Missing Fable 5🥹? Come and cast your votes on 3DCodeArena https://t.co/KBEEv4qH5A to see it’s performance on agentic 3D modeling via writing code.
Check https://t.co/6RWSgVW5XQ for more results of 12 frontier LLMs/VLMs on text/image to 3D generation via Blender code.
Code is released https://t.co/SpL82YEz42. Please star if you find it interesting!
#Fable #Claude #Gemini #GPT #Blender #ProceduralModeling #GoogleDeepmind
🚨 New #CVPR2026 collaboration with Google DeepMind --> Ego2Web bridges egocentric video perception and web execution, enabling agents that see the first-person real-world video of the user’s surroundings, and take actions on the web grounded in the egocentric video:
▪️ Introduces a task where agents must ground egocentric video (first-person view) into concrete web actions (requires visual grounding → entity extraction → planning → real website execution).
▪️Covers realistic cross-domain tasks e.g., e-commerce (find/buy items you saw), media retrieval (find related videos), knowledge lookup (identify & query entities), maps/local (locate places from visual cues).
▪️Proposes Ego2WebJudge to automatically evaluate whether web agent results are correctly grounded in the video context.
▪️Reveals concrete failure modes across 6 strong agents (GPT-5.4, Claude, Gemini-based agents, etc.): weak visual grounding, brittle cross-modal reasoning, and planning breakdowns (only ~58% success rate).
Details 👇👇
Introducing Ego2Web from Google DeepMind and UNC Chapel Hill, accepted to #CVPR2026.
AI agents can browse the web. But can they act based on what you see? Existing benchmarks focus only on web interaction while ignoring the real world.
Ego2Web bridges egocentric video perception and web execution, enabling agents that can see through first-person video, understand real-world context, and take actions on the web grounded in the egocentric video.
This opens a path toward AI assistants that operate seamlessly across physical and digital environments. We hope Ego2Web serves as an important step for building more capable, perception-driven agents.
🧵👇
Our team at FAIR, @AIatMeta is looking for a 2026 Summer Intern to work on video pretraining, with related interests in video generation, world models, or robotics.
Given the current timing, we’re especially happy to hear from PhD students who have been prioritizing research last year and may not have had much time for ad-hoc/random trials on internship interviews (I was definitely in that situation during my PhD 😆). Feel free to DM me.
Thrilled that SAM 3 and SAM 3D @AIatMeta leverage Meta CLIP(https://t.co/v4FHn1uOjJ)’s concept-rich images that greatly expanding and scaling concept-based image curation.
Truly appreciate the authors of Molmo @Molmo_AI (from @allen_ai and @UW) for promoting open research and adopting MetaCLIP. There are many forms of openness today—such as open APIs, open weights, and open-source for reproducibility etc. I view MetaCLIP and Molmo's research approach as “from scratch” that is on top of being open: building the entire process without relying on black-box modules that limit the research scope, pushing the limit of every module and sharing both the knowledge and insights gained along the way.
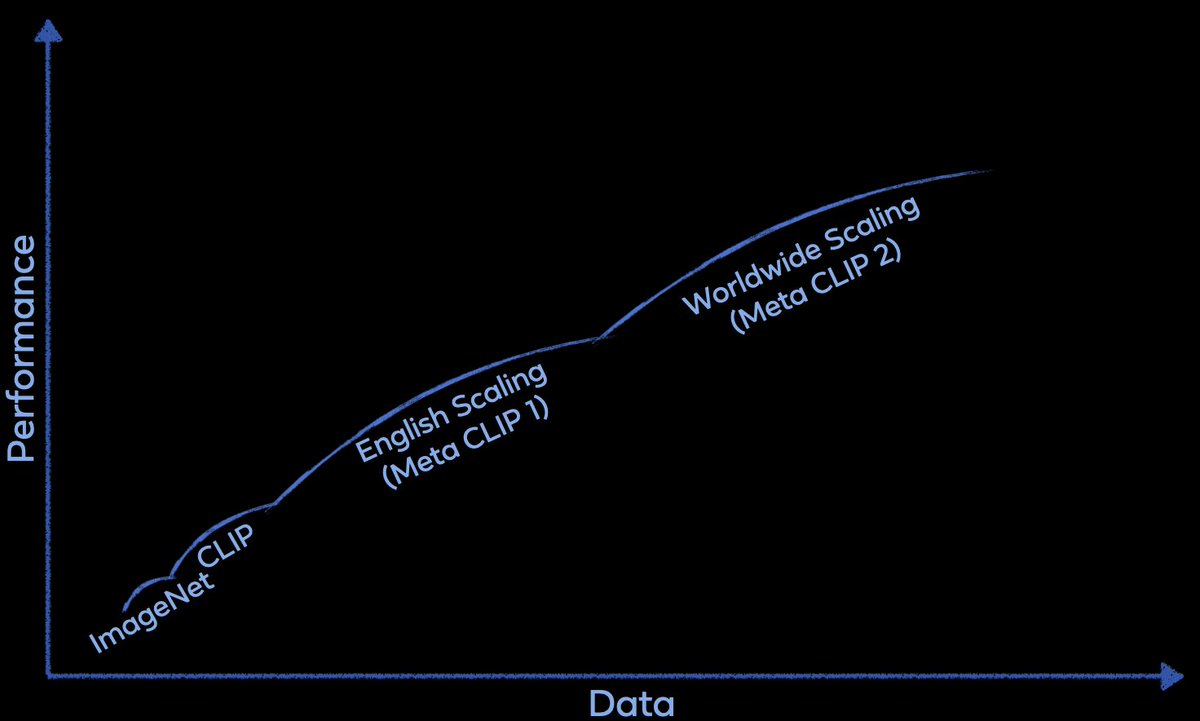
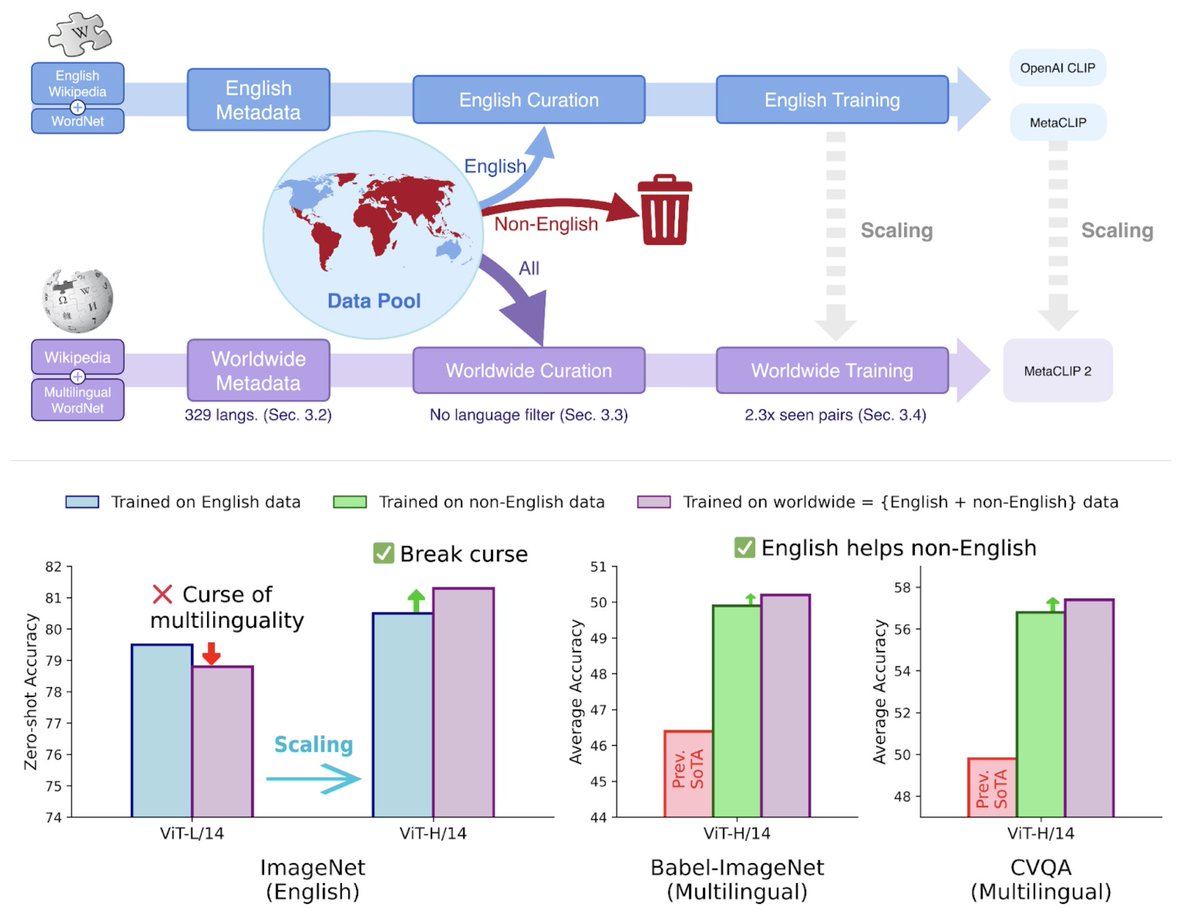
The cross-modal multilingual capability in Meta CLIP 2 is naturally from scaling. It is a reflection of the Bitter Lesson(@RichardSSutton) on building a scalable learning environment, and let optimization and scale do the heavy lifting. Inspired by Jensen Huang’s scaling law plot (at CES2025), the scaling isn’t just about increasing compute or data at each stage—it’s about consistently identifying bottlenecks, removing constraints, and rethinking a simpler setup to make it more scalable. This mindset extends to data curation itself: starting from ImageNet to worldwide data curation. @AIatMeta
🌿Introducing MetaCLIP 2 🌿
📝: https://t.co/mSncoFH5bE
code, model: https://t.co/11j9HcaeAB
After four years of advancements in English-centric CLIP development, MetaCLIP 2 is now taking the next step: scaling CLIP to worldwide data. The effort addresses long-standing challenges: (1) large-scale non-English data curation pipelines are largely undeveloped, and (2) the curse of multilinguality, where English performance often degrades in multilingual CLIP compared to English-only CLIP. With a complete recipe for worldwide CLIP—spanning data curation, modeling, and training—we show that English and non-English worlds can mutually benefit and elevate each other, achieving SoTA multilingual performance. Join the Meta booth at #ACL2025 to learn more.
(1/3)
Thanks for highlighting this impact. Yes, we keep removing existing well-known filters since the start of Meta CLIP 1 and English filter is the last one. We believe every data point has its unique information (eg, file name has concepts, timestamp talks about how old the camera etc.) and removes it is at risk of losing (unknown) information. It's only about how much that information human really cares. Curation (select, not remove) is TheRightWay™, alignment is even more TheRightWay™. Illustrated as a venn diagram in our #icml2025 talk, basically the bitter lesson is one cannot approximate a desired training distribution with a finite number of binary classifiers, well enough?
Join us at the Computer Use Agents workshop at ICML2025. Happening now in West Meeting Room 211, Vancouver Convention Centre!
We have a day packed with fantastic invited and contributed talks, posters, and discussions!
⏳ Less than 1 day left to submit!
🔦 Speaker Spotlight Time!
We’re thrilled to welcome Yu Su (@ysu_nlp), Distinguished Assistant Professor at The Ohio State University, as an invited speaker at the ICML 2025 Workshop on Computer Use Agents!
His work bridges LLM agents, memory, and planning, driving some of the most cited advances in the field.
#ICML2025 #LLMAgents #ComputerUseAgents #NLProc
Thanks for the invited talk and happy to share our industrial insights on “scaling data alignment” from Meta CLIP (its wide adoption and what’s next) in the DataWorld workshop #ICML2025 . happy to chat offline about data research.
Facebook AI Research (FAIR) is a small, prestigious lab in Meta. We don't train large models like GenAI or MSL, so it's natural that we have limited GPUs. GenAI or MSL's success or failure, past or future, doesn't reflect the work of FAIR. It is important to make this distinction
It’s been an amazing few months of relentless building, shipping, and optimising our models incorporating your feedback. Excited for more users and developers to try out the incredible Gemini 2.5 series!