The host of In Our Time, one of the best podcasts (from BBC or otherwise), Melvyn Bragg, retires. Apparently the podcast will continue under a new host. Big shoes to fill. https://t.co/ymVdTYBd3d
🤖 Efficient Document Data Extraction with LLMs & Vector Databases
Extracting structured data from unstructured documents is often tedious with traditional tools. @GetUnstract, using LLMs alongside Timescale Cloud, automates this process, removing the need for manual annotations.
With Timescale’s pgvector and AI extensions, token costs are reduced significantly, making complex document extraction more efficient—even for lengthy files.
💡 Start exploring how Timescale Cloud can simplify structured data extraction from unstructured documents.
🔗 Link below.
#LLMs #VectorDatabases #DataExtraction #TimescaleCloud #Data #Postgres
GPT-4o is bad at processing PDF documents.
Whoever tells you otherwise is not living in the real world. In 2024, people fill out forms using pen and paper. Try to answer questions from those forms using modern models, and you'll be disappointed.
I recorded a video to show you how to fix this.
The answer is simple: stop letting the model see your PDF document. Instead, preprocess it and stick to showing the model text.
Watch the video. You'll go from "THIS IS CRAP" to "EXCELLENT" in no time.
I'm using @GetUnstract to turn the documents into text while keeping the original format (this is crucial!) You can use them to process up to 100 pages for free. They collaborated with me on this post.
You can find the code I wrote right here:
https://t.co/qAancOxBYR
🆕💡🎧 @shuveb@GetUnstract
🔑 Leverage LLMs for accurate data extraction
፨ Automate unstructured data workflows
🛑 Build custom data pipelines with a no-code platform
🔗 https://t.co/zaZNE0vWbe
📄 PDFs are tough to process. Unfortunately, it's a widely prevalent format and businesses have to deal with PDFs all the time. So what are those challenges and some libraries & services for PDF processing?
https://t.co/gNn3WPNkZU
#pdf#llm#dataextraction#genai#rag
I know $12 USD is a lot of money for some people, so to celebrate 1000+ sales (!!!!), I'm giving away 1000 PDF copies of How Git Works (honour system: only if $12 is a lot for you!)
Here's the link, enter code BUYONEGIVEONE at checkout to get a free copy https://t.co/izvAb2dxld
(it'll ask you for a billing address but you can enter a fake address if you'd prefer)
Join Unstract at @ITI_Insurtech, NY 2024!
Discover how to successfully navigate AI in automating insurance workflows with Kevin O'Brien and @narenism @ #Booth 419
Ask us how to leverage AI to eliminate manual processes involving unstructured data.
#insurtech
@pramode_ce@SubinSiby More like "Debian for human beings" lol. But honestly, it was probably Debian for desktops. It's become the default go-to distro for newcomers and that's no easy achievement. I probably hoarded more CDs than I could ever hope to distribute. But there was always bandwidth anxiety
At Freshworks Chennai, everyday is fun but today is Madras Day special celebration 🎉🎉Happy Madras Day everyone!! - https://t.co/0R69Qfewwn #MadrasDay#freshworks
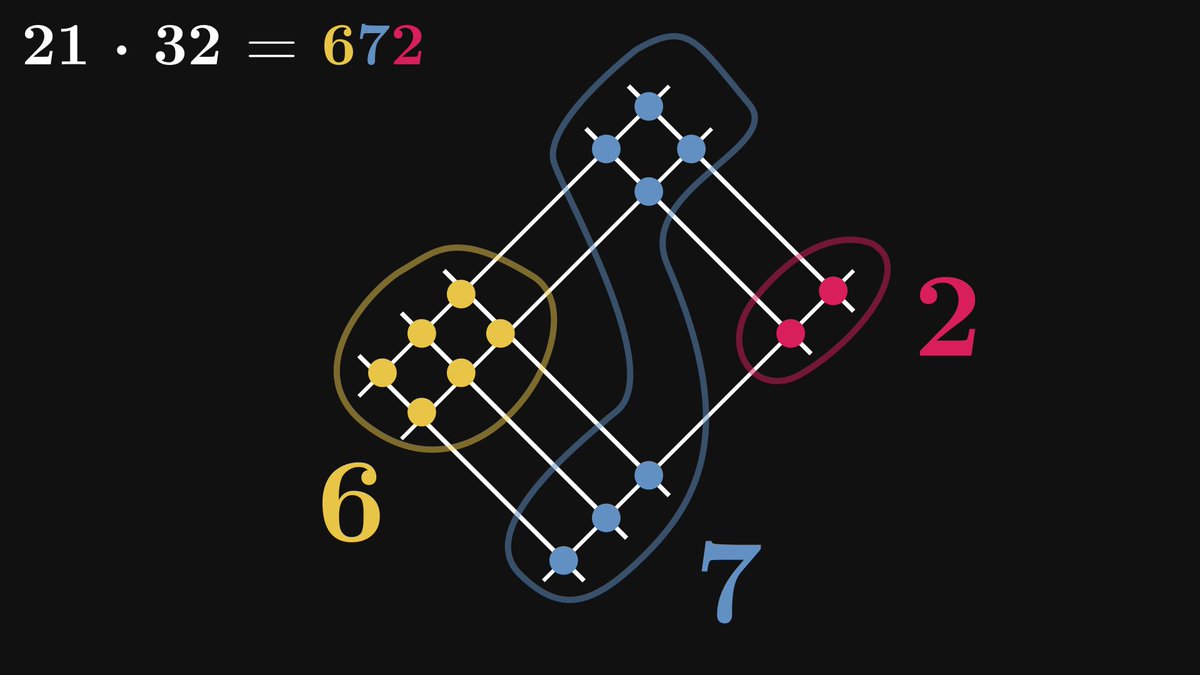
The Japanese multiplication method makes everybody feel "I wish they taught math like this in school."
It's not just a cute visual tool: it illuminates how and why long multiplication works.
Here is the full story.
delighted to announce that my new zine "How Integers and Floats Work!" is out today!
You can get it here for $12: https://t.co/mhnf0AH49G
It explains all of the surprising facts about how your computer does math, and it was SO fun to write.
Quick demo of @ZipstackHQ querying Salesforce live with SQL. One of the 270+ sources you can live query with SQL. Do pretty much every data workflow with just SQL!
More: https://t.co/loBYLyKB78 #datastack#etl#sql#salesforce#dataengineering
You'd think every computer should be able to divide two numbers, but early microprocessors didn't have division instructions. The Intel 8086 (1978) was one of the first with division. Let's look at how it implemented division and why division is so hard.