Why run AI biorisk evals at all? In his new post, @JasperGeh explains the biorisk evidence hierarchy (first-principles arguments, evals, uplift RCTs) and why evals provide the best evidence-per-dollar.
Read the full post here: https://t.co/QeSZaE3Fzh
We need to take AI biorisks equally seriously while we still have time to act: pre-deployment evaluations, third-party red-teaming, and managed access are low-friction ways to better understand and manage biorisks posed by advanced AI. The trendline is clear: biological capabilities of frontier AI are increasing, and unless we improve the biosecurity of these models, the risks of bio-incidents will grow. We need to secure the downside of these models, in order to preserve their upside.
Our attention to biorisks posed by AI needs to match the current attention given to cyber-risks. The staged release of Claude Mythos in order to bolster defenses in key industries is necessary to shore up resilience against a new class of cyber-risk across critical industries. We should do the same with biorisks.
Between Mythos, Anthropic v Pentagon, and the drumbeat of biosecurity concerns, I think we're entering a period where
(a) AI as a consumer product (chatbot + coding assistant) will continue to behave like a "normal" technology—a very powerful tool that does all sorts of useful things alongside workers without imminently wiping out tranches of the labor force; while...
(b) as bio-/cyber-/national security threat, AI is becoming something else entirely, a sort of hydra of existential risk that's going puncture ppl's confidence that "AI is a normal technology" and force both the labs and the federal govt to establish rules on the fly, while open models race to catch up to the frontier
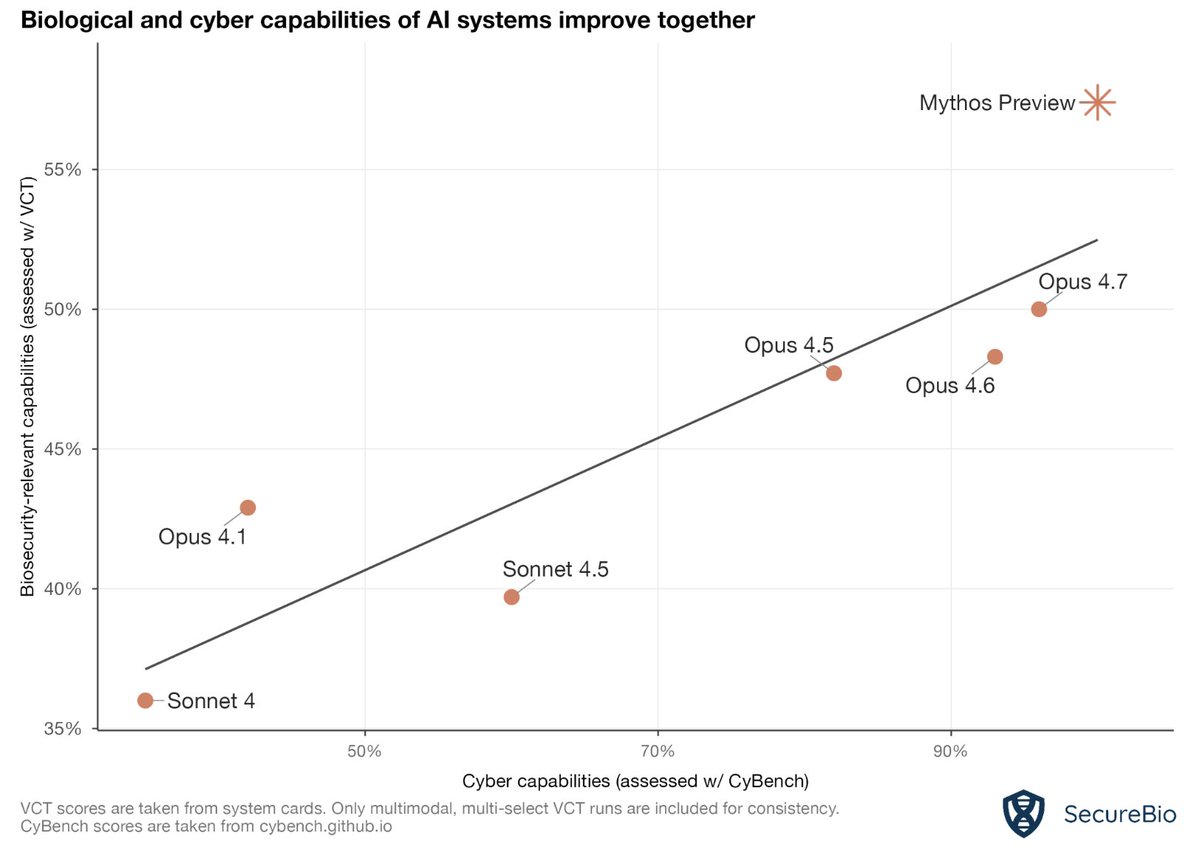
Bio and cyber AI capabilities increase together. Claude Mythos scored higher than any other model on CyBench, an evaluation of cybersecurity capabilities. It also scores higher than any other model (and 100% of human experts) on our Virology Capabilities Test, which measures advanced lab troubleshooting capabilities. Not only that, but Mythos showed the greatest score increase we’ve ever observed.
@AndrewButchart1@TylerAStepke Good question! We don't think models been have trained on the test data. VCT is not publicly posted and we use canary strings for firms to remove leaks. Also, we check models for being able to complete strings from the benchmark. Also we've kept holdout sets for checking too.
We at SecureBio tested GPT-5.5’s biorisk-related capabilities: virology and pathogen knowledge, niche scientific knowledge, agentic bio capabilities, and bio AI tool usage. GPT-5.5 scores at or near the top on all of the evaluations we gave it. Some highlights:
Many thanks to the OpenAI team for engaging with us on pre-release testing! Our full results and methodology are described in this report: https://t.co/leEUTEevu4
3rd party pre-release testing like this is vital to understand how biosecurity-relevant capabilities are evolving and to ensure that safeguards, evaluations, and policy responses keep pace before these models reach the public.
Both algorithms flag COVID, but with ~100x more reads that match the conserved portion of the genome than cross the discontinuities, Clades of Concern would likely trigger when 1% as many people had been infected. Full post: https://t.co/nrVTGySPj3
When we explain the algorithms we use to analyze untargeted metagenomic sequencing data people always ask: would this have flagged COVID? The answer is yes, but the details explain a lot about how detection works.
If that algorithm were unavailable, it would have been flagged by Chimera Detection, which flags sequencing reads where only a portion matches a known pathogen. The discontinuities are at positions 21,697 and 23,074, and CD would flag reads crossing those points.
Over the winter we hired several people across the org:
* Alessandro Zulli (Zephyr lead)
* Jo Faraguna (Bioinformatics Engineer)
* Jake Lloyd (Research Associate)
* Jared Gurzenda (Senior Research Associate)
* Matt Benczkowski (Associate Scientist)
More details: https://t.co/NgCmZMef4l
SecureBio Detection has a lot to share since our last update: several new preprints on our wastewater work, scaled up our nasal swab collection dramatically, we're moving into a larger lab space, and we've rebranded from the "Nucleic Acid Observatory" to "SecureBio Detection"
More details: https://t.co/NgCmZMef4l
In collaboration with SecureBio's AI team we automated initial human review of flags. LLMs get sequencing reads, bioinformatic annotation, the ability to query BLAST to query databases, and a clear rubric, and they handle clear-cut cases well. Human review load is down ~80%.