AI Solutions Architect at @nvidia. Working on LLMs, accelerators and AI. Before @graphcoreai, @amazon, PhD @imperialcollege. All views are my own. He/him.
Time for a new challenge: I've joined @nvidia as Solutions Architect for Conversational AI 🗣️🤖🧠!
I look forward to helping the AI community to use NVIDIA's GPUs for language applications. I'll be based in London, do reach out if you come over!
We are live discussing with the @bielikllm team about their Bielik models and how they compressed their Bielik 11B to 7B. Join us to ask life about pruning, distillation, post-training alignment, etc
https://t.co/GdvQ5kzn2H
🟢 ¡APÚNTATE AL GTC 2025!
El próximo 17-21 MARZO volverá el gran evento de NVIDIA. Un montón de ponencia de IA, robótica y mucho más!
Y como cada año, quien se registre conmigo podrá conseguir un gran premio!
Todos los detalles en este hilo 👇🧵
@omarespejel @igeniusai The data center may be in Italy, but the chips will probably come from Taiwan since TSMC is there and they produce the majority of NVIDIA chips.
It's really inspiring to be working with @igeniusai. I look forward to all the training and inference that will come out of their new Colosseum supercomputer with Grace Blackwell Superchips! Great news for Italy and Europe.
Unveiling Colosseum, one of the world’s largest #NVIDIADGX AI supercomputers, built in collaboration with @NVIDIA, and powered by NVIDIA Grace Blackwell Superchips, for the training and deployment of advanced models in highly regulated industries. Read more in the press release: https://t.co/JR1uwxGwva
The motivation is to help AI engineers to estimate the number of GPUs needed to run an AI model under certain requests/second or latency requirements.
The course is highly practical, with several notebooks using python, bash and deployment of @nvidia Inference Microservices.
Are you interested in AI Inference and want to dive deeper? Dima Mironov and I have created a practical course about "Sizing LLM Inference Systems".
Check it out and let us know what you think: https://t.co/YpsJFy8iKY
@harari_yuval in London this evening presenting #Nexus: a brief history of information networks.
He's on the side of existential risk with AI, but acknowledges that "we've just seen AI amoebas, who knows how the AI T-Rex will be?" For him AI is Alien Intelligence.
Join us at the AI Engineer meetup in London on the 17th October!
I'll be presenting about AI inference and how companies leverage cloud AI services or do-it-yourself strategies. As a bridge between both, I'll talk about @nvidia NIMs and its benefits.
https://t.co/P62qPr2B4s
AI Engineer London meetup is back again on October 17th. Big thanks to NVIDIA and again Cloudflare for supporting us.
Apply for a spot here: https://t.co/MBVeJu0ij6
Even after 4 years working in the semiconductor industry, I've learned a lot from reading this Economist's overview.
The end of Moore's law, Dennard's scaling, new ideas to reach a trillion transistors, specialized chips for AI... This overview is superb.
AI has returned chipmaking to the heart of computer technology. But it is time for some new ideas.
Read our latest Technology Quarterly to learn how advances in chipmaking, both incremental and radical, can keep the exponential engine humming https://t.co/NgBVGmKMQW 👇
📢Keynote Speaker for JADE Day 2024: Sergio Perez, NVIDIA
Sergio will give a talk on how NVIDIA enables scientific breakthroughs covering #GenAI, #GPUs, software libraries #NVIDIA has developed for scientific researchers & more
🔗https://t.co/8sAE5k4l9i
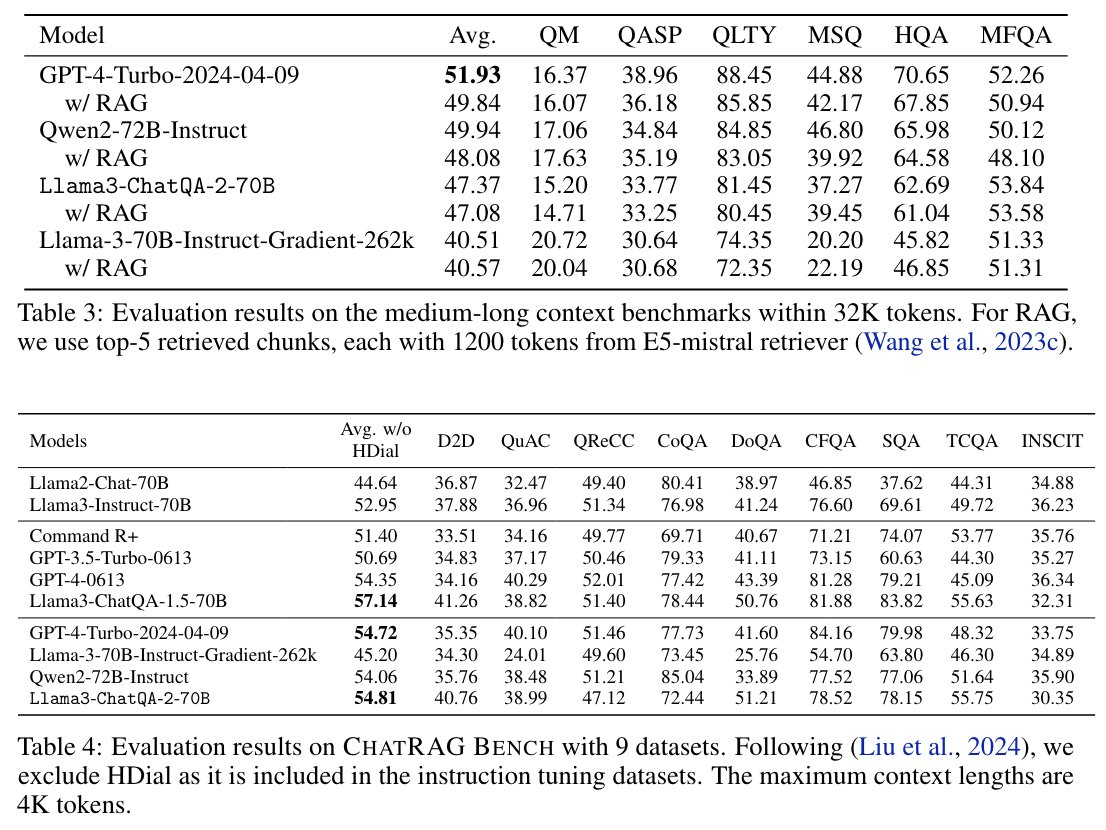
Introducing ChatQA 2, a Llama3-based model with a 128K context window, designed to close the gap between open LLMs and leading proprietary models like GPT-4-Turbo in both long-context and RAG capabilities.
The long-context capability of LLMs is sometimes viewed as a rival to RAG, but from a pragmatic perspective, they complement each other. RAG efficiently retrieves relevant contexts for query-based tasks from millions or billions of tokens, a feat long-context LLMs cannot achieve. Meanwhile, long-context LLMs excel at summarizing entire documents, where RAG may fall short. Thus, A state-of-the-art LLM should excel in both capabilities.
Highlights:
- The Llama3-ChatQA-2-70B model achieves accuracy comparable to GPT-4-Turbo-2024-0409 on real-world long-context tasks, and surpasses it on the ChatRAG benchmark.
- We find the long-context retriever can alleviate the top-k context fragmentation issue in RAG, further improving RAG-based results for long-context understanding tasks.
- We provide extensive comparisons between RAG and long-context solutions using state-of-the-art long-context LLMs.
Further Information:
- Paper: https://t.co/jEPQOsihpt
- Model weights & training blend: To be released soon!
Eager to try Llama 3.1 405B? Start calling it now with our inference endpoints: https://t.co/lA4keH47WS
With @NVIDIA AI Foundry, you can customise Llama 3.1 with your data: https://t.co/HoWAcGqK9p
Hi, any recommendations about VSCode extensions for OpenAI-compatible LLMs? I've been trying llm-vscode from @huggingface but I get errors https://t.co/RFoTG2Pvo3
"Graphcore today announced that the company has been acquired by SoftBank Group Corp"
Best wishes for my former colleagues in this new era for @graphcoreai
Are you in the Benelux area this week? 🇧🇪🇳🇱🇱🇺
Join us in Brussels at the @RedHat Tech Day to discuss about AI inference with NIMs and how to deploy them for production!
https://t.co/FpvFV5bX5g