Gemma 4 is a very good small model that punches above it's weight class
Gemma is a 31B model that is as good as other very large MoE models
It's the best in the world for it's size 👏👏
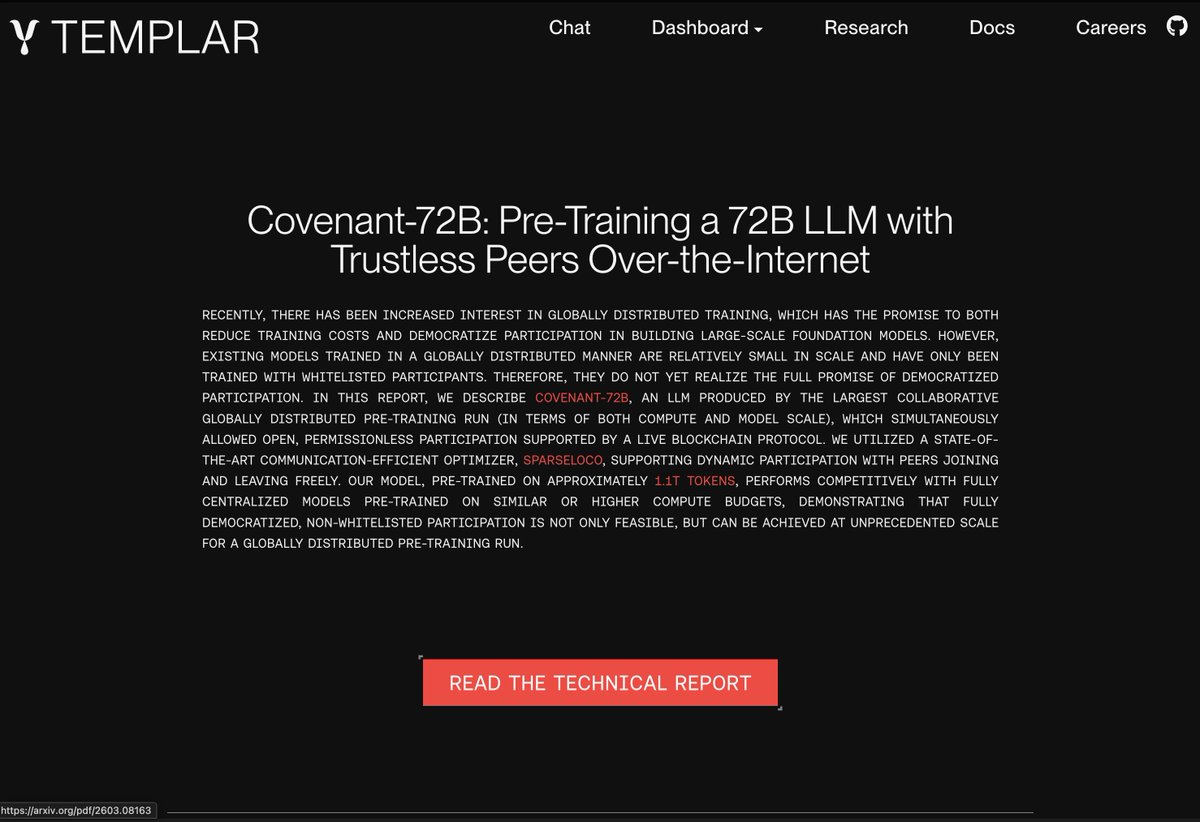
This didn't receive the attention it deserved. They pre-trained this model completely peer 2 peer, no data-centers.
Everything was done over a permissionless network, I have tried the model, it's honestly not a good LLM but that's beyond the point.
We NEED this, we NEED an alternative.
- Download OpenCode
- Download Pi
- Pay for OpenSource
- Share your AI sessions
- Learn to do RL
We can't be at the mercy of ANY lab.
https://t.co/6ruL2lz2Dh
Qwen3.5, MiniMax-M2.7 are incredible acts of kindness that I don't think will be with us from so much longer.
Here's my update for you.
> I have 20 GPUs at full utilisation right now.
All these getting cooooompressed, no synthetic data
All runs will be done in 9 days, if I don't get a catastrophic failure - REAP for:
- GLM-5
- Qwen3-next-coder
- Qwen3.5-122B
- Qwen3.5-plus-397b
- Browser-use
- CUDA
- Terminal-use
- Coding
- Math
- Agentic trajectories
- 30% my personal chat session history
I am also removing refusals inspired by Prism. So no more I can't do this I can't do that blah blah
Inference for local AI
- Qwen3.5-262B-REAP - I've been using it exclusively in Parchi, perfect 100 tokens/s & 0 errors very good at browser use
-----------------
Secret
- Qwen3.5-27b - you will see when i'm done
Targeting the following hardware levels:
With full context 200-256k context in vllm, sglang, llama.cpp, exllamav3, and if people help MLX
16-32 GB - Qwen3.5-27b
32-48 GB - Qwen3-coder-next
48-128 GB - Qwen3.5-122B
128-256 GB - Qwen3.5-Plus-397B
196-512 GB - GLM-5.*
I am training them on 22,000 samples at 16k context
352M of custom selected calibration datasets.
My hope is to make the highest quality multimodal LLM compressions for this year.
20 GPUs running in parallel for the next 10 days
- 8x H100s - Qwen
- 4x B200s - GLM-5.*
- 8x 3090s - Testing
Once MiniMax-M2.7 is online 4 more GPUs will get to work.
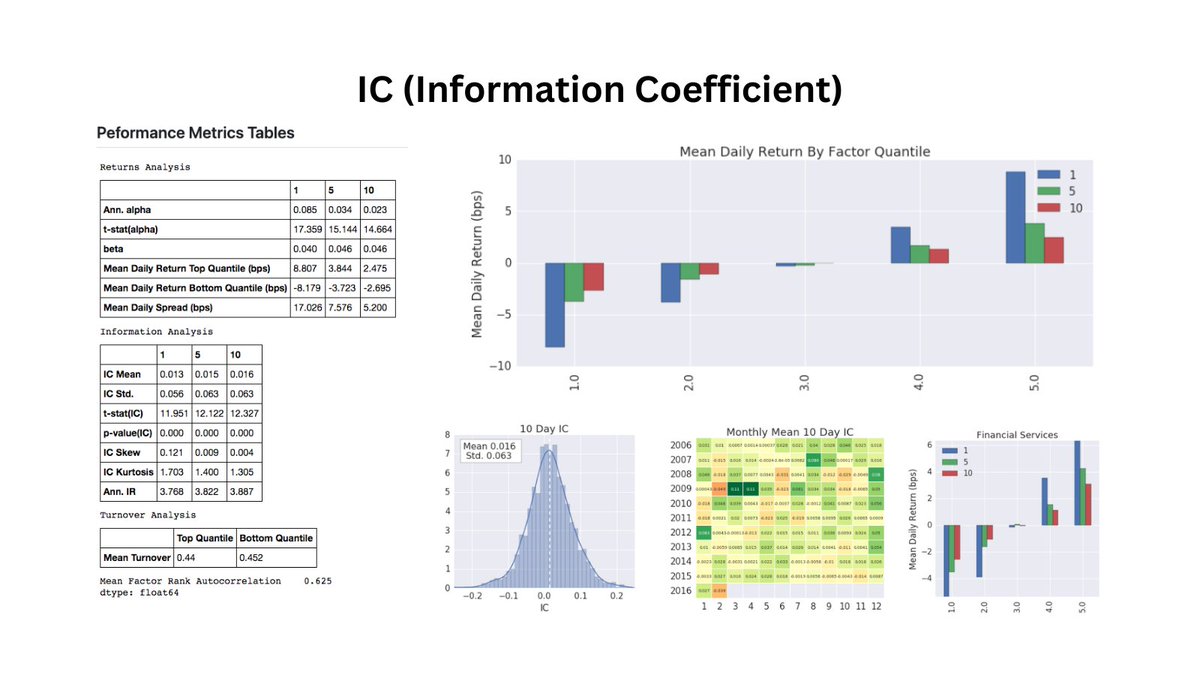
Factor investing is what made me stand out at JPMorgan.
But it took me years to master the information coefficient.
In 1 minute, I'll teach you the 10 things you need to know (that took me 1 year to learn).
Let's go: