thread of ui ideas for claude code, codex and cowork type products
warning long-ish, 31 tweets
lmk if there's one you particularly like
1/ what if the websearch tool in coding agents had a more thorough status display:
(Linear) Attention Mechanisms as Test-Time Regression
By now, you've probably already heard of linear attention, in-context learning, test-time scaling, etc...
Here, I'll discuss:
1. The unifying framework that ties them all together;
2. How to derive different linear attention variants from scratch; and
3. How to parallelize training linear attention models
Introducing 🧞Genie 2 🧞 - our most capable large-scale foundation world model, which can generate a diverse array of consistent worlds, playable for up to a minute. We believe Genie 2 could unlock the next wave of capabilities for embodied agents 🧠.
Perhaps this is what translation tasks look like in the new era, and maybe this is the charm of large-scale pre-training. Perhaps, in the context of large-scale synthetic data, the critical factor is the underlying rule governing data generation, rather than the content itself?
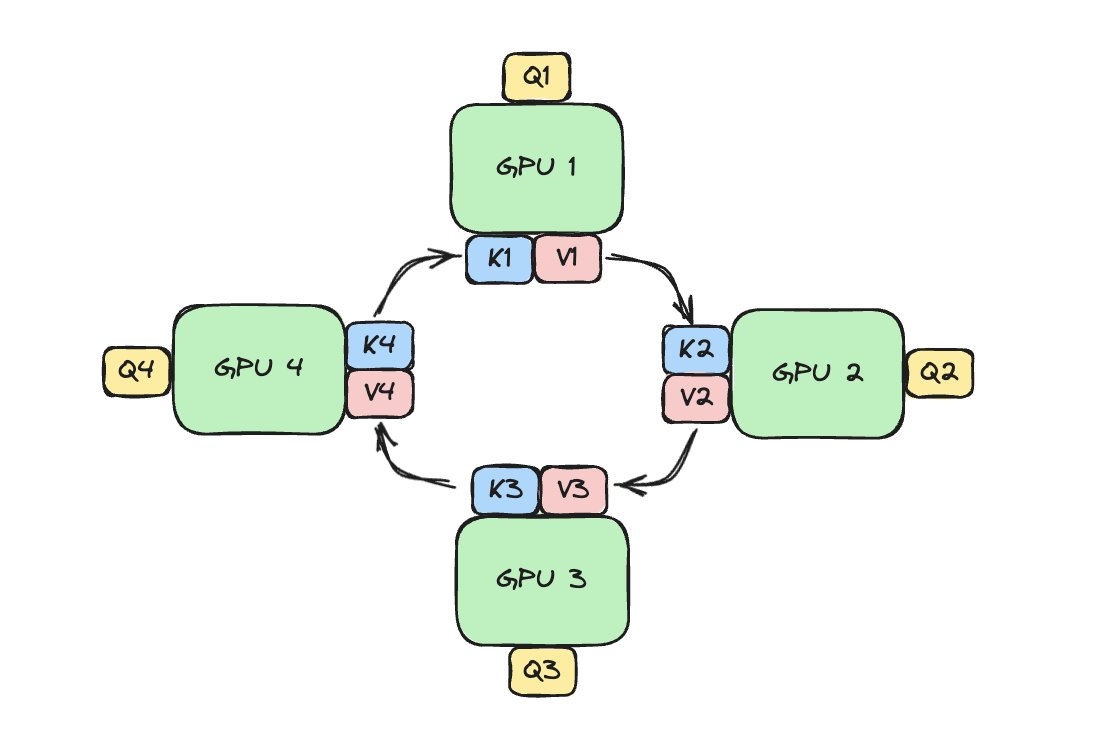
How do LLMs scale to million token context window? Ring Attention is a nice trick to parallelize long sequence across devices and rotate them in a ring with zero overhead scaling.
In our new blog, we cover the tricks behind this magic. It looks like this (1/5🧵)
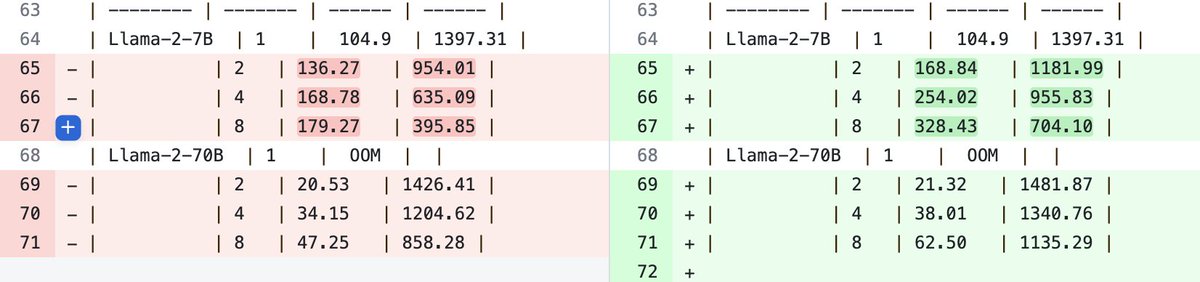
Two additions to gpt-fast this week. The first one is an optimization to tensor-parallelism added by @foofoobuggy which improves our TP perf by 20-50%.
This gives us 200 => 330 tok/s for Llama-7B fp16 and 64 => 91 tok/s for Llama-70B int4 with *no* speculative decoding.
(1/4)
Very cool dataset
BTW, recently, I tried ChatGPT 4 on Caribou Contest (online Canadian math Olympiad) tasks for Grade 2 and Grade 7-8 (I photographed each problem from screen)
To my surprise, it solved only 1 out of 8 for Grade 1 and 9 out of 14 for Grade 7-8. The problem is that practically all of the problems for lower grades are visual and almost all of the problems for upper grades are textual. Turns out GPT4 is great at OCR but poorer at precise object classification and abstracting higher-level concepts from images
Can be a nice way to test multi-modal models. I’ll be happy if someone develops this further
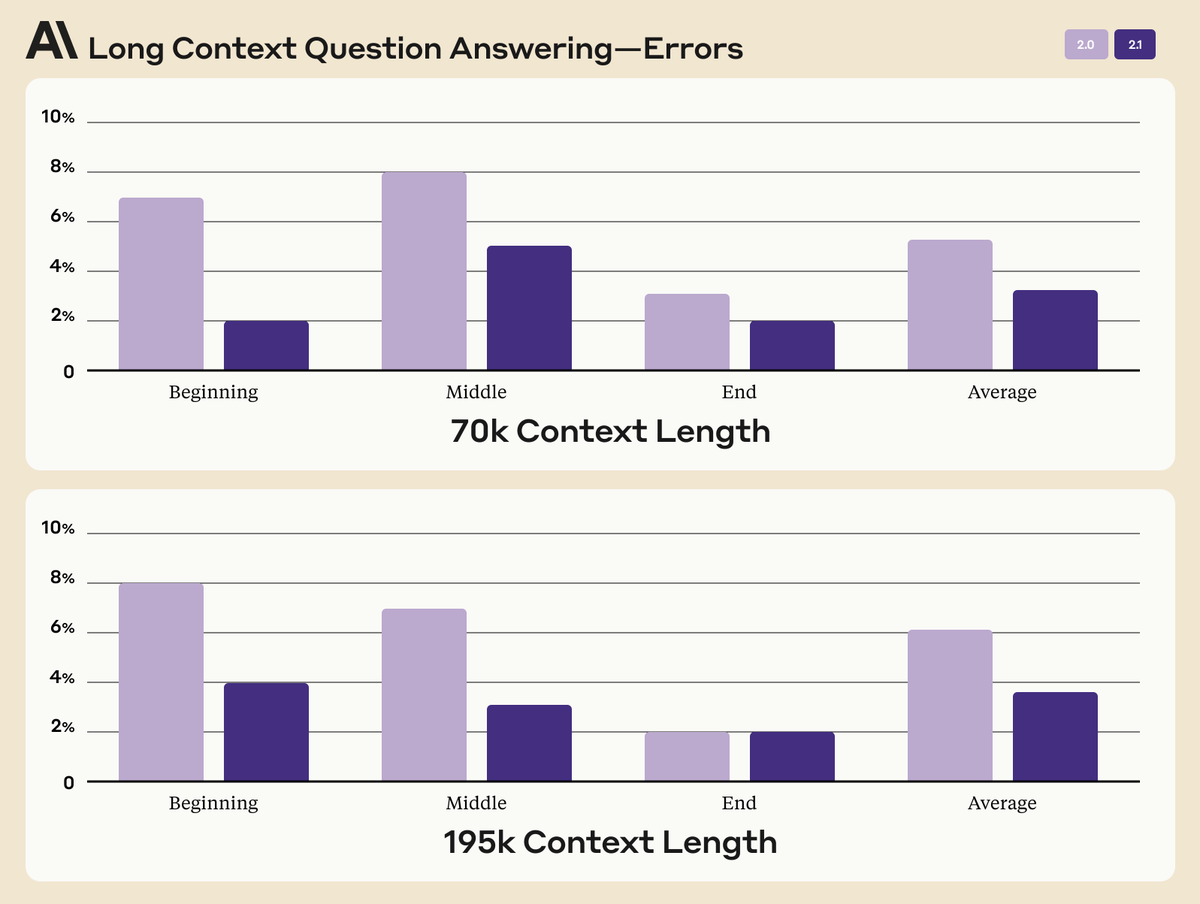
Instead of taking OAI's merger offer, Anthropic launched major updates for Claude 2.1🎉. I think the below chart is the most interesting: this is how all LLM papers that claim "long context" should report: error rates on "Beginning", "Middle", and "End".
There're a bunch of papers making wild claims, all the way up to "1B context tokens". Here's a friendly reminder that the 30-year-old LSTM literally supports infinite context. It's a meaningless number unless you show detailed evaluations at different locations in the context. LLMs tend to be "Lost in the Middle", i.e. struggle to remember and reason on information at the middle section of the context window: https://t.co/8Lcr1NNf9h
Claude 2.1 also claims "2x hallucination" - please take this with a BIG grain of salt. A while back, I expressed my concerns about Vectara's benchmarking protocol. Same concerns apply here too.
The trivial solution to achieve 0% hallucination is simply refusing to answer every query. One cannot claim victory here without a careful Safety vs Usefulness analysis. How many questions that Claude used to answer correctly are now rejected?
In any case, kudos to Dario & Anthropic team on assuring us a solid alternative during turmoil! 🩷https://t.co/ZvXXfAPAKD