Why pay full compute for pixels you're not even looking at?
In our new work, Foveated Diffusion, we introduce a new concept for efficient image and video generation, motivated by how the human visual system works.
(See full thread below)
New research from @bfl_ml 🥳
Meet Self-Flow: our self-supervised framework for image, audio, video & world models 🤖
https://t.co/AshY8IkSEe
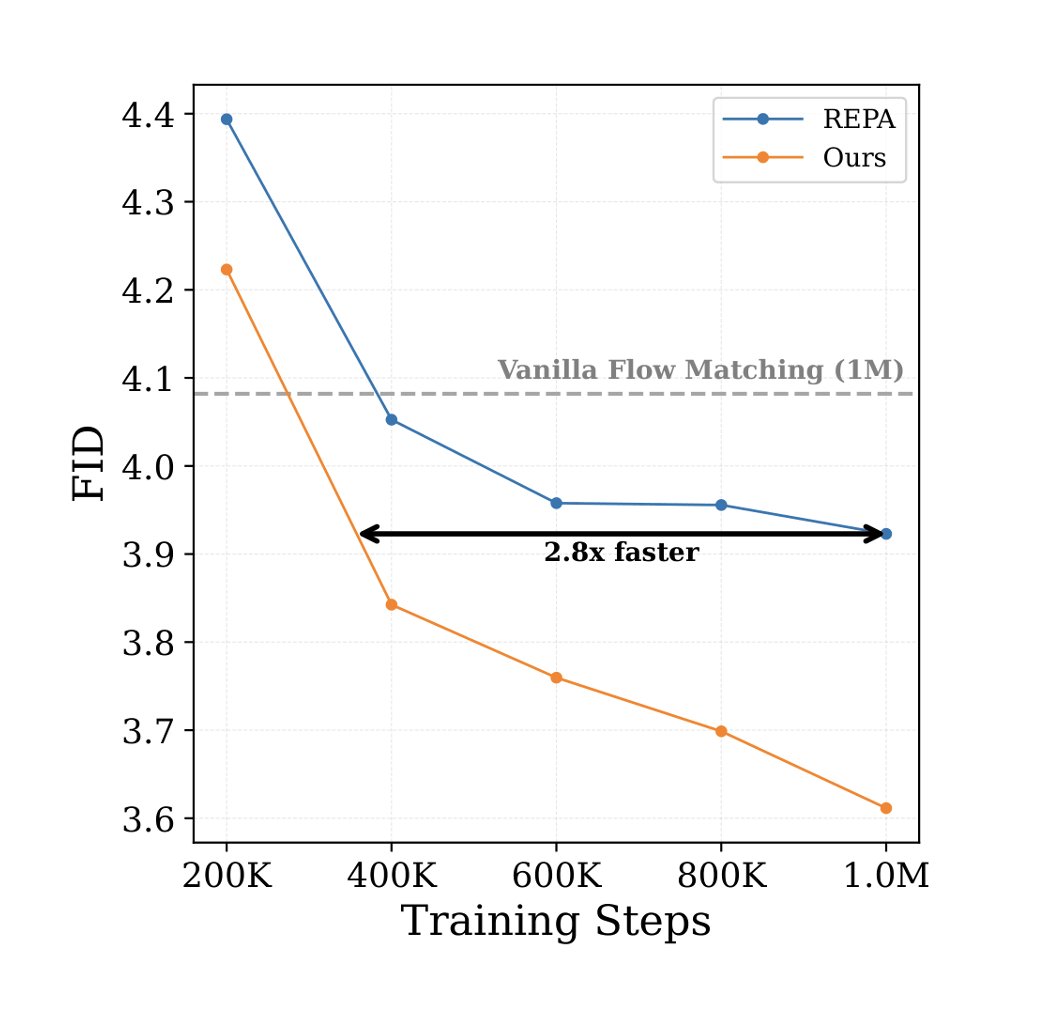
Do generative models really need DINO to learn strong representations? We propose teaching them directly via a joint framework instead 🧵
[3/3]
We systematically study the key modeling/training/sampling knobs and share practical guidance for better quality ✅ and faster generation ⚡—backed by a large-scale sweep of 56 pretrained models and 549 evaluations to map the design space. 📊
[2/3]
In our previous paper, Transition Matching: Scalable and Flexible Generative Modeling (https://t.co/1atqaxcns8), we introduced transition matching—a new generative paradigm. This follow-up goes beyond the concept and asks: which design choices actually matter? 🔍
🚀🎬We introduce TMD (Transition Matching Distillation): 480p videos generated from text prompts in < 3 NFEs!
1️⃣Main backbone for feature extraction and lightweight head for iterative refinement
2️⃣Distilled from Wan2.1 14B T2V combining MeanFlow & DMD2
🔗https://t.co/o4VyCBl3mJ
After multiple requests for the code of the visuals from my talk about Transition Matching, I made a notebook that reproduces the DTM vs. FM GIF!
This demo is a good way to build intuition on how TM and FM differ.
https://t.co/Qh3W9nfDrr
@urielsinger
New work: “GLASS Flows: Transition Sampling for Alignment of Flow and Diffusion Models”. GLASS generates images by sampling stochastic Markov transitions with ODEs - allowing us to boost text-image alignment for large-scale models at inference time!
https://t.co/unsuG3mYer
[1/7]
Excited to share our work Set Block Decoding!
A new paradigm combining next-token-prediction and masked (or discrete diffusion) models, allowing parallel decoding without any architectural changes and with exact KV cache.
Arguably one of the simplest ways to accelerate LLMs!
DTM vs FM👇
Lots of interest in how Difference Transition Matching (DTM) connects to Flow Matching (FM).
Here is a short animation that illustrates Theorem 1 in our paper:
For a very small step size (1/T), DTM converges to an Euler step of FM.
If you're curious to dive deeper into Transition Matching (TM)✨🔍, a great starting point is understanding the similarities and differences between 𝐃𝐢𝐟𝐟𝐞𝐫𝐞𝐧𝐜𝐞 𝐓𝐫𝐚𝐧𝐬𝐢𝐭𝐢𝐨𝐧 𝐌𝐚𝐭𝐜𝐡𝐢𝐧𝐠 (𝐃𝐓𝐌) and Flow Matching (FM)💡.
This paper is awesome.
🔥 Flow-matching for flow-matching!
❌No more coarse-to-fine generation.
🚀Coarse and fine details emerge together during generation.
🏆Results look super promising, especially when you see how the images evolve.
Difference Transition Matching (DTM) process is so simple to Illustrate, you can calculate it on a whiteboard!
At each step:
Draw all lines connecting source and target (shaded)
⬇️
List those intersecting with the current state (yellow)
⬇️
Sample a line from the list (green)
Introducing Transition Matching (TM) — a new generative paradigm that unifies Flow Matching and autoregressive models into one framework, boosting both quality and speed!
Thank you for the great collaboration @shaulneta@itai_gat@lipmanya
[1/n]
New paper alert! 🚀
Excited to introduce 𝐓𝐫𝐚𝐧𝐬𝐢𝐭𝐢𝐨𝐧 𝐌𝐚𝐭𝐜𝐡𝐢𝐧𝐠 (𝐓𝐌)! We're replacing short-timestep kernels from Flow Matching/Diffusion with... a generative model🤯, achieving SOTA text-2-image generation!
@urielsinger@itai_gat@lipmanya
**Transition Matching** is a new iterative generative paradigm using Flow Matching or AR models to transition between generation intermediate states, leading to an improved generation quality and speed!
Exciting news from #ICML2025 & #ICCV2025 🥳
- 🥇 VideoJAM accepted as *oral* at #ICML2025 (top 1%)
- Two talks at #ICCV2025
☝️interpretability in the generative era
✌️video customization
- Organizing two #ICCV2025 workshops
☝️structural priors for vision
✌️long video gen
🧵👇
Excited to share our recent work on corrector sampling in language models! A new sampling method that mitigates error accumulation by iteratively revisiting tokens in a window of previously generated text.
With: @shaulneta@urielsinger@lipmanya
Link: https://t.co/54etkhxNEK