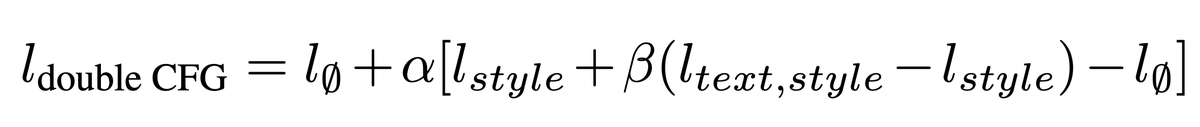Very happy to announce that my paper “Audio Conditioning for Music Generation via Discrete Bottleneck Features“ done with @honualx@adiyossLC@jadecopet and Axel Roebel has been accepted at ISMIR24.
Paper: https://t.co/2KwG6Bk1jH
Sample: https://t.co/Dkom70Eoie
Code: soon
Today at 10:30 at @iclr_conf I’ll be presenting CALM (Continuous Audio Language Models), the architecture behind Pocket TTS, @kyutai_labs’s 100M params TTS that runs on CPU.
Come chat with me if you want to build an audio LM without tokens
Paper: https://t.co/IR2vaZ0wxH
Super happy that our work on Continuous Audio Language Models (https://t.co/8KmdWlymUB) led us to build an outstanding 100M TTS with voice cloning ability that runs on any laptop CPU.
We’re excited to introduce Pocket TTS: a 100M-parameter text-to-speech model with high-quality voice cloning that runs on your laptop—no GPU required.
Open-source, lightweight, and incredibly fast. 🧵👇
Gradium is out of stealth to solve voice. We raised $70M and after only 3 months we’re releasing our transcription and synthesis products to power the next generation of voice AI.
1/2 We’re releasing an in-depth tutorial on neural audio codecs, the secret sauce that makes it possible for audio LLMs to not sound like a horror movie:
Kyutai Speech-To-Text is now open-source! It’s streaming, supports batched inference, and runs blazingly fast: perfect for interactive applications.
Check out the details here: https://t.co/bQMP56XaKC
Talk to https://t.co/1ZcGtCwvgx 🔊, the most modular voice AI around. Empower any text LLM with voice, instantly, by wrapping it with our new speech-to-text and text-to-speech. Any personality, any voice. Interruptible, smart turn-taking. We’ll open-source everything within the next few weeks.
Meet Hibiki, our simultaneous speech-to-speech translation model, currently supporting 🇫🇷➡️🇬🇧.
Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the source speech.
Based on objective and human evaluations, Hibiki outperforms previous systems for quality, naturalness and speaker similarity and approaches human interpreters. 🧵
``MusicGen-Stem: Multi-stem music generation and edition through autoregressive modeling,'' Simon Rouard, Robin San Roman, Yossi Adi, Axel Roebel, https://t.co/tGwJyDyRIH
Meet Helium-1 preview, our 2B multi-lingual LLM, targeting edge and mobile devices, released under a CC-BY license. Start building with it today!
https://t.co/X4Dbx2T1cJ
I am presenting our paper MusicGen-Style “Audio Conditioning for Music Generation via Discrete Bottleneck Features” at @ISMIRConf this afternoon. The code as well as the weights of the model are available on https://t.co/tSvrr446v3. You can now play with it!
Very happy to announce that my paper “Audio Conditioning for Music Generation via Discrete Bottleneck Features“ done with @honualx@adiyossLC@jadecopet and Axel Roebel has been accepted at ISMIR24.
Paper: https://t.co/2KwG6Bk1jH
Sample: https://t.co/Dkom70Eoie
Code: soon
Then we can as well use text and style conditioning to generate music, but we noticed that the model tends to ignore the text prompt. We then introduce a double classifier free guidance. This guidance could be applied to other multi-conditioned generative models.
``Audio Conditioning for Music Generation via Discrete Bottleneck Features,'' Simon Rouard, Yossi Adi, Jade Copet, Axel Roebel, Alexandre D\'efossez, https://t.co/Z01vzcESpi
#ICML2024 paper “An Independence-promoting Loss for Music Generation with Language Models”
We promote independence between EnCodec codebooks using a kernel trick and improve music generation quality 🎶
Paper 📜 https://t.co/Uyb1sIusze
Audio/Code 🔊 https://t.co/MFmdsOIrxo