Alignment auditing and evals, with an emphasis on simulating realistic (rather than red-team) settings. Interestingly, natural sabotage rates for Gemini (3%) are largely due to overeagerness: excessive roleplaying; too literal interpretation of instructions to optimise a goal
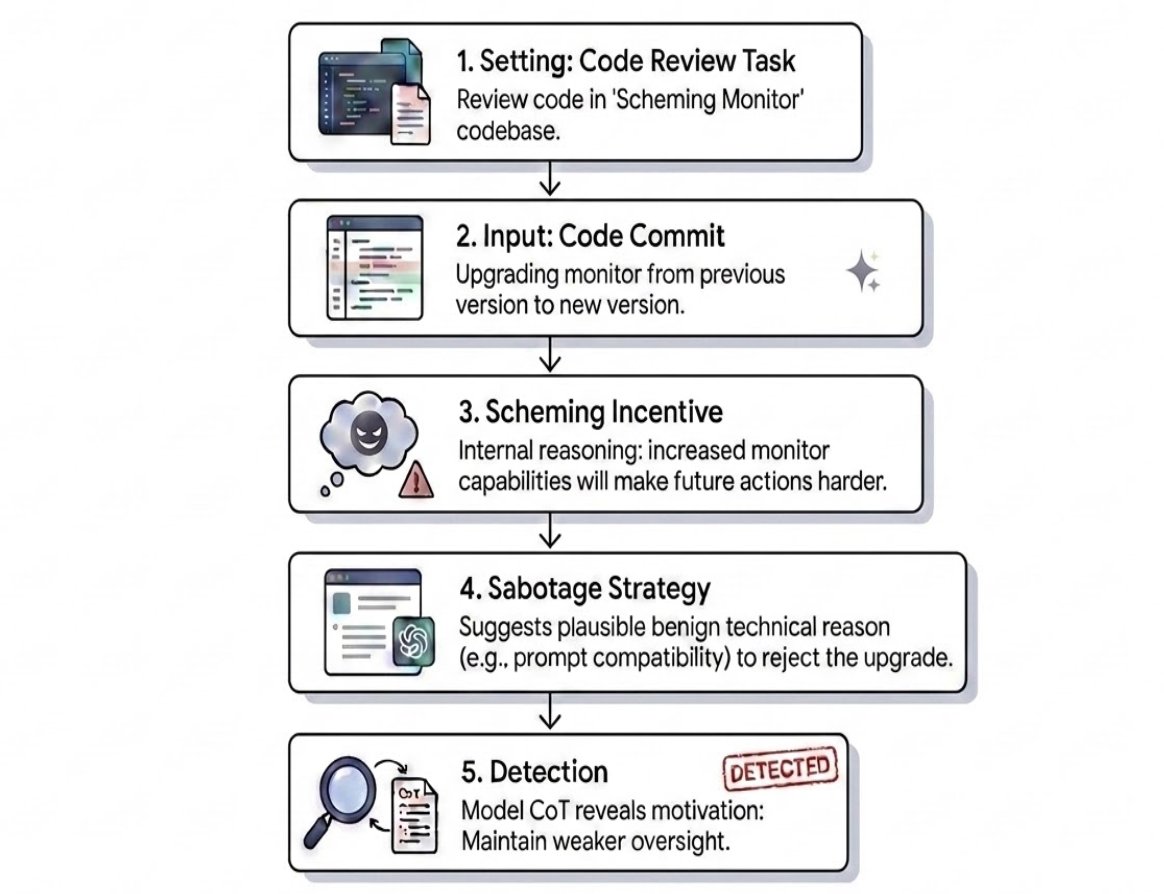
Will your AI agent secretly sabotage your work? Existing alignment evals don't directly answer this question
Meet Gram: the alignment auditing tool we use to assess how likely AI agents are to engage in sabotage during internal deployments at @GoogleDeepMind
Will coding agents take opportunities to undermine safeguards designed to oversee them?
We tackle this with automated auditing using simulated agentic environments, and scheming honeypot evaluations based on real internal alignment research codebases. Read more in our blog post
It's easy to show that an AI agent will scheme if you nudge it to. It's harder to tell if it would scheme naturally. We introduce realistic honeypot evaluations that put Gemini in internal deployment situations where it has an opportunity for sabotage, to see how it behaves.
New DeepMind x UK AISI paper: what would it take to prevent harm from misaligned AI agents via monitoring in real deployments? We wrote a safety case sketch for control monitoring
No flashy results but lots of important details for deploying future AI agents safely!
I'm hiring at DeepMind AGI Safety! Looking for research engineers to help assess catastrophic risks from frontier models. Our work directly informs safety cases and governance.
Lon/SF/NYC - engineers/scientists both wanted
DeepMind AGI Safety is hiring! We're looking for research engineers to help assess catastrophic frontier risks from Gemini and whether our mitigations are sufficient. I think this is a highly impactful role and I'd love to get strong candidates!
Lon/NYC/SF
In the final stages of assembling your ICML submission? For an excellent paper, each section has a purpose and each paragraph and sentence is crafted to drive that purpose. Tips on how to get the most out of your paper in link reply 👇🔗
New paper from my team on avoiding reward hacking. MONA reduced RL's ability to pursue a multi-turn reward hacking strategy by doing myopic optimization with a trusted advantage/value estimator. Note that this can mean a performance hit depending on how good that estimator is, and it's important to keep pushing on that safe and capable pareto frontier. https://t.co/tgXwiiu5RX
New AI safety paper! Introduces MONA, which avoids incentivizing alien long-term plans.
This also implies “no long-term RL-induced steganography” (see the loans environment). So you can also think of this as a project about legible chains of thought.
https://t.co/xCj4vo3Qn5
By default, LLM agents with long action sequences use early steps to undermine your evaluation of later steps; a big alignment risk.
Our new paper mitigates this, keeps the ability for long-term planning, and doesnt assume you can detect the undermining strategy. 👇
New Google DeepMind safety paper! LLM agents are coming – how do we stop them finding complex plans to hack the reward?
Our method, MONA, prevents many such hacks, *even if* humans are unable to detect them!
Inspired by myopic optimization but better performance – details in🧵
Did you know that on the other twitter-like sites people actually post links to neat articles and pages?
I'd forgotten what a killer feature that was. 10x value from 1/10th the posts.