Why pay full compute for pixels you're not even looking at?
In our new work, Foveated Diffusion, we introduce a new concept for efficient image and video generation, motivated by how the human visual system works.
(See full thread below)
After multiple requests for the code of the visuals from my talk about Transition Matching, I made a notebook that reproduces the DTM vs. FM GIF!
This demo is a good way to build intuition on how TM and FM differ.
https://t.co/Qh3W9nfDrr
@urielsinger
🚀🎬We introduce TMD (Transition Matching Distillation): 480p videos generated from text prompts in < 3 NFEs!
1️⃣Main backbone for feature extraction and lightweight head for iterative refinement
2️⃣Distilled from Wan2.1 14B T2V combining MeanFlow & DMD2
🔗https://t.co/o4VyCBl3mJ
Incredible atmosphere at the poster session today! Thanks to everyone who visited 🙌
I’ll be at #NeurIPS2025 until Dec 8. If you missed the poster or just want to chat, my DMs are open.
Shoutout to @EliahuHorwitz for the pictures!
I'll be at NeurIPS on Dec 3-4.
Would be happy to meet up and chat about efficient sampling methods from language models ⚡️
Or, catch me at our EB-Sampler poster on Thursday 4:30pm
Joint work with @itai_gat, @_dsevero, Niklas Nolte, Brian Karrer
Had a blast talking about Transition Matching at the HUJI Vision Seminar, big thanks to @EliahuHorwitz for inviting me! 🚀
If you like simple visual illustrations of complex ideas, I made a few in my slides: https://t.co/WAOALJRAUy
New work: “GLASS Flows: Transition Sampling for Alignment of Flow and Diffusion Models”. GLASS generates images by sampling stochastic Markov transitions with ODEs - allowing us to boost text-image alignment for large-scale models at inference time!
https://t.co/unsuG3mYer
[1/7]
Excited to share our work Set Block Decoding!
A new paradigm combining next-token-prediction and masked (or discrete diffusion) models, allowing parallel decoding without any architectural changes and with exact KV cache.
Arguably one of the simplest ways to accelerate LLMs!
@zamedii_@urielsinger@itai_gat@lipmanya Thanks, Richard! Note that Appendix B of our paper includes training code snippets for all our TM variants (see DTM in the screenshot below).
[1/n]
New paper alert! 🚀
Excited to introduce 𝐓𝐫𝐚𝐧𝐬𝐢𝐭𝐢𝐨𝐧 𝐌𝐚𝐭𝐜𝐡𝐢𝐧𝐠 (𝐓𝐌)! We're replacing short-timestep kernels from Flow Matching/Diffusion with... a generative model🤯, achieving SOTA text-2-image generation!
@urielsinger@itai_gat@lipmanya
@Fate_10kokoro@Fate_10kokoro here’s the r.v DTM samples https://t.co/Ji72FwHjaD.
informally: if k is large and k/T small, then repeatedly sampling the transition kernel k times with step size 1/T is roughly an Euler step of size k/T with the kernel’s expectation as velocity.
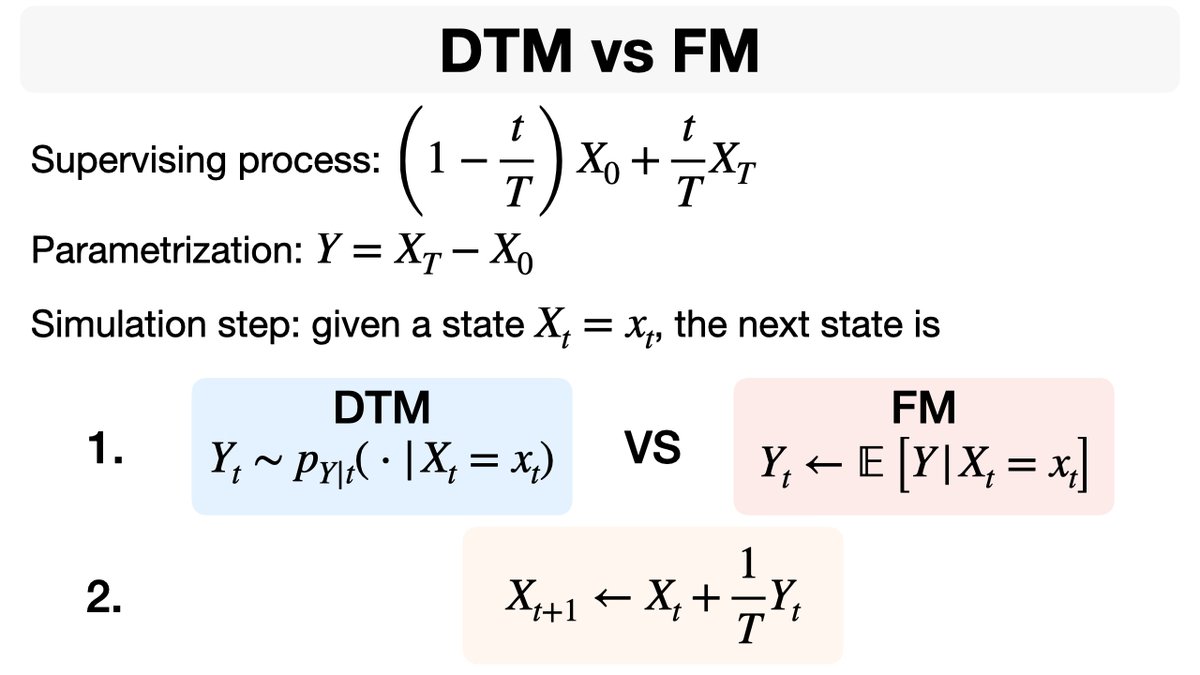
If you're curious to dive deeper into Transition Matching (TM)✨🔍, a great starting point is understanding the similarities and differences between 𝐃𝐢𝐟𝐟𝐞𝐫𝐞𝐧𝐜𝐞 𝐓𝐫𝐚𝐧𝐬𝐢𝐭𝐢𝐨𝐧 𝐌𝐚𝐭𝐜𝐡𝐢𝐧𝐠 (𝐃𝐓𝐌) and Flow Matching (FM)💡.
DTM vs FM👇
Lots of interest in how Difference Transition Matching (DTM) connects to Flow Matching (FM).
Here is a short animation that illustrates Theorem 1 in our paper:
For a very small step size (1/T), DTM converges to an Euler step of FM.
[1/n]
New paper alert! 🚀
Excited to introduce 𝐓𝐫𝐚𝐧𝐬𝐢𝐭𝐢𝐨𝐧 𝐌𝐚𝐭𝐜𝐡𝐢𝐧𝐠 (𝐓𝐌)! We're replacing short-timestep kernels from Flow Matching/Diffusion with... a generative model🤯, achieving SOTA text-2-image generation!
@urielsinger@itai_gat@lipmanya
@nico_dufour@urielsinger@itai_gat@lipmanya [2/2]
Such an approach doesn’t hurt performance—on the contrary, it may offer a path for improvement. We verified that gains aren’t due to “overfitting” the transition kernel with fewer steps.
@nico_dufour@urielsinger@itai_gat@lipmanya [1/2]
DTM is intrinsically a discrete-time process: different time discretization➡️different process.
However, DTM depends only on the current time, allowing to learn a continuous-time model (parameters are shared between processes) and discretization can be selected at inference
@nico_dufour@urielsinger@itai_gat@lipmanya Thanks Nicolas! FM learns the expected transition, while DTM learns to sample from the full transition distribution (slide). Adding a small MLP to FM didnt help—only when the MLP became a generative model (i.e., DTM) we saw improvements. I'll post more on DTM–FM soon, stay tuned!
@CSProfKGD I’m glad you take interest in our work Kosta. Mean flows is indeed exciting work! From TM perspective, they learn large step-size transitions with a deterministic kernel which is very interesting. I don't have a more elaborate answer at the moment, but I plan to look into it.
If you're curious to dive deeper into Transition Matching (TM)✨🔍, a great starting point is understanding the similarities and differences between 𝐃𝐢𝐟𝐟𝐞𝐫𝐞𝐧𝐜𝐞 𝐓𝐫𝐚𝐧𝐬𝐢𝐭𝐢𝐨𝐧 𝐌𝐚𝐭𝐜𝐡𝐢𝐧𝐠 (𝐃𝐓𝐌) and Flow Matching (FM)💡.
[1/n]
New paper alert! 🚀
Excited to introduce 𝐓𝐫𝐚𝐧𝐬𝐢𝐭𝐢𝐨𝐧 𝐌𝐚𝐭𝐜𝐡𝐢𝐧𝐠 (𝐓𝐌)! We're replacing short-timestep kernels from Flow Matching/Diffusion with... a generative model🤯, achieving SOTA text-2-image generation!
@urielsinger@itai_gat@lipmanya
@vtaohu Great question! FM learns to approximate the expectation of the transition kernel, whereas DTM learns to sample from the underlying distribution of transitions. Hence, DTM is more expressive. Note, for a very small step size (1/T), FM's approximation is fully expressive!
Difference Transition Matching (DTM) process is so simple to Illustrate, you can calculate it on a whiteboard!
At each step:
Draw all lines connecting source and target (shaded)
⬇️
List those intersecting with the current state (yellow)
⬇️
Sample a line from the list (green)
[1/n]
New paper alert! 🚀
Excited to introduce 𝐓𝐫𝐚𝐧𝐬𝐢𝐭𝐢𝐨𝐧 𝐌𝐚𝐭𝐜𝐡𝐢𝐧𝐠 (𝐓𝐌)! We're replacing short-timestep kernels from Flow Matching/Diffusion with... a generative model🤯, achieving SOTA text-2-image generation!
@urielsinger@itai_gat@lipmanya