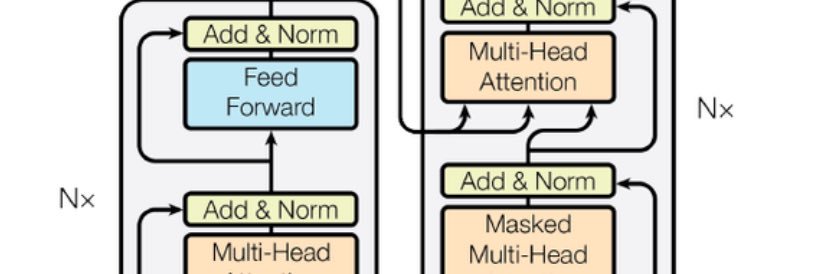
My recent blog with @hasgeek - “Decoding Llama3” is out.
It’s a deep dive into the Llama3 model code released in April this year. This is a fun blog with a code-first approach.
https://t.co/ZdRHB8hW2S

What does it mean to have dropout in Attention computation?
Dropouts are used to prevent overfitting.
In case of attention, we drop some attention scores, which means that if the model learnt to attend to some token, it now has to focus on other related tokens.
#LLM#Attention
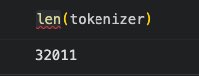
The tokeniser lies about how many tokens it holds ;)
What the tokeniser returns is the size of the base vocabulary that it learnt during training. Everything after that are special tokens.
Special tokens are like metadata and help structure context.
Trivial but worth a reminder use np.matmul for dot product instead of np. dot.
np. dot is meant to be a flexible function that will adjust according to the input shape, instead of raising an error.
Example np. dot(np.array([[1, 2], [3, 4]]), 10)
First, @simsimsandy walked us through GPU architecture, optimizations, CUDA, and the challenges of running large ML models on GPUs, with a special look at the attention mechanism, KV-Cache optimizations, and PagedAttention!
If you are into GenAI, @hasgeek is organizing a call today to build a community on #ResponsibleAI. Join for cross-learning.
🔗 Meeting Link: Register here to confirm your participation - https://t.co/R8WuiH76mS
🕰Time: 7 PM IST Friday, 28 June (tonight)
🚀Join us in Chennai next week for our hands-on workshop: "Building AI Agents with RAG and Functions" 🤖✨
Limited seats available, so hurry and secure your spot! 🏃♂️💨
🔗 Register now: https://t.co/DYaWnmkREp
#AIWorkshop#ChennaiEvents#llm#genai
@anscombes4tet@Aditi_ahj@fifthel .@simsimsandy introduced Bhumika Makwana @GalaxEyeSpace who will speak about multimodal fusion as the new game changer.
Reach out to Simrat for review and feedback on #nlp work, and for simplifying complex AI concepts. 3/5
Really fun video on the basics - dot prd and inner prd.
Also, potentially a great resource on Quantum Mechanics #QuantumSense YT channel.
https://t.co/McXTOSDOed
Inner product is an important concept for Rotary Positional Embedding, which is used by #LLM like #Llama3 (#Llama).