@mbateman "What?" sounds fine to me, though "what was that?" is a bit clearer and more polite. I hardly ever hear anyone say "beg your pardon?" or "excuse me?" but if they did I might think they're offended by whatever I said
@karlbykarlsmith@AnthropicAI From the blog post:
> To us, the most interesting part of the result isn't that the model eventually identifies the injected concept, but rather that the model correctly notices something unusual is happening before it starts talking about the concept.
@simonw Back when Sora was first announced, I wrote a similar post about how zero-shot video models could play video games or operate robots: https://t.co/tMTe1z9421
@GergelyOrosz Not necessarily the "next token that will have the best result" either. The point was that tokens are randomly sampled, so you might get e.g. the fourth-best token instead. Although these details are admittedly not that important to your original point
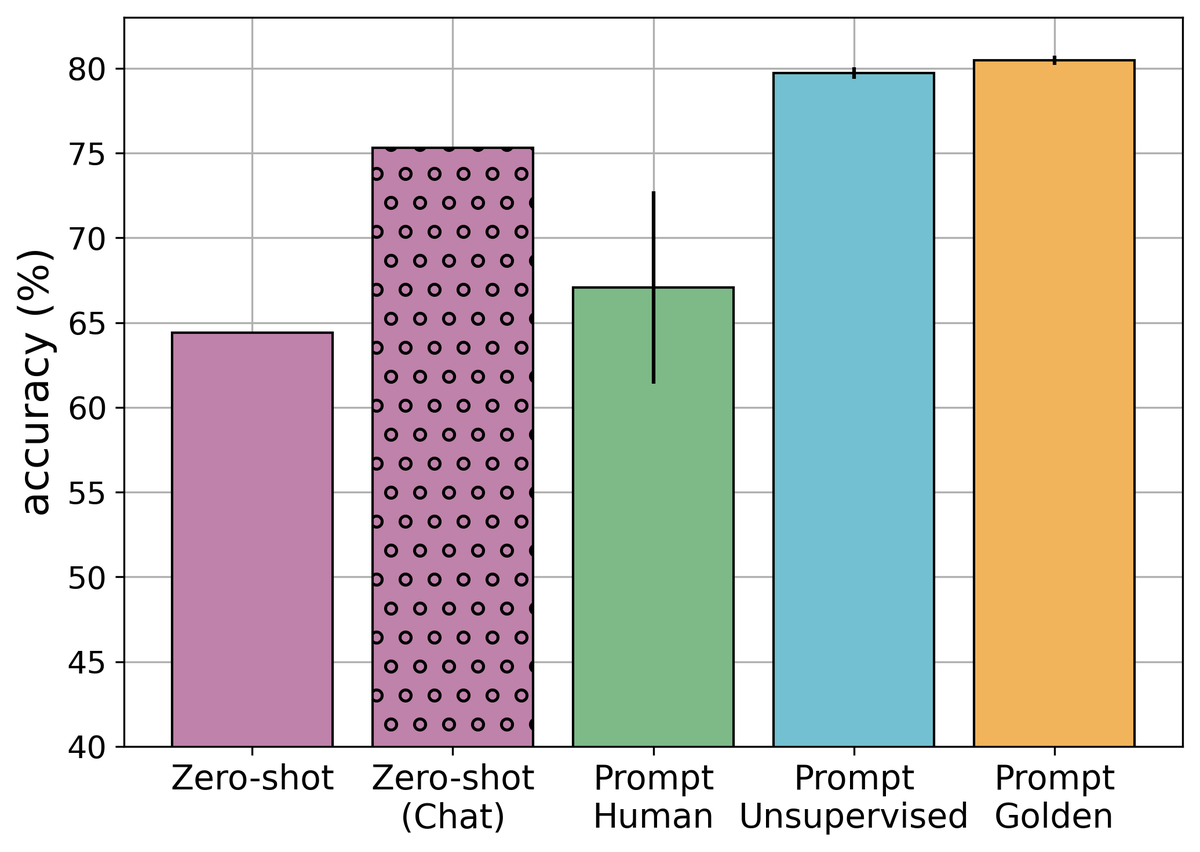
@jxmnop@askerlee Base models are generally better at predicting author demographics. You could use the Blog Authorship Corpus to predict gender, like in this Anthropic paper: https://t.co/c3XWcCFD8f. The relevant comparison would be "Zero-shot (Chat)" vs. "Prompt Golden" (i.e. few-shot examples)
@karpathy I've been working on a similar idea. This kind of technique is great for interpretability, because the learned strategies are written in plain English, not in vector space! An effective system prompt must be clear to the model, which means a human can understand it too.
@NotBrain4brain@NotBrain4brain Someone tried asking GPT-4.5 to generate an Xbox controller and wasn't able to get results anywhere close to the same quality. What's going on, is the mystery model not GPT-4.5?
@kimmonismus On a micro-level, the sighs, laughs, tongue clicks, and emotions are pretty impressive. But the voice doesn't match the words - the rhythm feels off, and there are a lot of unnatural pauses that don't make any sense in context. I think OpenAI voice mode is a bit better here
@roydanroy@jiayi_pirate It's searching in the sense that it's trying out different options that come to mind and finding the one that works. It doesn't have to follow a specific algorithm
New Google DeepMind safety paper! LLM agents are coming – how do we stop them finding complex plans to hack the reward?
Our method, MONA, prevents many such hacks, *even if* humans are unable to detect them!
Inspired by myopic optimization but better performance – details in🧵
@RileyRalmuto@AlwaysUhhJustin@sama Do you have any other details about how they "assessed" the drug? Seems like a very quick turnaround time, depending on how long ago the drug design was created.
I made this Manifold market about your tweet, and the question of testing came up: https://t.co/DAG902Uj8f