Appreciate the shoutout, Tiezhen! 🙏
The team is thrilled to see PP-OCRv6 holding the top 17 spots on the HF leaderboard. A rare milestone for us, and we couldn’t have done it without this incredible open-source community.
Keep the feedback coming! 🚀
@ma_sc_@PaddlePaddle Got it. A 100% reproduction rate on English and Italian is a strong signal for us. Thank you for such a solid batch of feedback. I'll have the team spin up a dedicated test using your flyer samples. Appreciate your help in making PP-OCRv6 better!
@pabis_eu@PaddlePaddle The models you mentioned are VLMs tailored for document OCR, rather than natural scene images. PP-OCRv6, on the other hand, is designed to handle text spotting in natural images. They belong to different technical paradigms.
@ma_sc_@PaddlePaddle Glad you like the model! I’m the tech lead for PaddleOCR. This word-merging issue is a known pain point. Which version are you currently on? We are making sure PP-OCRv6 addresses this spacing problem.
Big update! 🎉 From now on, PaddleOCR inference is completely decoupled from the PaddlePaddle framework. You now have the absolute freedom to choose ONNXRuntime or PyTorch! 🚀
🚀 PaddleOCR 3.7 is here — ONNX Runtime now supported!
🔥 One parameter to switch inference backends. Zero code changes.
📊 What's new:
🔸ONNX Runtime backend: cross-platform, lightweight, multi-hardware acceleration.
🔸Multi-hardware support: CPU via OpenVINO, GPU via CUDA & TensorRT.
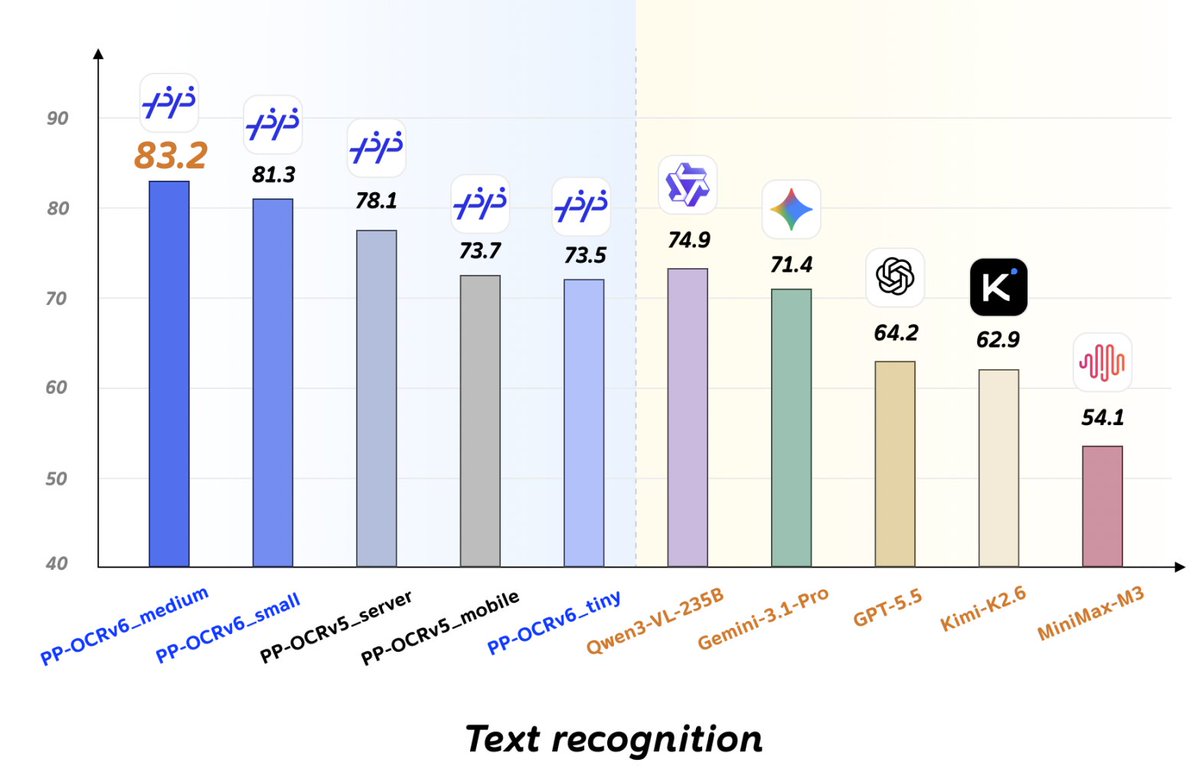
🔸PP-OCRv6 also onboard: Tiny / Small / Medium — up to 3.9× faster on CPU.
✨ From servers to edge devices — flexible deployment, your choice of engine.
🔗 Try it:
🌐 https://t.co/qf6cyafiqY
💻 https://t.co/oNOfB6hbSY
📖 https://t.co/yq12V9Ojhq
#PaddlePaddle #PaddleOCR #OCR #ONNX #ONNXRuntime
@AI_Jasonyu Thanks everyone for your interest in PaddleOCR! I’m the tech lead of PaddleOCR. I haven't been very active on X in the past, but I'm planning to share more technical insights and updates here moving forward. Stay tuned! 🐼
PP-OCRv6 released! Forget heavy VLMs for dedicated OCR. We've completely rewrote the rules of speed and efficiency!
97ms latency per image running locally in Web browsers! Absolute real-time response.
Drop a ⭐️ and clone it now! 👇 Repo Link: https://t.co/WEAlRNxEru
PaddleOCR just hit 80K STARS.
Kudos to the team! @slimcat0101@liuyi_ai@PaddlePaddle
Recently we released PaddleOCR-VL-1.6, and is preparing the release of pp-ocr-v6. Looking ahead, we’re excited to push the boundaries of Document AI further.
🔗 https://t.co/J96qILm8cL
Milestone! 🏆 PaddleOCR is now the #1 starred OCR repo on GitHub, surpassing Tesseract.
As the tech lead, I’m beyond thrilled! From a single line of code to a global choice—our mission remains "AI for everyone." Huge thanks to our 70k+ community. Let’s keep building! 🚀✨
@Zai_org Great work! I am Cheng Cui, the author of PaddleOCR-VL-1.5 and PP-DocLayoutV3. Thanks for using the PP-DocLayoutV3 model from PaddleOCR-VL-1.5. Let’s make document intelligence even better together!
@uptonking2@PaddlePaddle There can indeed be some challenges when using a two-stage model with frameworks like Ollama. Therefore, we offer a completely offline docker image for your convenience. Feel free to deploy it with a single click. Here is the documentation: https://t.co/wga8eaoFZq
@getpochi@PaddlePaddle We will strive to ensure that the PP-DocLayout model in the first stage is as accurate as possible. Of course, the capabilities of this model are continuously being optimized.
@rryssf Hey everyone, as the person in charge of this project, I saw this post and had to drop a comment! We’d love for you to give it a try. Your feedback is crucial—it’s what helps us make the tool better for everyone.😀