Here's a fascinating story of how researchers used Bloom filters cleverly to make SQLite 10x faster.
I'll also explain some database internals and how databases implement joins.
Let's dive in!
I've set up a simulation of a Rotman lens to drive a phased array in Elmer. The matching of the ports is poor, causing lots of internal reflections, resulting in unwanted side lobes and poor channel separation. Nonetheless I think it still demonstrates the principle nicely 😊
The recent wealth tax increase in Norway was expected to bring an additional $146M in yearly tax revenue
Instead, an estimated $54B-worth of ultra-rich left the country, leading to a lost $594M in yearly wealth tax revenue
A net decrease of $448M+
(sources and calculations ↓)
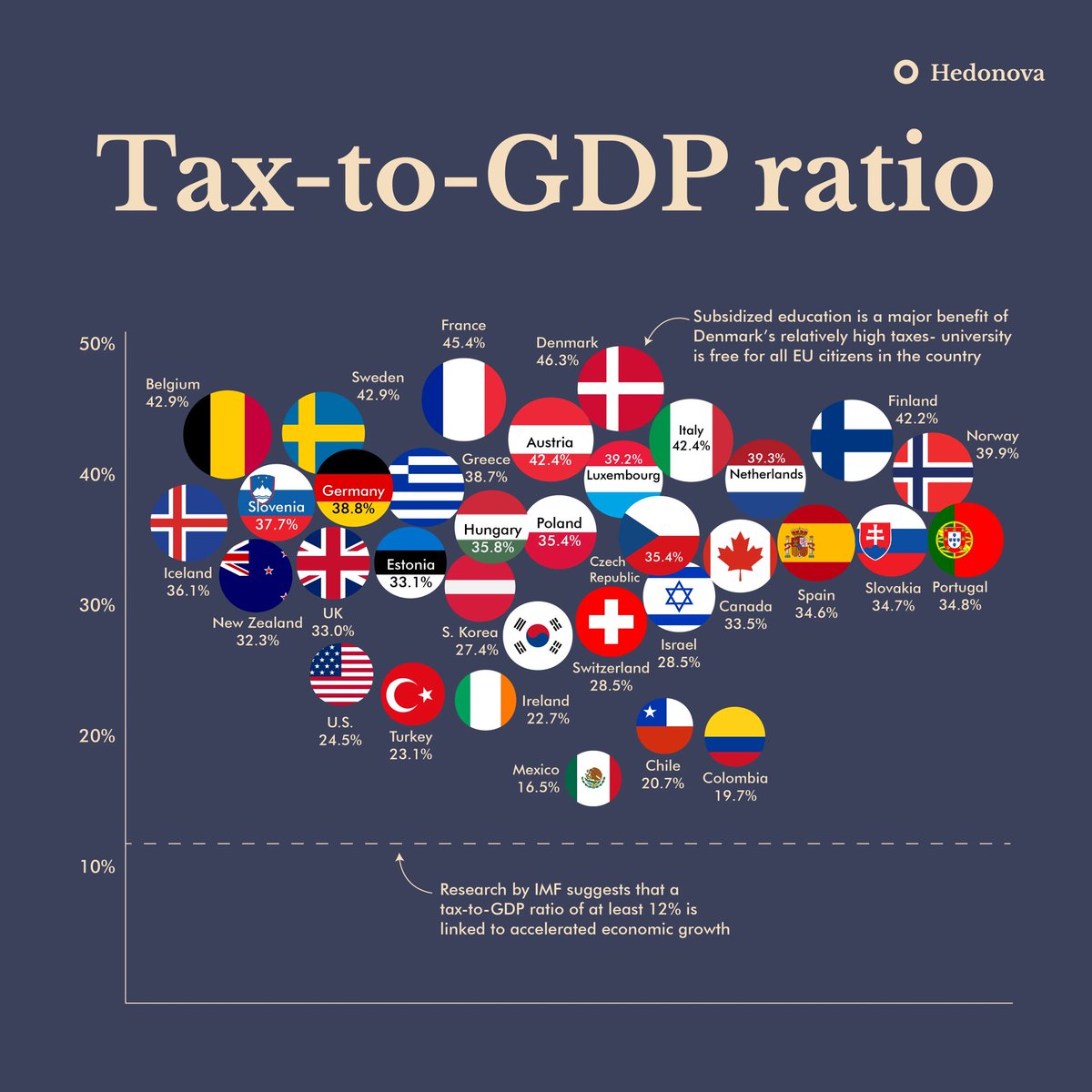
Capping tax rates at % of GDP won’t help because it highly depends on the social configuration of the country and goals.
If there is no “middle” class, it’s inevitable rise, from both reasons 😉.
So 20%-30% range rate and its dynamic seems like a good indicator exactly of the size of the “middle” class.
Everyone who thinks AI will replace software engineers are:
—VCs investing in those startups
—Founders / employees of those startups
—AI influencers who hype everything
—People who wish they majored in CS
—People who hate techbros
Real SWEs are like "well.. it's kinda helpful".
Almost one year later, and I’m sticking by this prediction. You can do some amazing things with in context learning and fine tuning of LLMs post-training, but there are currently limitations to adding new knowledge to LLMs post-training. If you have a large amount of private information and facts you want the model to understand, continued pre-training of a model with enough capacity will give better results (for a much higher price).
I feel like our industry has lost the plot when the prevailing theme is to get everyone into a single global security model.
Decentralization is about choice and local sovereignty. Build many security models that users can transparently compose.
@smlpth Mostly junior devs, and fake ones. 😉
With 4.0t is good at producing some decent HTML, CSS, andJS, any well-trained middle-level dev will understand tasks faster and better, mostly due to experience and context awareness.
yes, i am simping over this. this is what its all about. every modality is just a vessel/wrapper for the underlying Thing.
tear apart all the rules/structures of that modality and you're left with the raw concept.
i believe whether you hear someone's voice or see them you access the same mental concept of that person up to some variance/uncertainty
7/7 Surprizingly, transformer's architecture, with layers combining non-linear activation and *linear* heads, closely aligns with training non-linear models that generate linearizably-combinable embeddings.
However, too many unknowns for me to think really deeply about it.
Yes, the idea that blending several models, like 3.5 for video and optimized 4t for text, to get something intelligent seems wrong. Running models in parallel offers incremental progress. And it's now obvious that recent GPT release confirms that, nothing wrong about it. /1
It seems to me that before "urgently figuring out how to control AI systems much smarter than us" we need to have the beginning of a hint of a design for a system smarter than a house cat.
Such a sense of urgency reveals an extremely distorted view of reality.
No wonder the more based members of the organization seeked to marginalize the superalignment group.
It's as if someone had said in 1925 "we urgently need to figure out how to control aircrafts that can transport hundreds of passengers at near the speed of the sound over the oceans."
It would have been difficult to make long-haul passenger jets safe before the turbojet was invented and before any aircraft had crossed the atlantic non-stop.
Yet, we can now fly halfway around the world on twin-engine jets in complete safety.
It didn't require some sort of magical recipe for safety.
It took decades of careful engineering and iterative refinements.
The process will be similar for intelligent systems.
It will take years for them to get as smart as cats, and more years to get as smart as humans, let alone smarter (don't confuse the superhuman knowledge accumulation and retrieval abilities of current LLMs with actual intelligence).
It will take years for them to be deployed and fine-tuned for efficiency and safety as they are made smarter and smarter.
/6 The challenge shifts to another domain: Models generating linear models need a common vector space or coordinate transformations for optimal "map-reduce" like inference, ensuring combined predictions work well.
Once this is possible it can be traced back on a dataset & mapped to another model input because it's linear.
Karpathy's year-old tweet highlights that SVMs outperform k-nearest neighbors for relevant embeddings lookup. SVMs are *linear* models.
https://t.co/PFDqmgrn5n
Random note on k-Nearest Neighbor lookups on embeddings: in my experience much better results can be obtained by training SVMs instead. Not too widely known.
Short example:
https://t.co/RXO9xiOmAB
Works because SVM ranking considers the unique aspects of your query w.r.t. data.