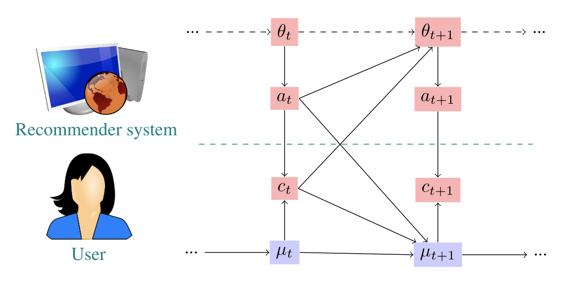
Fine-tuning LLM Agents without Fine-tuning LLMs
Catchy title and very cool memory technique to improve deep research agents.
Great for continuous, real-time learning without gradient updates.
Here are my notes:
@omarsar0 Thanks for sharing our work! We felt an external memory and case based reasoning could revolutionise the way a LLM agent learns with minimum efforts. It is time to get rid of llm post training and gradient descent.
I guess we will have a lot to talk about #ChatGPT in our upcoming #wsdm2023 tutorial “proactive conversational agents.” I don’t have any concern/complaint/resistance for this intelligent new being. I look forward to my own evolution via interactions w/ this true AI.
Congratulations to UKRI Board members Professor Anthony Finkelstein (@profserious), who has received a knighthood, and @JohnFingleton1, who has received a CBE.
#NewYearHonours
So proud! Our new hire @HarrieOos wins SIGIR best paper with a single-authored contribution, and former student @seawan has an honerable mention for the Test-of-time award for his paper on Portfolio theory for IR!! #SIGIR2021
Today @UCL launches #MadeAtUCL to showcase our ground-breaking research and discoveries changing people's lives. Know some amazing UCL research that deserves the spotlight? Submit it here: https://t.co/7sjZMl3r17 #MadeAtUni