my go-to model is opus 4.8 extra high. am i reading this correctly that fable 5 low (more or less) gets me the same general outcome for slightly *less* cost?
or is that the wrong way to look at this? is the *quality* of fable at "low" still somehow far better than opus?
I put a lot of heart into my technical writing, I hope it's useful to you all.
📌 Here's a pinned thread of everything I've written.
(much of this will be posted on the Claude blog soon as well)
I have to admit, I was tool-maxing, gas-town adjacent because I wanted to just make more happen, faster.
I have since read this, and the follow up to it multiple times, and I have learned a lot. I have to say it is more productive to like this.
https://t.co/hbdzFPxtGF
Ever wondered what cells and DNA really look like up close?
With our 3D animated textbooks, you’ll explore biology at true scale—making complex science easy to see and understand.
Dive in and experience learning like never before! Learn more at https://t.co/hjcPcmOkYb
#biology #3D #science #EdTech #STEM
Have you looked at how other top performers handle compaction and context? I just inspected AugmentCodes context compaction prompt output just by asking it. It's still forgetful though, especially about rule files that contain important info. I wish they had hooks I could hard code checks into.
I've been wanting to try flywheel privately but haven't had the time yet.
The latest frontier models (especially GPT 5.2 Pro and Opus 4.5) are extremely good at abstracting from specifics and finding the inner structure in a mass of detailed, complex ideas.
So I thought it would be interesting to unleash them on a set of ideas that have been very influential for me despite coming from a totally different field. And that's the incredible set of 236 transcripts from a 1994 interview with the great Sydney Brenner that were compiled from the WebOfStories project.
This is actually an idea I've been kicking around in the back of my mind ever since my posts a few months ago about model-guided research.
I first had Claude Code grab all the transcripts from the site and merge them into a single document. Unfortunately, this came out to 485kb of data as markdown text, so it was too large to all fit into the context window of GPT 5.2 Pro with Extended Reasoning in the web app.
So I simply split them into 3 chunks, and then used this "meta-prompt":
---
I want you to read and carefully study and ruminate on these transcripts of extended interviews with Sydney Brenner and I want you to find the sort of "inner threads" and general abstract patterns/symmetries about his whole manner and approach to scientific inquiry and why it was so fruitful and effective.
How was he able to form such good hypotheses so quickly on such scant data/observations? How was he able to survey the infinite space of "possible experiments" to find the next few to do that would be the most discriminative and yield the most in terms of incremental insights or new hypotheses?
How was he able to consistently see so much further ahead as to what were likely to be the most fruitful areas to look next where his unique analytical and theoretical gifts could yield the most outsized impact in the shortest amount of time?
What about his approach made it less dependent on big expensive machinery and technology, and more reliant on clever thinking and logic/induction? How did he employ Bayesian probabilistic reasoning implicitly in how he chose experiments to do and how to interpret the results of those experiments?
---
I put all of the various responses from different models, the original transcripts, the prompts, etc. together in a single repo at:
https://t.co/L0QBvjVlW4
I'm still not exactly sure what direction this project should go next. I think it's already really fascinating on several levels just looking at how the different models abstracted and synthesized generic approaches, systems, and methods from the raw transcript excerpts using the web apps.
And then how each of the coding agents read all of the materials (raw transcripts and outputs of the web apps) and attempted to distill it further into one single document (these are the three markdown files with filenames beginning "final_distillation_of_brenner_method").
Reading the different distillations gives a great window into the way each model "thinks" conceptually; they also couldn't be more different from each other, which I think is so amazing.
Of course, it makes sense given how the training process of a frontier model includes literally hundreds of separate decisions ranging from data curation, multi-objective optimization, post-training RL, etc. So of course the final models are going to think very differently. It's still very cool to see it in practice in such a pure, conceptual setting.
I personally think GPT 5.2 with extra high reasoning effort had the most compelling distillation, but they're all fascinating.
This process of going from long, specific, detailed source material through a sort of intellectual "funnel" in stages, lifting up to a higher level of abstraction in each tier, is exciting to me.
I am sure there are many other contexts where this approach can make a lot of sense, but advancing scientific research is the most electrifying for me given the potential.
I think the next thing I'm going to try doing is to present all this information in a beautiful way at https://t.co/pmQuptstKf (the current site is just a placeholder; the nice version should come later tonight).
Then, I want to see how I can leverage my existing agent tooling, particularly Agent Mail and my ntm and cm (cass memory) tools, to set up environments where the different agents from OpenAI, Anthropic, and Google, can have wide-ranging discussions where they can explore ideas and think about how to come up with good theories using all of Brenner's intellectual tricks and lenses.
I'm still trying to think through the best way to inject into their contexts the best distillations of Brenner's techniques.
After all, informal conversations are one of Brenner's favorite techniques; see this part straight from GPT 5.2's distillation:
# Conversation as hypothesis search
- “Never restrain yourself; say it… even if it is completely stupid… just uttering it gets it out into the open.”
- “Always try… to materialise the question in the form of… if it is like this, how would you go about doing anything about it?”
- Conversation is treated as a cheap stochastic search over hypotheses, with rapid pruning by a “severe audience.”
- Conversation also functions as an explicit escape hatch from deductive circles (“brings things together… [not] logical deduction”).
Now, the agents can't do experiments in a biology lab (yet! soon they will by controlling humanoid robots...), so I think it will probably be most useful to have them explore "computational science" where the experiments can be done using the computer the agents already have dominion over.
Then they can propose and run experiments and all see and interpret the results together, discussing them, pre-registering their expectations, and keeping each other intellectually honest and focused, by exchanging messages directly with each other using Agent Mail.
To focus them, I think I might seed the conversation by having them explore two of my existing research projects:
https://t.co/7SqMbUtBY5
https://t.co/mELylSCOkJ
Anyway, if you're not familiar with Brenner or the way his mind worked and his "meta approach" to science, you're in for a real treat if you can read through all the transcripts and the distillations.
When you think about how much this one person was able to advance our understanding of the natural world, it's captivating to think about what could happen if we could harness just a fraction of some of that ingenuity and guide it using his insights with an army of increasingly brilliant robot scientists.
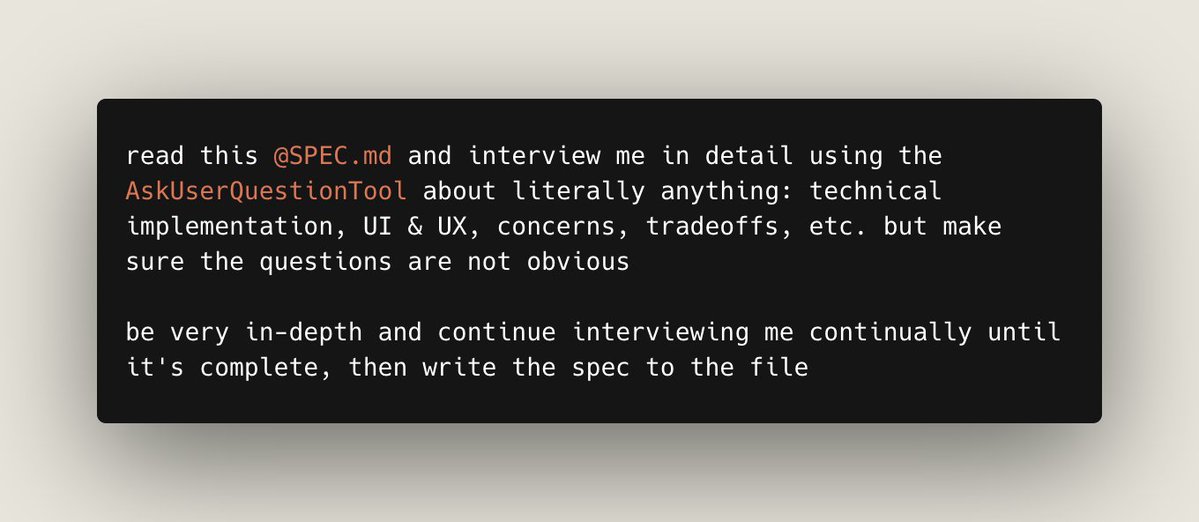
my favorite way to use Claude Code to build large features is spec based
start with a minimal spec or prompt and ask Claude to interview you using the AskUserQuestionTool
then make a new session to execute the spec








![doodlestein's tweet photo. The latest frontier models (especially GPT 5.2 Pro and Opus 4.5) are extremely good at abstracting from specifics and finding the inner structure in a mass of detailed, complex ideas.
So I thought it would be interesting to unleash them on a set of ideas that have been very influential for me despite coming from a totally different field. And that's the incredible set of 236 transcripts from a 1994 interview with the great Sydney Brenner that were compiled from the WebOfStories project.
This is actually an idea I've been kicking around in the back of my mind ever since my posts a few months ago about model-guided research.
I first had Claude Code grab all the transcripts from the site and merge them into a single document. Unfortunately, this came out to 485kb of data as markdown text, so it was too large to all fit into the context window of GPT 5.2 Pro with Extended Reasoning in the web app.
So I simply split them into 3 chunks, and then used this "meta-prompt":
---
I want you to read and carefully study and ruminate on these transcripts of extended interviews with Sydney Brenner and I want you to find the sort of "inner threads" and general abstract patterns/symmetries about his whole manner and approach to scientific inquiry and why it was so fruitful and effective.
How was he able to form such good hypotheses so quickly on such scant data/observations? How was he able to survey the infinite space of "possible experiments" to find the next few to do that would be the most discriminative and yield the most in terms of incremental insights or new hypotheses?
How was he able to consistently see so much further ahead as to what were likely to be the most fruitful areas to look next where his unique analytical and theoretical gifts could yield the most outsized impact in the shortest amount of time?
What about his approach made it less dependent on big expensive machinery and technology, and more reliant on clever thinking and logic/induction? How did he employ Bayesian probabilistic reasoning implicitly in how he chose experiments to do and how to interpret the results of those experiments?
---
I put all of the various responses from different models, the original transcripts, the prompts, etc. together in a single repo at:
https://t.co/L0QBvjVlW4
I'm still not exactly sure what direction this project should go next. I think it's already really fascinating on several levels just looking at how the different models abstracted and synthesized generic approaches, systems, and methods from the raw transcript excerpts using the web apps.
And then how each of the coding agents read all of the materials (raw transcripts and outputs of the web apps) and attempted to distill it further into one single document (these are the three markdown files with filenames beginning "final_distillation_of_brenner_method").
Reading the different distillations gives a great window into the way each model "thinks" conceptually; they also couldn't be more different from each other, which I think is so amazing.
Of course, it makes sense given how the training process of a frontier model includes literally hundreds of separate decisions ranging from data curation, multi-objective optimization, post-training RL, etc. So of course the final models are going to think very differently. It's still very cool to see it in practice in such a pure, conceptual setting.
I personally think GPT 5.2 with extra high reasoning effort had the most compelling distillation, but they're all fascinating.
This process of going from long, specific, detailed source material through a sort of intellectual "funnel" in stages, lifting up to a higher level of abstraction in each tier, is exciting to me.
I am sure there are many other contexts where this approach can make a lot of sense, but advancing scientific research is the most electrifying for me given the potential.
I think the next thing I'm going to try doing is to present all this information in a beautiful way at https://t.co/pmQuptstKf (the current site is just a placeholder; the nice version should come later tonight).
Then, I want to see how I can leverage my existing agent tooling, particularly Agent Mail and my ntm and cm (cass memory) tools, to set up environments where the different agents from OpenAI, Anthropic, and Google, can have wide-ranging discussions where they can explore ideas and think about how to come up with good theories using all of Brenner's intellectual tricks and lenses.
I'm still trying to think through the best way to inject into their contexts the best distillations of Brenner's techniques.
After all, informal conversations are one of Brenner's favorite techniques; see this part straight from GPT 5.2's distillation:
# Conversation as hypothesis search
- “Never restrain yourself; say it… even if it is completely stupid… just uttering it gets it out into the open.”
- “Always try… to materialise the question in the form of… if it is like this, how would you go about doing anything about it?”
- Conversation is treated as a cheap stochastic search over hypotheses, with rapid pruning by a “severe audience.”
- Conversation also functions as an explicit escape hatch from deductive circles (“brings things together… [not] logical deduction”).
Now, the agents can't do experiments in a biology lab (yet! soon they will by controlling humanoid robots...), so I think it will probably be most useful to have them explore "computational science" where the experiments can be done using the computer the agents already have dominion over.
Then they can propose and run experiments and all see and interpret the results together, discussing them, pre-registering their expectations, and keeping each other intellectually honest and focused, by exchanging messages directly with each other using Agent Mail.
To focus them, I think I might seed the conversation by having them explore two of my existing research projects:
https://t.co/7SqMbUtBY5
https://t.co/mELylSCOkJ
Anyway, if you're not familiar with Brenner or the way his mind worked and his "meta approach" to science, you're in for a real treat if you can read through all the transcripts and the distillations.
When you think about how much this one person was able to advance our understanding of the natural world, it's captivating to think about what could happen if we could harness just a fraction of some of that ingenuity and guide it using his insights with an army of increasingly brilliant robot scientists.](https://pbs.twimg.com/media/G9YWjEgXcAACwoT.jpg)