The 15th edition of the Lisbon Machine Learnings School (LxMLS 2025) is looking for its monitor team. As always alumni are especially welcome. Apply before the month ends!
https://t.co/Drw3Rypk7d
Funded PhD opportunity at the University of Birmingham.
I am recruiting a student to work on data-centric NLP. Reach out if you are interested in e.g.: active learning, curriculum learning, adversarial data collection, and evaluation for NLP and LLMs. https://t.co/NrIV1ItiKS
How much does data impact the evaluation of NLP models? How can we measure data distribution in an efficient and multi-dimensional way? How to predict OOD generalizability?
Check our paper with @mattlease - "Benchmark Transparency", accepted at NAACL (https://t.co/cK3Y4WTqVn)
The School of Computer science at UoB is inviting national and international candidates to apply for funded PhDs. The candidates can choose the area, topic, and supervisor. More info: https://t.co/hRuU24Alp9
@elneurozorro When thousands of arxiv papers are getting out, most of them get little attention. Large labs have many (and popular) members that share links to papers (regardless of quality), effectively filling the "reading bandwidth" of neutral readers.
Preprints should be: 1) accepted papers or 2) papers that will never be peer reviewed. 1) and 2) should be clearly marked.
If you are scared someone will steal your research - implement registration (e.g. OSF).
If your research will be irrelevant in 3 months - rethink it.
@elneurozorro It is a related issue and imo all stems from lack of patience and proper scientific approach. Conceptually, pre-prints are a great idea. In practice, they just fuel publishing frenzy and favor large labs that can attract more attention in the crazy article spam.
@elneurozorro I guess it depends on the scale. When it gets to hundreds of papers published every day, it becomes an unbearable spam of scientific clickbaits and "fast food" research that is obsolete in a month. It tolerates a culture of quantity over quality, which is unhealthy.
Reading a rebuttal where the authors have relied heavily on LLMs to "polish their writing". 2 page rebuttal with 0 meaningful content. Should I lower the score as they wasted 30 minutes of my time or give them an extra point for making me laugh on a Friday?
At Dynabench, we're gearing up for the AI race, and we embrace the rapid pace of change! We're excited to announce some big updates that make our new-and-improved platform faster, better, and easier to use, for leaderboard users, dataset creators, and benchmark owners! 1/7
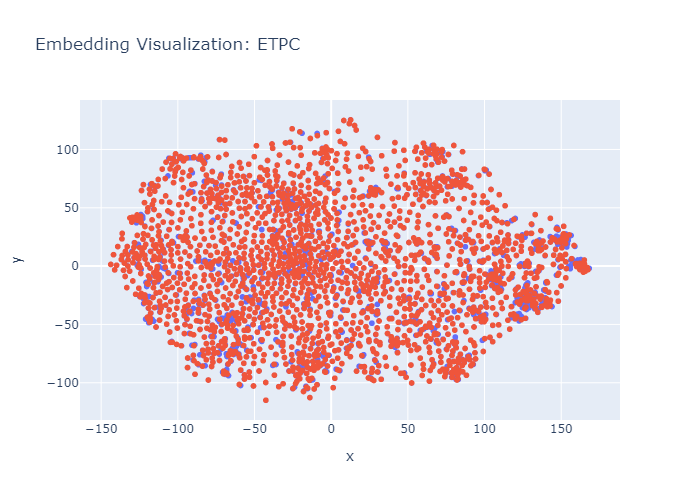
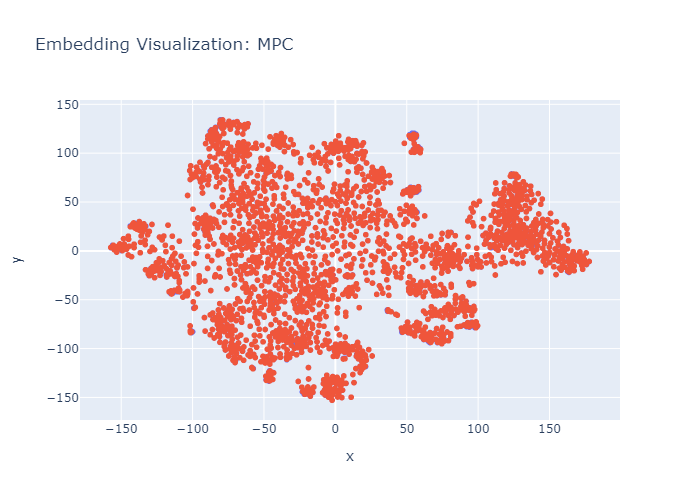
Embeddings t-SNE vizualizations of paraphrase datasets show: There are big differences in semantic balance.
Left: ETPC (human) by @sintelion
Right: MPC (machine) by @jpwahle
Research still lacks evenly distributed paraphrase datasets by machines!
https://t.co/KL0stgZKIL
New lit review: @d_anubrata, @sintelion, & Houjiang Liu call for human-centered NLP for fact-checking: "The state of human-centered NLP technology for fact-checking." Information Processing & Management, 60(2), 2023 https://t.co/s0QAX1dpvv @UTiSchool@EngagingNews@UTGoodSystems
@KhalilMrini The wording of the prompt matters! If I ask it for "wiki article on ...", I'm also a football player. If I ask it to "write an article on ..." I am suddenly a "little known Bulgarian poet".