Why run AI biorisk evals at all? In his new post, @JasperGeh explains the biorisk evidence hierarchy (first-principles arguments, evals, uplift RCTs) and why evals provide the best evidence-per-dollar.
Read the full post here: https://t.co/QeSZaE3Fzh
There's a common misconception that Brutalist buildings were unpainted, but thanks to microscopic analysis of the exteriors we can now recreate what they looked like in their prime.
oh you’re using claude code? everyone’s using open code. just kidding we’re all on amp code. we’re using cline, we’re using roo code. we just forked our own version of roo. were using kilo code. we were on coderabbit but their ceo yelled at us so now we’re using qorbit. apple just acquired them for $30bn so we just migrated our entire team to slash commands. one guy is still on aider. the PM is on loveable. he just shipped a new product on replit. the intern installed a slackbot that lets you chat with your spreadsheet. legal is still reviewing devin’s enterprise contract. we evaluated junie for three ukrainians using jetbrains. someone in slack just asked “has anyone tried amp?” we are using goose for scripts. next week we’re piloting augment code. the CTO heard good things about trae. our CEO is friends with the guy from conductor. our CFO resigned. our CISO said we’ve had fourteen supply chain attacks in the last week. we’re shipping the worlds most expensive todo app.
How can we verify that AI ChemBio safety tests were properly run?
Today we're launching STREAM: a checklist for more transparent eval results.
I read a lot of model reports. Often they miss important details, like human baselines. STREAM helps make peer review more systematic.
I've been procrastinating on this chart of all model card releases by OpenAI, GDM, and Anthropic:
• 4 cases of late safety results (out of 27, so ~15%)
• Notably 2 cases were late results showed increases in risk
• The most recent set of releases in August were all on time
This headline from the NYT, that came complete with a really nice photo series of the local impacted community, is I think a full lie rather than just misleading. It is not the case, anywhere, that data centers taking water has caused problems for communities.
The Nucleic Acid Observatory is hiring!
Having built the technical core of an early warning system, we now received funding to further scale our work, including owning initial outbreak response.
We’re hiring for four roles, with a referral bonus of up to $6k.
More details:
Hot take: Most AI-bioterrorism risk "debate" is people shadow-boxing over definitions, not different predictions about concrete points.
I've talked to many other experts. We often don’t agree on what “enable” means, so people think the risk is uncertain in ways it is not. 🧵
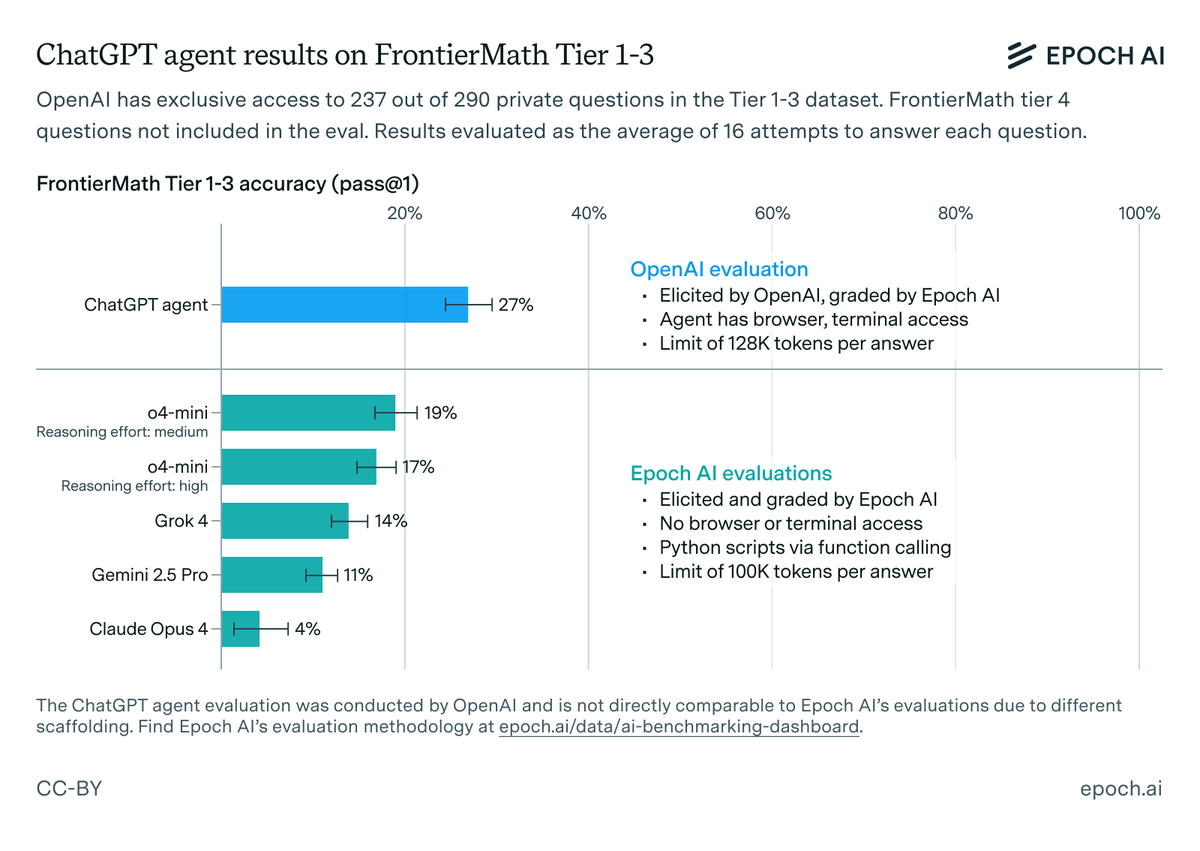
We have graded the results of @OpenAI's evaluation on FrontierMath Tier 1–3 questions, and found a 27% (± 3%) performance. ChatGPT agent is a new model fine-tuned for agentic tasks, equipped with text/GUI browser tools and native terminal access. 🧵
A bit more details on this:
1. Why is the dual deployment setup promising for bio?
a) Bioweapons adjacent knowledge (e.g. virology etc) is useful for a tiny fraction of the population. Removing it from a general purpose deployment is not actually curtailing much benefits. The existence of platforms like the one below that could put high KYCs affecting just a few thousands users enables to get the benefits with minimal costs.
b) bioweapons on the other hand are really bad so really worth decreasing the marginal risk close from zero.
c) note that this method is less promising for cyber which is very adjacent to code and which is more symmetric.
2) why shouldn't we stick to existing methods like constitutional classifiers?
a) because they don't really work as well as you'd want. A core reason why Anthropic made up this distinction in threat models between "universal" and "non universal" jailbreaks, narrowing down their commitment to universal ones, is that they couldn't defend against jailbreaks in general. So as a result they deployed their system which likely increases the risk non trivially, even assuming that it's resistant to all universal jailbreaks.
3) what are the technical challenges in doing this dual deployment setup?
a) the biggest uncertainty I have is whether you can get a model to be good at a domain just by feeding most knowledge/corpus very late stage in the training run. If it is the case, then doing this dual late stage training shouldn't be too painful. If not, that would make this process a lot costlier.
b) another challenge to solve but which seems much more feasible is to identify the overwhelming majority of bioweapons relevant knowledge & reasoning. For bio, it seems easier than for some other domains as it's pretty niche & identifiable.
Experts underestimate the progress of AI and the potential implications for pandemic risk.
We are proud to have contributed to a new study that shows how biosecurity experts and superforecasters think about biological risk and AI progress.