¡Se mueve la Sala Const TSJ! trámite nueva causa de divorcio por factor económico y modalidades. ejemplo: hombres que no les gusta trabajar y pretenden que los mantengan. Si tienes interés legítimo, actúa como tercero (Art. 370, ord. 3 CPC). Exp. 2026-0059.! #DivorcioVenezuela
Instead of two hours of Netflix, watch this four-hour course.
The clearest and most detailed online guide about Claude I've ever seen.
Save this page before you forget it.
Build tools.
Automate your work.
Learn how to create bots and systems.
Anthropic publicó un taller gratuito de 26 minutos para aprender a hacer prompts de verdad.
> sin registro.
> sin muro de pago.
> impartido por quienes lo construyeron.
🔖 guárdalo, vale la pena.
el ingeniero que construyó Claude Code acaba de publicar un video de 28 minutos sobre cómo escribir prompts que realmente funcionan
he visto cursos de 300$ que no cubren lo que él muestra en los primeros 10 minutos
archivos CLAUDE.md, atajos de memoria, sesiones paralelas, patrones de prompting
todo en un video y completamente gratis
funciona seas desarrollador, principiante o alguien que lleva meses usando Claude
Una psicóloga de Stanford dedicó cuatro años a demostrar que el simple acto de caminar genera un 60 % más de ideas creativas que estar sentado, y el experimento que diseñó para descartar cualquier explicación alternativa es uno de los hallazgos más decisivos de la psicología moderna.
Su nombre es Marily Oppezzo.
La idea para el estudio surgió mientras caminaba con su tutor en Stanford para discutir el tema de su tesis, y el artículo que finalmente publicó en el Journal of Experimental Psychology en 2014 es tan contundente que debería haber puesto fin a la reunión el mismo día de su publicación.
Realizó cuatro experimentos con 176 personas. Cada persona fue evaluada dos veces: una sentada y otra caminando. Las tareas de creatividad fueron las estándar que los psicólogos han utilizado durante décadas para medir la capacidad del cerebro para generar ideas novedosas y útiles.
El resultado fue tan claro que casi no merecía ser publicado.
El 81 % de los participantes en el primer experimento generó más ideas creativas caminando que sentados. En el segundo, el 88 %. En el tercero, el 100 %. Cada persona, al caminar, se convirtió en una versión más creativa de sí misma.
En promedio, las personas generaron un 60% más de ideas novedosas y útiles en el momento en que comenzaron a mover las piernas.
La pregunta escéptica es obvia. ¿Quizás fue el aire fresco?¿Quizás fue el paisaje que pasaba?¿Quizás fue el cambio de entorno el que hizo el trabajo, no la caminata en sí?
Oppezzo desmintió todas esas explicaciones con una decisión experimental.
Colocó a los participantes en una cinta de correr frente a una pared blanca. Sin paisaje. Sin aire fresco. Sin cambio de entorno. Solo piernas moviéndose en el sitio mientras miraban fijamente una pared blanca. El aumento del 60% se mantuvo.
Luego realizó el experimento que zanjó el asunto por completo. Sacó a los participantes al exterior en dos condiciones. La mitad caminó por un patio de Stanford. La otra mitad fue empujada por el mismo patio en silla de ruedas. La misma estimulación al aire libre. El mismo paisaje pasando a la misma velocidad. La única diferencia era si las piernas se movían o no.
Los que caminaron produjeron muchísimas más ideas novedosas y de alta calidad que el grupo en silla de ruedas. El exterior por sí solo no tuvo casi ningún efecto. Caminar lo hizo todo.
Esta es la parte del estudio que más me impactó la primera vez que la leí.
También puso a prueba el tipo de pensamiento opuesto: el pensamiento convergente. Ese en el que hay una única respuesta correcta y hay que reducir las opciones hasta encontrarla.
Se trataba de crucigramas donde tres palabras compartían una cuarta palabra oculta que las conectaba. Los participantes sentados obtuvieron mejores resultados, mientras que los que caminaban obtuvieron peores.
Caminar no mejora la inteligencia en general. Tiene un efecto específico: activa la búsqueda divergente en el cerebro, la que genera opciones, la que produce conexiones inesperadas, la que toma un problema y encuentra cinco maneras de resolverlo en lugar de una.
Cuando necesites converger en la única respuesta correcta, siéntate. Cuando necesites encontrar la respuesta, levántate.
El mecanismo ahora se comprende bien.
Caminar activa selectivamente lo que los neurocientíficos llaman la red neuronal por defecto (RND), el sistema cerebral que se activa cuando no estás concentrado conscientemente en nada. La RND es donde se produce la divagación mental, donde los recuerdos se interrelacionan. Donde las ideas que han estado guardadas en carpetas separadas en tu cabeza finalmente se encuentran.
Cuando te sientas en un escritorio y te obligas a concentrarte, suprimes la red neuronal por defecto (DMN). Cuando caminas a un ritmo natural, la parte ejecutiva de tu cerebro se ocupa lo suficiente de la caminata como para que la DMN se active y comience a realizar el trabajo que la concentración estaba bloqueando.
El hallazgo más útil de todo el estudio es el que casi nadie cita.
El impulso no desapareció en el momento en que las personas dejaron de caminar. Los participantes que caminaron primero y luego se sentaron mantuvieron el estado de alerta. Su siguiente ronda de trabajo creativo sentado fue significativamente mejor que la de quienes habían estado sentados todo el tiempo. El efecto perduró durante al menos varios minutos después de que las piernas dejaron de moverse.
No necesitas realizar trabajo creativo mientras caminas. Necesitas caminar antes del trabajo creativo. El cerebro mantiene el estado.
La historia de esto es lo que debería preocupar a cualquiera que todavía celebre reuniones sentado.
Charles Darwin construyó un sendero circular de grava detrás de su casa en Kent, llamado Sandwalk, y lo recorrió tres veces al día durante el resto de su vida. La teoría de la evolución se desarrolló dando vueltas a ese sendero.
Nietzsche caminaba hasta diez horas diarias durante los años en que escribió sus libros más importantes y afirmaba abiertamente que la obra se concebía mientras caminaba.
Beethoven componía por la mañana y caminaba cinco horas cada tarde con un lápiz en el bolsillo por si le llegaba alguna idea.
Kahneman decía que las mejores ideas de su carrera, que le valió el Premio Nobel, surgieron durante paseos tranquilos con Amos Tversky. Steve Jobs se negaba a tener conversaciones importantes sentado; las mantenía caminando.
Todos ellos utilizaban el sistema que Oppezzo no mediría hasta 2014. Simplemente no sabían cómo llamarlo.
La pregunta que vale la pena plantearse es la que casi nadie se hace.
Cada reunión a la que has asistido sentado alrededor de una mesa se desarrolló con una fracción de la capacidad intelectual real de los presentes.
Cada lluvia de ideas que se quedó estancada en una sala de conferencias.
Cada problema que intentaste resolver en tu escritorio y abandonaste.
Cada idea que no lograste concretar.
La intervención es la más sencilla de la ciencia moderna. Sin suplementos. Sin aplicaciones. Sin suscripciones. Sin programas de entrenamiento. Solo un par de piernas y 15 minutos.
El laboratorio de Stanford lo demostró. Los filósofos lo sabían. La neurociencia lo explica.
Y casi todos los que leen esto siguen intentando resolver problemas sin moverse.
desde que vi este documental no puedo dejar de pensar en lo mal que tenes que estar mentalmente como para subir tiktok bailando disfrazada de ESQUELETO no habían pasado ni dos meses de lo que hizo
En lugar de ver una hora de Netflix, mira esta conferencia de 2 horas de Stanford que te enseñará más sobre cómo se construyen los LLMs como ChatGPT y Claude que lo que la mayoría de personas trabajando en las mejores empresas de IA aprenden en toda su carrera.
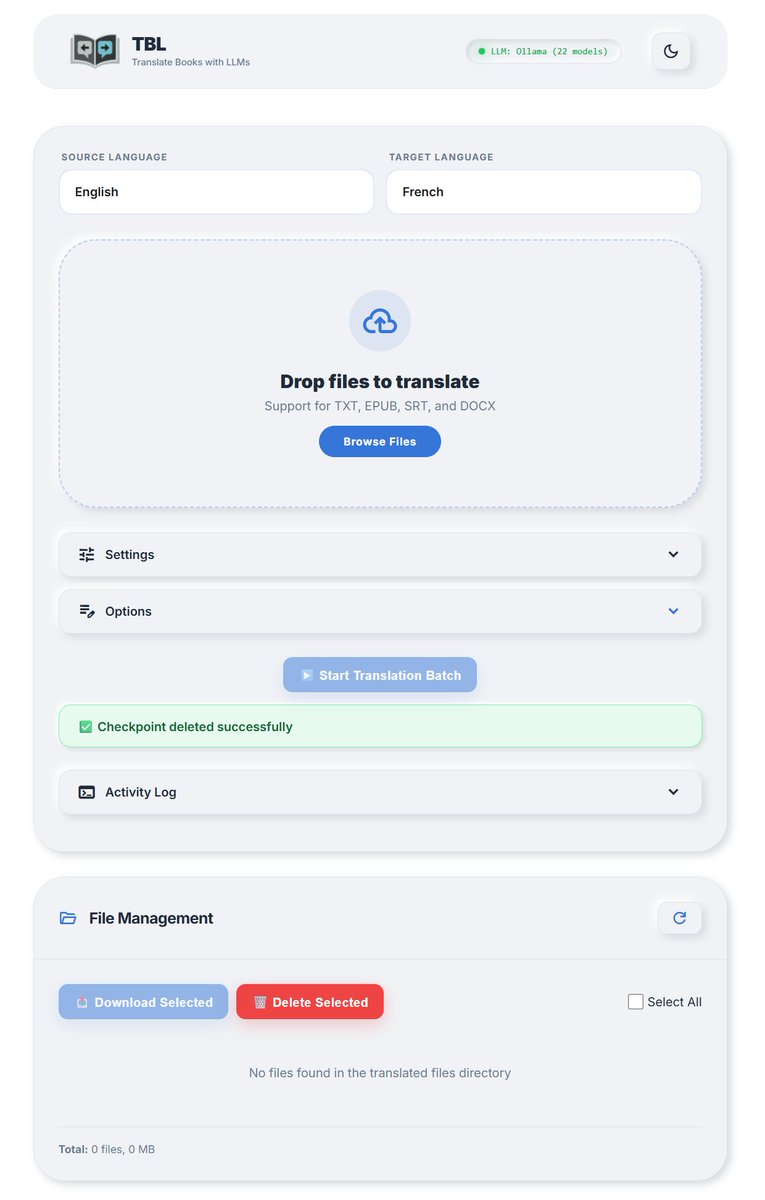
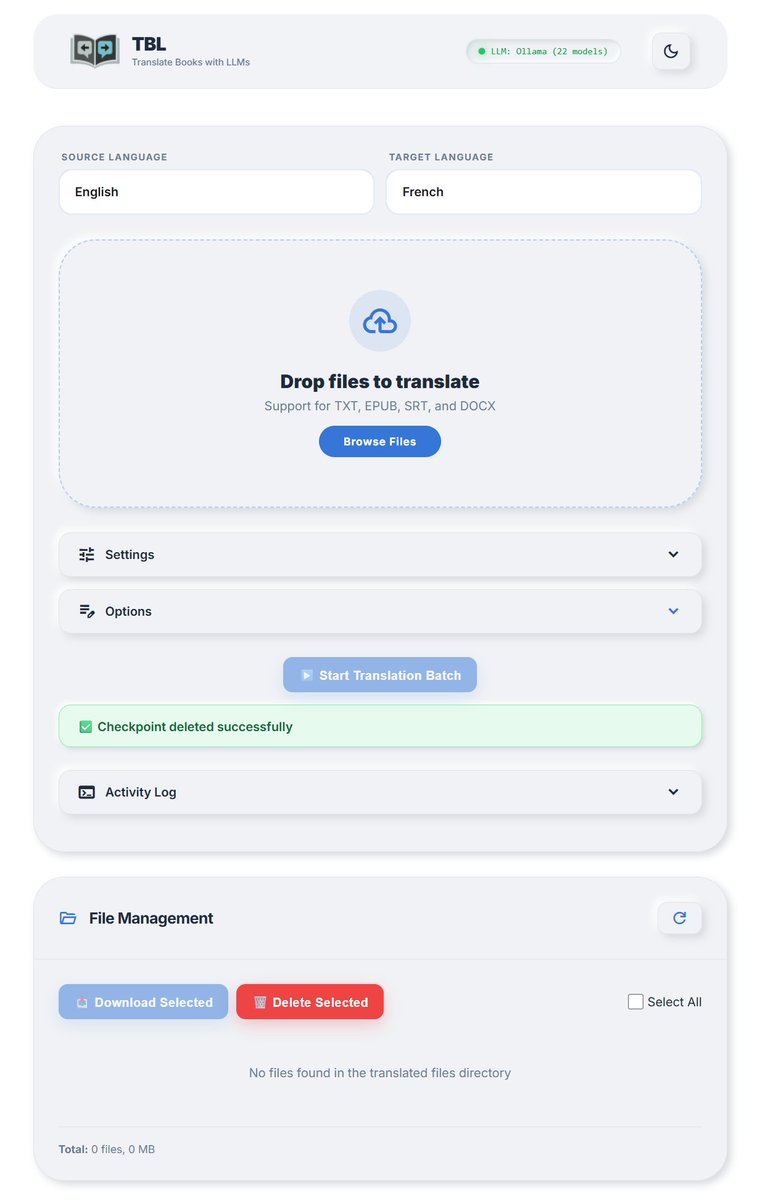
Traduce un libro COMPLETO de 350 páginas con IA… y sí, queda igual o MEJOR que muchas traducciones profesionales.
Olvídate de Google Translate que destroza el estilo y el formato.
Con este repo open source traduces libros enteros, subtítulos y documentos usando LLMs reales:
✅ Ollama (gratis y local)
✅ Gemini, OpenAI, Mistral, etc. (baratísimo, ~1-2 € por libro)
✅ Sin límite de tamaño
✅ Mantiene el formato EPUB perfecto
✅ Reanuda si se interrumpe
¿Quieres leer ese bestseller en inglés… pero en español de verdad?
Esto es lo que necesitas :)
REPOOO👇
disculpen, esto es lo más sexy que he leído en mucho tiempo. increíble. una obra literaria.
no hay nada que me parezca más atractivo que una mente dispuesta a fallar en pro de aprender y descubrir. su deseo de expansión es más grande que su necesidad de tener la razón.
📊 Qué es un pipeline de datos y por qué dominar arquitectura de datos con microservicios cloud es fundamental en la era de AI & Big Data?
Primero vamos con las definiciones: un pipeline de datos, tal como lo indica su nombre, es una "tubería" por donde pasan los datos desde su origen hasta que llegan al usuario final listo para consumir como información valiosa.
Y los servicios cloud? Es la infraestructura en la nube que se usa para que todo esto funcione, donde se ingestan, procesan, almacenan y consumen todos estos datos.
Hoy existen tres jugadores principales en la industria de cloud services:
🟠 AWS de Amazon
🔵 Azure de Microsoft
🟢 GCP de Google
Son quienes proveen todos estos servicios utilizando data centers, grandes centros de datos donde se concentra todo el poder de computación para que cada cliente pueda desarrollar sus soluciones tecnológicas.
Para poner a funcionar una solución de datos, sea en batch o real time, primero es necesario diseñar una correcta arquitectura de datos que cumpla con la necesidad y esté preparada para escalar cuando el volumen/velocidad de los datos se incrementen.
Normalmente una arquitectura de datos se divide en varias secciones:
Orígenes → Ingesta → Procesamiento/Storage → Consumo
1⃣ Los datos pueden generarse de diversas formas, dentro de un sistema empresarial como un ERP/CRM o desde un sensor cómo sucede en un fábrica o un auto de F1.
2⃣ La ingesta es la etapa en la cual esos datos salen desde sus sistemas de origen o sensores y se ingestan/ingresan en la nube, quedando dentro del ecosistema cloud.
Para el caso de IIot se utilizan microservicios tales como AWS IoT Core, AWS SiteWise y Amazon Kinesis.
3⃣ Procesamiento y Storage, los datos deben ser procesados y almacenados.
Para esta etapa, normalmente se diseña un Data Lake que divide los datos en 3 capas:
🥉 Raw/Bronce: datos crudos/landing zone
🥈 Cleansed/Silver: datos limpios, validados y normalizados
🥇 Curated/Gold: datos con lógica de negocios y KPIs calculados
Para pasar desde la capa raw hacía la capa gold se van realizando distintas transformaciones (ETL jobs) usando, por ejemplo, un microservicios como AWS Glue.
Para cada capa de datos dentro del data lake se utilizan distintos buckets de S3 (contenedores), normalmente en formato parquet para comprimir el contenido y bajar el costos de almacenamiento de la data.
Sobre la etapa final, se utilizan servicios como Amazon Redshift o Amazon Athena donde se trabaja con data estructurada, agregándole valor para que esa data se convierta en información valiosa para el cliente/usuario final.
Si el producto o solución de datos incluye modelos de machine learning se deben agregar algunos pasos más:
Debemos trabajar la data del data lake haciendo transformaciones para lograr las tablas que actuarán como un set de entrenamiento para el modelo de ML.
Acá vamos a agregar microservicios como Amazon SageMaker para construir, entrenar y desplegar los modelos de machine learning.
También se utilizan bases de datos como Amazon RDS con PostgreSQL para almacenar resultados operativos del modelo, como scores, alertas, predicciones o recomendaciones.
4⃣ El consumo de estos datos son la etapa final del pipeline, donde entran productos de BI (business intelligence) tales como Power Bi, Tableau o Amazon QuickSight.
Acá es donde el cliente final pueda ver los datos, navegarlos y consumirlos a demanda o recibir alertas en tiempo real.
El análisis y las visualizaciones es la porción final de todo el desarrollo de un pipeline de datos, pero no menos importante, ya que acá es donde el cliente percibe el valor de todo del desarrollo.
Por eso es tan importante diseñar bien no solo la arquitectura técnica, sino también la experiencia de usuario: UX/UI, diseño visual, navegación, performance y claridad de los indicadores.
Además de todos estos servicios, dentro de un pipeline también entran en juego otros componentes fundamentales: roles, accesos, ciberseguridad, versionado, monitoreo, logs de funcionamiento y orquestadores.
Todo esto debe estar cubierto para que el pipeline funcione correctamente, sea seguro, mantenible, accesible y escalable a futuro.
💵 Por toda esta complejidad, los roles de cloud architect, data architect, data engineer y data scientist están entre los mejor pagos y más demandados dentro de la industria tech.
Porque son quienes diseñan, desarrollan, operan y mantienen los pipelines que permiten que una empresa pueda tomar decisiones basadas en datos confiables.
Sea una fábrica, un barco, una empresa de energía o un auto de F1:
TODOS necesitan datos de calidad para operar mejor, reducir costos, anticipar problemas y tomar mejores decisiones.
🚨 ULTIMA HORA: ESTE TIPO CREÓ UN PROFESOR IA QUE VIVE AL LADO DE TU CURSOR.
Ve tu pantalla, te habla y señala exactamente lo que tienes que aprender. Lo usó para dominar Davinci Resolve en días. 10/10.
Se llama Clicky. Y acaba de matar los tutoriales.
LAS MEJORES PÁGINAS PARA ENCONTRAR TRABAJO! 🫵🏼
(Guardarlo quel lo necesitarás)
ESPAÑA
· malt․es
· joppy․me
· infojobs․net
· getmanfred․com
LATAM
· latam․jobs
· revelo․com
· getonbrd․com
· prosmarketplace․com
RESTO DEL MUNDO
· otta․com
· remote․io
· remoteok․io
· flexjobs․com
si quieren leer algo tipo BRIDGERTONE pero con FANTASÍA les recomiendo un LIBRO donde a ella un hada le roba la mitad de su alma por lo que ahora no siente algunas emociones entonces su prima decide pedirle ayuda al hechicero real a quien todos consideran un gruñón maleducado+