Multicalibration is a fairness notion which requires predictors to be calibrated over subgroups.
In work with @dutchhansen (applying to PhDs!), @PreetumNakkiran, and Vatsal Sharan, we empirically ask: when are machine learning models multicalibrated with no additional effort?🧵
@suchenzang In at least one (popular) stylized model, identification is actually more difficult than generation: https://t.co/wqb0nBx7xb. @AnayMehrotra is one expert in this area that I know of!
I’m really excited to be @iclr_conf this week presenting our work on substructure-aware protein modeling! DM me if you want to chat about protein models, baking biological priors into ML architectures, and anything bioML for experimentalists!
We built Magneton, a model-agnostic framework that distills decades of curated substructure knowledge into any pretrained encoder. We find that substructure signal is complementary to both sequence and structure as well as helps models generalize to unseen substructure types. Come say hi at our poster on Saturday from 10:30AM-1:00PM @ Pavilion 3 P3-#1006!
This work is near and dear to my heart because it’s my first (co)first-author main conference paper from my undergrad. A heartfelt shoutout to my mentors Robert Calef, @manoliskellis, @marinkazitnik for all their support!
Website: https://t.co/bvC9WM5lWZ
Paper: https://t.co/3hYEbmEc0V
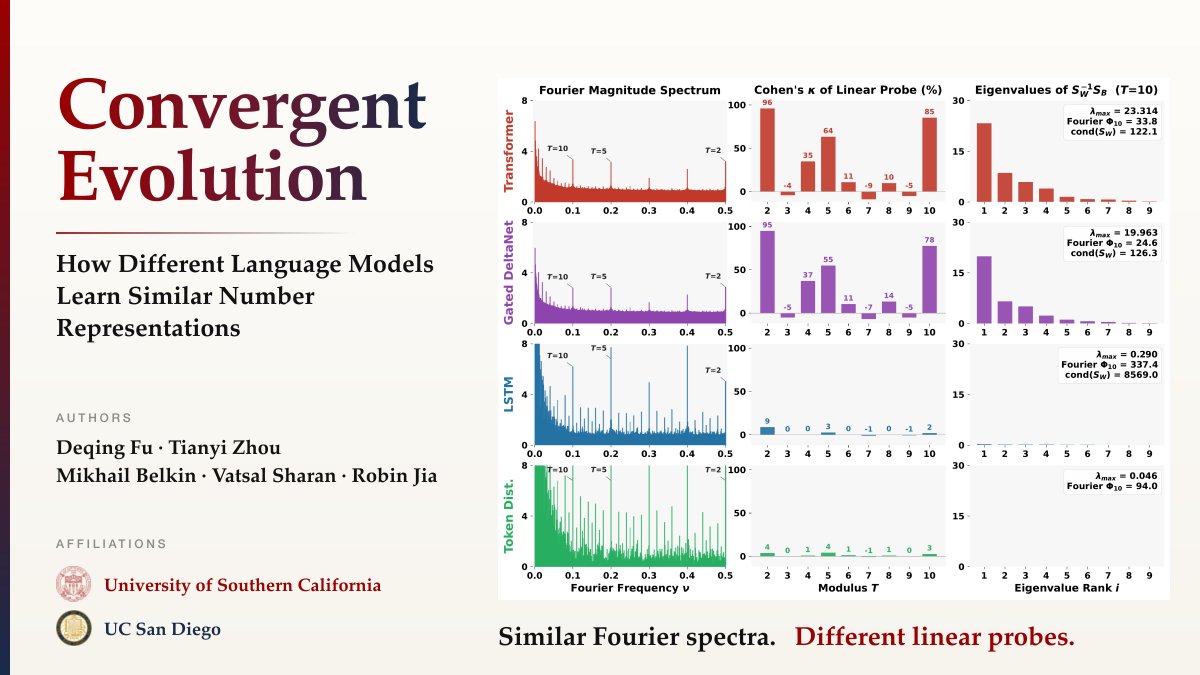
New paper: Convergent Evolution: How Different Language Models Learn Similar Number Representations.
Language models, classical word embeddings, and even raw token frequencies all develop the same Fourier features for numbers. But only some develop the underlying structure. 🧵
A reward model that works, zero-shot, across robots, tasks, and scenes?
Introducing Robometer: Scaling general-purpose robotic reward models with 1M+ trajectories.
Enables zero-shot: online/offline/model-based RL, data retrieval + IL, automatic failure detection, and more!
🧵 (1/12)
1/6 🧵 Calibration is hard. Multicalibration—fixing errors across every possible subgroup—is usually impossible at scale. Until now. Introducing MCGrad: A production-ready multicalibration library from Meta, accepted at KDD 2026. 🚀 https://t.co/iIxOg8hBIS
@aparandehgheibi Hi Ali, would love to chat sometime at Neurips. Am currently looking for full-time opportunities (graduating in the spring). I couldn't DM you, so commenting here!
LLMs are notorious for "hallucinating": producing confident-sounding answers that are entirely wrong. But with the right definitions, we can extract a semantic notion of "confidence" from LLMs, and this confidence turns out to be calibrated out-of-the-box in many settings (!)
@tiancheng_hu This makes sense, I would agree with that hypothesis! Do you have any intuition for why model merging preserves instruction tuning but improves calibration? (I will take a closer look at your paper after I am done with my ICLR reviews haha!)
Announcing 🔭✨Hubble, a suite of open-source LLMs to advance the study of memorization!
Pretrained models up to 8B params, with controlled insertion of texts (e.g., book passages, biographies, test sets, and more!) designed to emulate key memorization risks 🧵
We found a new way to get language models to reason. 🤯
No RL, no training, no verifiers, no prompting. ❌
With better sampling, base models can achieve single-shot reasoning on par with (or better than!) GRPO while avoiding its characteristic loss in generation diversity.
We (Moritz Hardt, @walesalaudeen96,@joavanschoren) are organizing the Workshop on the Science of Benchmarking & Evaluating AI @EurIPSConf 2025 in Copenhagen!
📢 Call for Posters: https://t.co/jeXRNDexuX
📅 Deadline: Oct 10, 2025 (AoE)
🔗 More Info: https://t.co/zZmkGzGsRg
Cursor made me a chrome extension which redirects any html arxiv links that you stumble across on the internet to the pdf version of the arxiv paper instead. Could be useful for some others, but use at your own risk! https://t.co/oJGScrtNBo
🚨 Position paper alert! 🚨
LLM uncertainty quantification (UQ) has been explored with the goal of enabling better reliance on LLMs by humans. However, we argue that common LLM UQ practices are detached from this human-centric aspiration.😭😭
https://t.co/P5g7Kco0xh
🚨 Position paper alert! 🚨
LLM uncertainty quantification (UQ) has been explored with the goal of enabling better reliance on LLMs by humans. However, we argue that common LLM UQ practices are detached from this human-centric aspiration.😭😭
https://t.co/P5g7Kco0xh