I use.
Somewhere a 1995 Unix admin is having an existential crisis.
Today we're excited to announce NO_FLICKER mode for Claude Code in the terminal
It uses an experimental new renderer that we're excited about. The renderer is early and has tradeoffs, but already we've found that most internal users prefer it over the old renderer. It also supports mouse events (yes, in a terminal).
Try it: CLAUDE_CODE_NO_FLICKER=1 claude
Introducing https://t.co/HWOqXPqpgM: Supabase docs over SSH
Give your agents direct bash access to @supabase docs so that they can explore them the same way they do with code
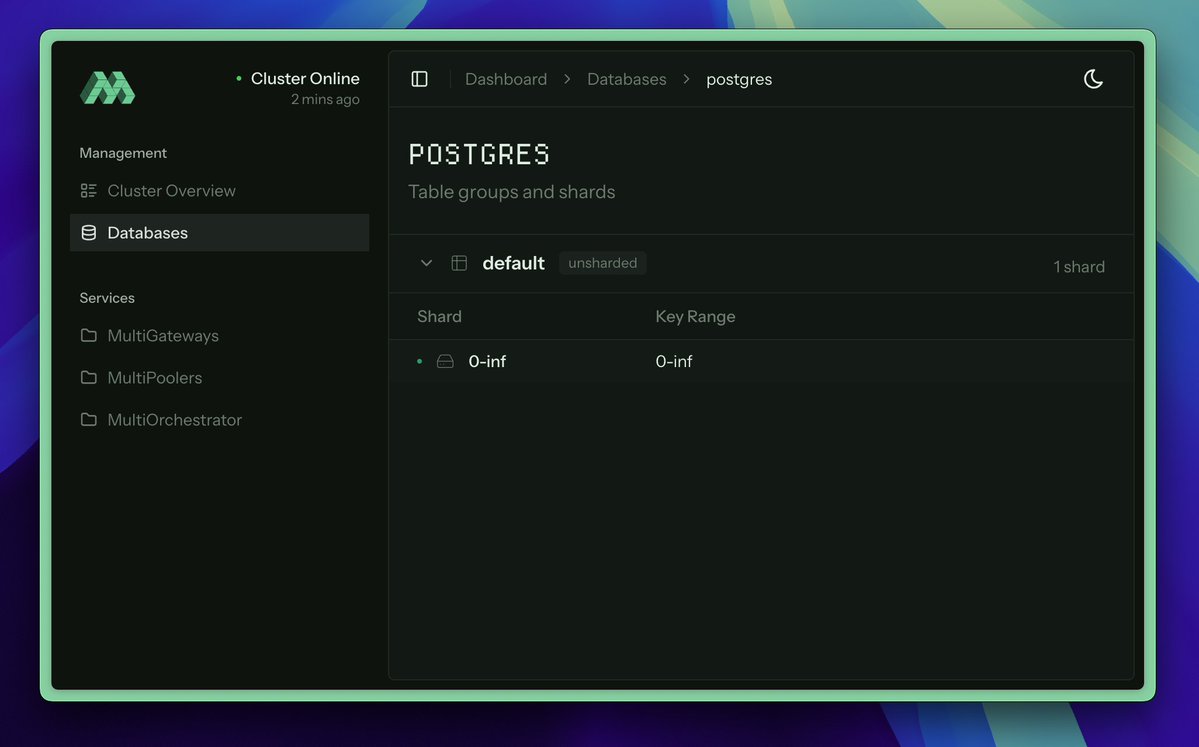
the @multigres operator is now open source
progress so far:
◆ Direct pod management
◆ Zero-downtime rolling upgrades
◆ pgBackRest PITR backups
◆ Observability with OTel tracing
link to repo in thread
Claude Code leaked their source map, effectively giving you a look into the codebase.
I immediately went for the one thing that mattered: spinner verbs
There are 187