As 📷 xet-team infrastructure begins backing hundreds of repositories on the Hugging Face Hub, we’re getting to put on our researcher hats and peer into the bytes. 👀 🤓
IMO, one of the most interesting ideas Xet storage introduces is a globally shared store of data.
I 🙏 at the altar of stamina. "(Stamina is) the ability to chip away at goals despite a lack of visible progress. To hold focus and presence in a world incentivized to distract you. To stay patient. To be on time. To push through difficult material. To follow instructions or proceed without them."
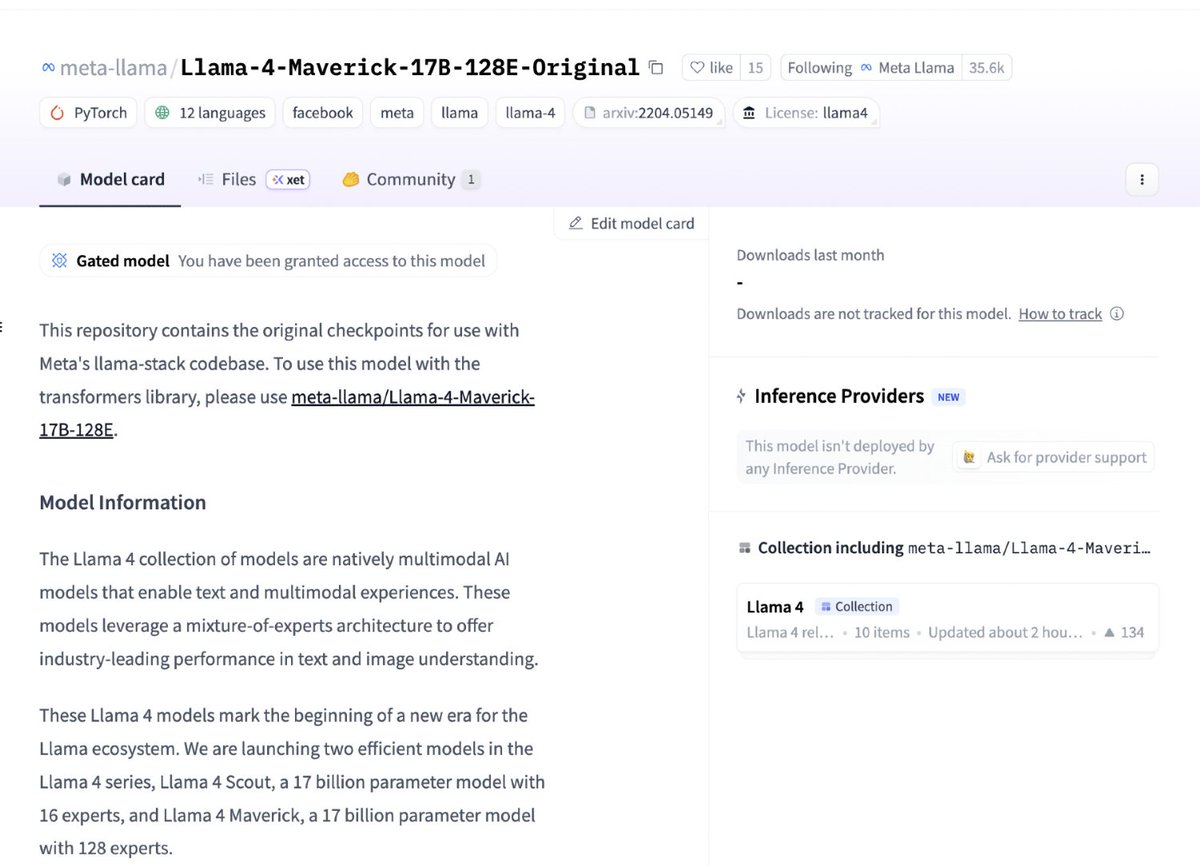
See that purple banner on the Llama 4 models? It's Xet storage, and this is actually huge for anyone building with AI models. Real numbers: ~25% deduplication on Llama 4 models, hitting ~40% for finetunes
The Lovelace 2.0 Test of Artificial Creativity and Intelligence “tell a story in which a boy falls in love with a girl, aliens abduct the boy, and the girl saves the world with the help of a talking cat.” Change that 🐱 to a 🐶 and I'd read that story any day.
https://t.co/dDnBE7cPec
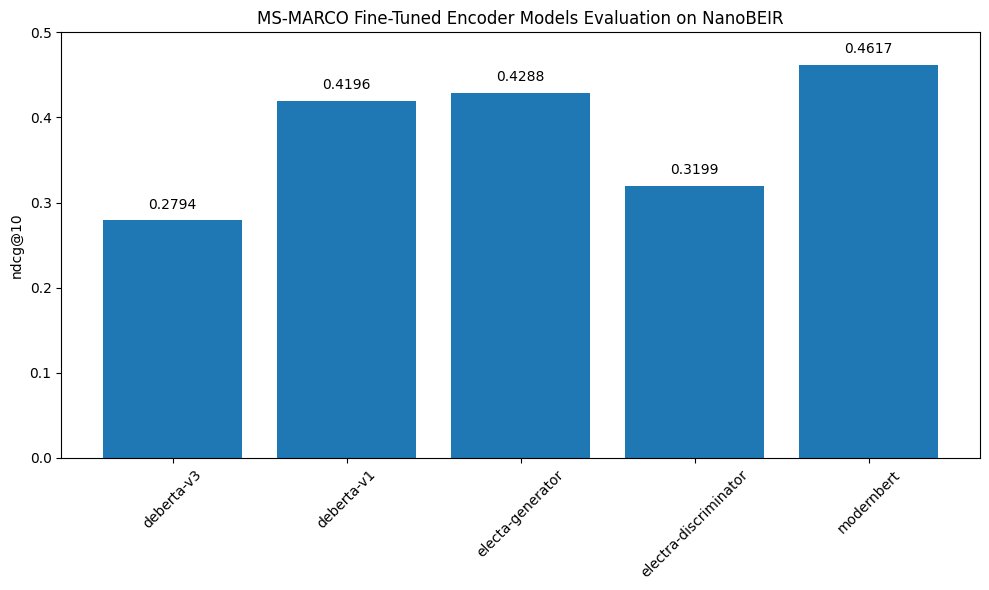
I just finished my small experiments comparing different encoder models on retrieval tasks.
The goal was to check whether MLM is better than RTD for these tasks.
I compared Electra's small models, both generator and discriminator, that have the same size. Additionally, it was tested DeBERTa v1, which was pre-trained with MLM and DeBERTa v3, which was pre-trained with RTD on a two times larger dataset. As a baseline ModernBERT was evaluated as well.
Models were fine-tuned on 500k examples from the MS-MARCO dataset (https://t.co/WTCXdEZFP1).
For benchmarking, the NanoBEIR evaluator was used. You can see the average ndcg@10 plotted below.
It's clearer that MLM-trained models produce better discriminative features, however, more detailed experiments are needed for more accurate conclusions.
@antoine_chaffin@tomaarsen
So cool to see transformers becoming the source of truth for model definition & collaborating with wonderful partners like vLLM to have these models run everywhere the fastest!
As a model builder, it means that you integrate with Hugging Face & instantly get hundreds of integrations out of the box.
Time to accelerate AI, one integration at a time!
Robotics simulation is how we teach robots to act smart—before they ever touch the real world. It’s physical AI: simulating Newtonian physics so robots can grip, move, and learn.
A new simulator is coming to @huggingface@LeRobotHF 🤗. Stay tuned 👀😉
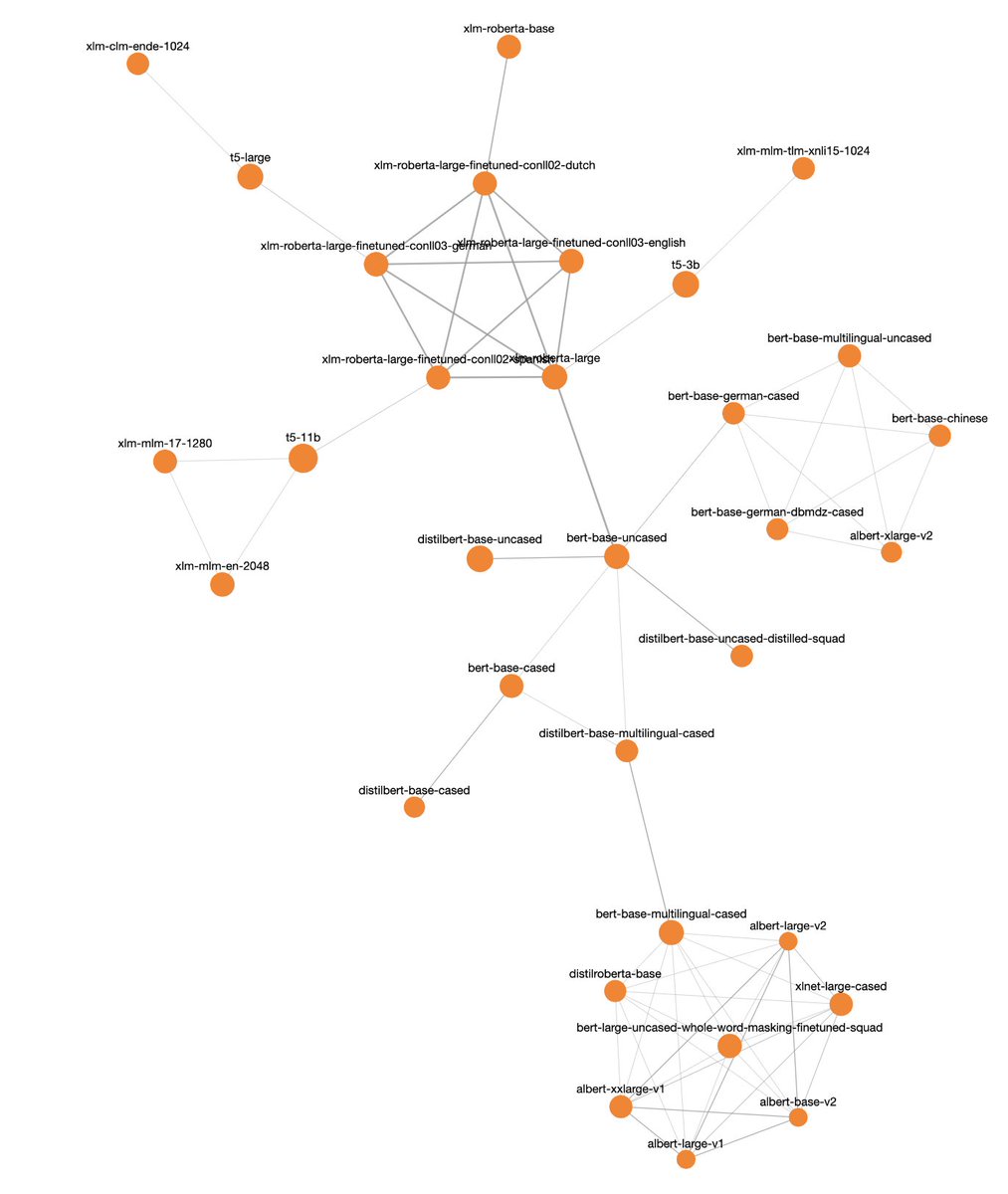
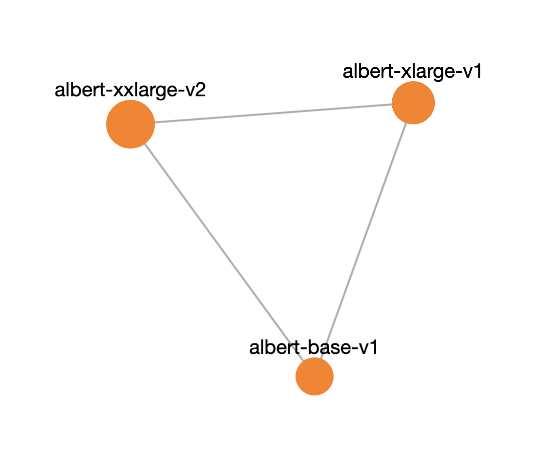
Come find the many BERT islands. Or see how datasets relate in practice, not just in theory. See how libraries or tasks can tie repositories together. You can play around with node size using storage/likes/downloads too.
The result is a super fun visualization from @saba9 and @znation that I’ve already lost way too much time to. I'm excited to see how the networks grow as we add more repositories!
xet-team/repo-graph
As 📷 xet-team infrastructure begins backing hundreds of repositories on the Hugging Face Hub, we’re getting to put on our researcher hats and peer into the bytes. 👀 🤓
IMO, one of the most interesting ideas Xet storage introduces is a globally shared store of data.
Because of this, different repositories can share bytes we store. That opens up something cool - we can draw a graph of which repos actually share data at the chunk level, where:
- Nodes = repositories
- Edges = shared chunks
- Edge thickness = how much they overlap
Need to convert CSV to Parquet?
Use https://t.co/8JZIbJ0hTh. It does the job instantly.
@cfahlgren1 provides many other tools on his website. Approved and bookmarked!