예전엔 Claude Code한테 큰일 하나 던지면 혼자 계획 세우고, 코드 짜고, 검사하고, 기억까지 다 해야 했음.
Dynamic workflow는 그걸 Claude가 즉석에서 “작업반”으로 쪼개게 만드는 기능에 가까움. 한 놈은 조사하고, 한 놈은 고치고, 한 놈은 검수하고, 필요하면
다른 모델이나 별도 작업공간까지 붙이는 식.
그래서 진짜 변화는 “Claude가 더 많이 생각한다”가 아니라, 큰 작업을 끝까지 밀어붙이는 구조를 Claude가 스스로 짜기 시작했다는 쪽임.
again saying there's never been a better time to work on multi-agent systems.
learn rag, orchestration, evals, memory, routing, tool calling, validation loops, fix loops, split learning, context engineering. all of it.
getting an llm to answer questions is becoming the easy part
getting multiple agents, tools, and workflows to work together reliably in production without breaking every other day is where the real challenge is.
we're entering a phase where building the model matters less than building everything around it.
A harnessed LLM agent, clearly explained!
Most people picture this as a model with tools bolted on. The real architecture inverts that relationship.
The model itself is deliberately thin. Intelligence gets pushed outward, and the harness composes it at runtime.
Three dimensions orbit the harness core:
- 𝗠𝗲𝗺𝗼𝗿𝘆 holds the state a model shouldn't carry in weights or context. Working context, semantic knowledge, episodic experience, and personalized memory each have their own lifecycle.
- 𝗦𝗸𝗶𝗹𝗹𝘀 hold procedural knowledge. This can cover operational procedures, decision heuristics, and normative constraints that specialize the general model per task.
- 𝗣𝗿𝗼𝘁𝗼𝗰𝗼𝗹𝘀 hold the interaction contracts. Agent-to-user, agent-to-agent, and agent-to-tools are three distinct surfaces with their own failure modes.
Between the core and these modules sit the mediators, like sandboxing, observability, compression, evaluation, approval loops, and sub-agent orchestration.
They govern how the harness reaches out and how state flows back in.
The useful question this framing unlocks is: for any new capability, where should it live?
- Stable knowledge goes to memory
- Learned playbooks go to skills
- Communication contracts go to protocols
- Loop governance goes to the mediators
Harness design becomes a question of what to externalize, and how to mediate it.
I'm building a minimal agent harness from scratch and will open-source it soon.
In the meantime, my co-founder wrote an article about the anatomy of Agent Harness, covering the orchestration loop, tools, memory, context management, and everything else that transforms a stateless LLM into a capable agent.
Read it below.
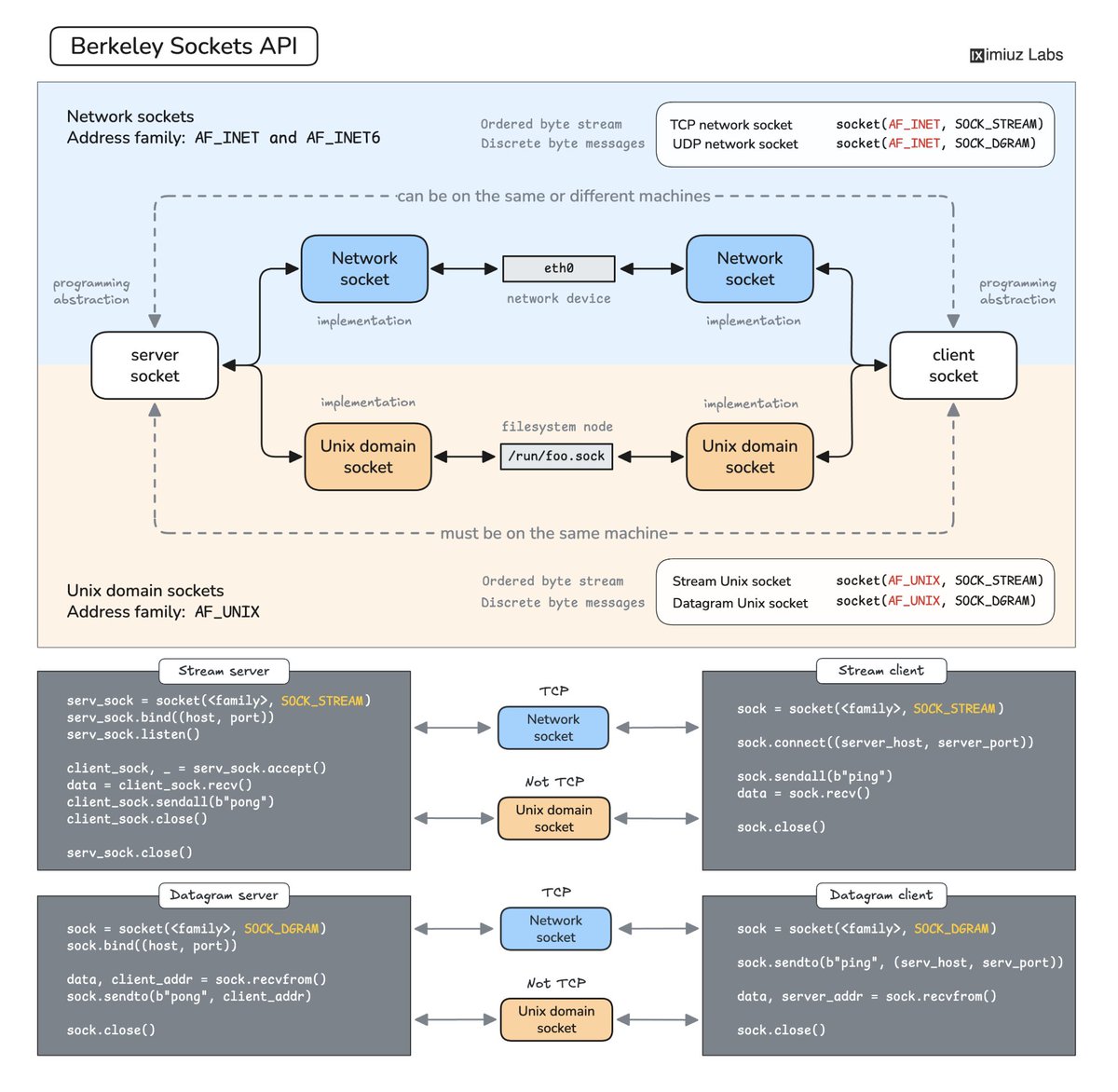
The best way to understand how servers actually work is to write a couple of them from scratch. I prepared a series of exercises that help you get started with socket programming in C, Python, and Go:
- Write a TCP client for a telemetry server https://t.co/OH9JHuE81i
- Write a TCP client for a chat server https://t.co/ukwPsC9bCb
- Write a TCP echo server from scratch https://t.co/yZTvQoId63
- Make one echo server work with both TCP and Unix sockets https://t.co/D2ot5e7tJn
Happy hacking!
How Servers Work: A Hands-On Introduction to TCP Sockets 🧙♂️
Hot off the press! Learn how servers actually work by building a tiny TCP server and client from scratch. Traditionally, with a bunch of visual explainers and practical challenges:
https://t.co/9VzdxjTv5t
MCP stands for Model Context Protocol. It is an open-source standard created to help AI models securely connect to external tools, data sources, and software systems.
Most engineers using MCP can't explain what's actually happening on the wire.
They've cloned a repo, run a server, watched it work. Ask what `initialize` does, or why the token bill quietly doubled after they added a few servers, and the conversation gets short.
So I mapped the entire protocol. One image. Save it.
𝗪𝗵𝘆 𝗶𝘁 𝗲𝘅𝗶𝘀𝘁𝘀
Before MCP: N models × M tools = a custom bridge for every pair.
With MCP: N + M. One protocol in the middle.
𝗧𝗵𝗲 𝘁𝗵𝗿𝗲𝗲 𝗿𝗼𝗹𝗲𝘀
Host is the app you use. Client lives inside the host. Server is your code, exposing capability.
Underneath: JSON-RPC 2.0. Nothing exotic.
𝗧𝗵𝗲 𝘁𝗵𝗿𝗲𝗲 𝗽𝗿𝗶𝗺𝗶𝘁𝗶𝘃𝗲𝘀
Tools — model-controlled. The AI decides when to call.
Resources — app-controlled. The app pushes context.
Prompts — user-controlled. The user invokes them.
𝗧𝗵𝗲 𝗽𝗮𝗿𝘁 𝗻𝗼𝗯𝗼𝗱𝘆 𝘁𝗮𝗹𝗸𝘀 𝗮𝗯𝗼𝘂𝘁
Every tool schema travels in every LLM call. 50 tools = 50 schemas, every turn.
OAuth across many servers becomes real secret rotation work.
Tool sprawl is the new microservices sprawl.
Schema drift breaks agents silently.
MCP isn't a framework. It's a protocol. Mental model is HTTP, not LangChain. Boring, foundational, slowly everywhere.
Save the graphic for the next time someone asks how MCP actually works.
Credit: codewithbrij
AI in SRE is here! Google just open-sourced how they keep 5 billion people online.
This is Google SRE. The team that invented Site Reliability Engineering 20 years ago. Every major tech company copied their model. Now they just published exactly how they are rebuilding it with agentic AI.
Here is what their agents are doing inside Google right now:
→ When something breaks, AI agents pull observability data, run through playbooks and fix the issue autonomously before the on-call engineer even gets paged
→ AI agents monitor every live incident, write postmortems automatically and generate engineer handoff documents without a human touching anything
→ A system called AI Insights continuously reads every past Google incident ever recorded and feeds those lessons to agents so they get smarter after every single outage
→ Anomaly detection agents learn normal behavior patterns instead of using static thresholds and alert only when something actually looks wrong
→ Every agent has its own identity, its own permissions, its own reliability SLO and its own backup plan. Google treats AI agents exactly like human engineers.
They published the full architecture as a free white paper.
If Google is rebuilding a 20 year old discipline from scratch with agentic AI, every engineering team on earth is already behind and most do not know it yet.
Full playbook here:
https://t.co/qNDOaKORYA
🚨 𝟔 𝐓𝐲𝐩𝐞𝐬 𝐨𝐟 𝐋𝐋𝐌𝐬 𝐩𝐨𝐰𝐞𝐫𝐢𝐧𝐠 𝐭𝐨𝐝𝐚𝐲’𝐬 𝐀𝐈 𝐚𝐠𝐞𝐧𝐭𝐬
1️⃣ 𝐆𝐏𝐓 – 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐏𝐫𝐞-𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐓𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐞𝐫
(𝑇ℎ𝑒 𝐺𝑒𝑛𝑒𝑟𝑎𝑙𝑖𝑠𝑡)
Trained on massive datasets, these autoregressive models are the foundational engines for writing, reasoning, coding, and open-ended conversation.
➜ Highly versatile across diverse domains
➜ Excels at zero-shot and in-context learning
➜ The ultimate foundation for downstream fine-tuning
2️⃣ 𝐌𝐨𝐄 – 𝐌𝐢𝐱𝐭𝐮𝐫𝐞 𝐨𝐟 𝐄𝐱𝐩𝐞𝐫𝐭𝐬
(𝑇ℎ𝑒 𝑆𝑐𝑎𝑙𝑒𝑟)
Instead of activating the full neural network, MoE uses sparse routing to send each input only to the most relevant subset of "expert" sub-networks.
➜ Radically higher compute efficiency during inference
➜ Scales seamlessly to trillions of parameters
➜ Achieves deep specialization without sacrificing overall performance
3️⃣ 𝐕𝐋𝐌 – 𝐕𝐢𝐬𝐢𝐨𝐧-𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝑀𝑢𝑙𝑡𝑖𝑚𝑜𝑑𝑎𝑙)
Combines advanced vision encoders with language models to natively process and reason over spatial data—like images, complex diagrams, and video streams.
➜ Understands deep visual and spatial context
➜ Perfectly aligns pixel data with semantic text
➜ Enables rich multimodal tasks (like visual QA and image-based telemetry)
4️⃣ 𝐋𝐑𝐌 – 𝐋𝐚𝐫𝐠𝐞 𝐑𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝑇ℎ𝑖𝑛𝑘𝑒𝑟)
Built for "System 2" thinking. Optimized for multi-step reasoning, logical problem-solving, and planning through explicit verification and self-correction loops.
➜ Elite mathematical and logical planning
➜ Drastically reduced hallucinations through step-by-step verification
➜ Excels at complex, highly constrained problem-solving
5️⃣ 𝐒𝐋𝐌 – 𝐒𝐦𝐚𝐥𝐥 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝐿𝑖𝑔ℎ𝑡𝑤𝑒𝑖𝑔ℎ𝑡)
Compact, highly optimized models engineered specifically for edge devices, offline execution, or highly cost-sensitive environments.
➜ Ultra-low latency and blazing-fast inference
➜ Highly cost-effective to deploy and maintain
➜ Ensures data privacy through strictly on-device processing
6️⃣ 𝐋𝐀𝐌 – 𝐋𝐚𝐫𝐠𝐞 𝐀𝐜𝐭𝐢𝐨𝐧 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝐷𝑜𝑒𝑟)
Designed not just to generate text, but to execute real-world tasks using tools, APIs, and external environments. It operates on a continuous agent loop:
🔄 Plan ➟ Action ➟ Observation ➟ Reflect ➟ Update Memory
➜ Autonomous real-world execution
➜ Native integration with external systems and software
➜ Dynamically adapts to environmental feedback
Agents aren’t just chatbots anymore. They see, act, reason, and run anywhere from cloud GPUs to edge devices. 𝐶ℎ𝑜𝑜𝑠𝑖𝑛𝑔 𝑡ℎ𝑒 𝑟𝑖𝑔ℎ𝑡 𝐿𝐿𝑀 𝑡𝑦𝑝𝑒 𝑑𝑖𝑟𝑒𝑐𝑡𝑙𝑦 𝑖𝑚𝑝𝑎𝑐𝑡𝑠 𝑐𝑜𝑠𝑡, 𝑙𝑎𝑡𝑒𝑛𝑐𝑦, 𝑟𝑒𝑙𝑖𝑎𝑏𝑖𝑙𝑖𝑡𝑦, 𝑎𝑛𝑑 𝑟𝑒𝑎𝑙‑𝑤𝑜𝑟𝑙𝑑 𝑐𝑎𝑝𝑎𝑏𝑖𝑙𝑖𝑡𝑖𝑒𝑠.
Cc : Author
For curious developers 🧠
I built "The Anatomy of an LLM", an interactive explainer showing how text becomes tokens, vectors, attention, transformer blocks, and finally generated text.
https://t.co/fgCeZuQwJf
📉 El fin de "leer el código": La herramienta Open Source que destruye los SaaS de documentación?
Llegas a un nuevo equipo. El código tiene 200,000 líneas. Tu Tech Lead te dice: "ve leyéndolo para entenderlo". Abres 400 archivos, te abrumas y cierras la laptop. Pierdes tres días leyendo código que no te enseña nada sobre el sistema real.
Understand-Anything (44.4k estrellas) acaba de solucionar esto para siempre. Es un pipeline multi-agente que analiza todo tu repositorio y lo transforma en un mapa de conocimiento interactivo donde puedes clicar, hacer zoom y preguntar lo que quieras.
Lo que cambia las reglas del juego:
🧠 Pipeline Multi-Agente: Lee cada archivo, función y dependencia para entregarte un dashboard visual donde cada nodo te da un resumen en texto plano.
🎯 Domain View: No te muestra carpetas aburridas; mapea tu código según la lógica de negocio y los flujos reales del producto.
💬 Preguntas con Contexto: Puedes escribir directamente: "¿Dónde ocurre la autenticación?" o "¿Qué llama a esta función?" y te lleva al punto exacto.
🔌 Integración Total: Funciona de forma nativa como plugin para Claude Code, Cursor, Copilot y Gemini CLI.
La gran diferencia con el resto: La mayoría de las herramientas generan diagramas complejos que solo sirven para impresionar en una presentación, pero no te ayudan a resolver un bug el lunes por la mañana. Este mapa está diseñado exclusivamente para enseñarte cómo encaja cada pieza.
SaaS como Swimm o Mintlify te cobran cientos de dólares al mes y obligan a subir tu código a sus servidores.
Understand-Anything: $0. Cualquier tamaño. En tu máquina local. Privado y libre para siempre (Licencia MIT).
El Siguiente Nivel (Idea para Builders):
CI/CD Auto-Docs: Un GitHub Action que regenere el mapa visual en cada Pull Request para ver el impacto del cambio antes de mergear.
Onboarding Vectorial: Conectar el grafo a un bot de Slack para que los nuevos devs pregunten dudas de la arquitectura y el bot les devuelva la ruta visual exacta.
Enlace al repositorio en los comentarios. Guarda este post en marcadores antes de que se pierda en el feed 🔖
Claude Code 공식 보안 플러그인 공개!
💻 /plugin install security-guidance@claude-plugins-official
이거 실시간 검증됨 👍🏻 저도 방금 이걸로 바로 설치했어요. 코드 취약점 대응은 필수죠!
security-guidance 이건 보안 취약점을 실시간으로 찾아내고, 수정까지 도와주는 도구예요.
PR 까지 갈 필요 없이 편집할 때 바로 잡아주는거..!
파일을 편집할 때 +모델 턴이 끝났을 때 + 커밋할 때.. 이렇게 동작합니다.
주변 맥락까지 고려해 잠재적 취약점을 검증하는게 진짜 좋음..
Anthropic 내부에서 실제로 써보니,, 보안 관련 PR 코멘트가 30~40% 줄었다고 합니다!
혹시 개인/팀마다 고유한 규칙을 추가하고 싶다면, 저장소에 claude-security-guidance.md 이거 적용하면 됨.
돈 주고도 듣기 힘든 샌프란시스코 이야기.
그렉은 5일간 프론티어 AI 팀, 스타트업 창업자, 억만장자 3명을 만나고 돌아왔고,,
빌더들이 실제로 무슨 대화를 나누는지, 어떤 개념이 부상하고 있는지를 담음.
Forward-deployed engineer, Obsidian, agent debt.. 이런 키워드들.. 꼭 읽어보시길!
💬
1. 억만장자 3명은 SaaS를 사서 에이전트 퍼스트로 재건 중임.
eBay 딜에서 영감을 받은 공식: 회사 인수 → 인력 감축 → 기술 재건 → 에이전트 추가 → 가격 인상
2. 프론티어 모델 회사들은 실제 워크플로우에 목마름. API 호출 수와 토큰 수는 볼 수 있어도 실제 흐름은 못 봄. 특정 니치에서 모델을 독특하게 쓰고 있다면 그 이해 자체가 알파임.
3. 컨슈머 AI는 심각하게 미개척 상태. SF 빌보드는 전부 B2B 인프라 아니면 버티컬 에이전트. 그 사이 Cal AI는 18개월 만에 $50M ARR 달성. 엔터프라이즈에만 눈이 쏠린 사이 컨슈머는 비어 있음.
4. MCP는 모든 대화에서 나왔음. 새로운 SEO임. 제품을 MCP 엔드포인트로 노출한 회사들은 피칭하지 않은 딜에 끌려 들어가고 있음. MCP가 없으면 에이전트에게 보이지 않음. 에이전트에게 보이지 않으면 존재하지 않는 것과 같음.
5. 핫한 시드 라운드는 $25-50M 밸류에이션이 기본. Series A가 $450M인 케이스도 봤음.
6. "Forward-deployed engineer"가 SF에서 가장 핫한 역할임. 에이전트와 고객 사이에 앉아서 실제로 돌아가게 만드는 사람. 이 단어가 안 나온 대화가 없었음.
7. 오픈소스 분위기가 바뀜. 모델 충성도가 거의 사라짐. 1년 전만 해도 오픈소스는 프론티어를 쫓는 느낌이었음. 지금은 창업자들이 Gemma, DeepSeek이 필요한 것의 80%는 훨씬 저렴하게 커버한다고 말함. "어떤 모델?" 대신 "어떤 태스크에 어떤 모델?"이 질문의 형태가 됨.
8. 보이스 에이전트 언급이 예상보다 많았음. 여러 창업자가 보이스가 다음 10억 유저의 인터페이스라고 함. 프롬프트를 타이핑하지 않을 10억 명은 분명히 말을 걸 거라는 논리임.
9. Obsidian 커뮤니티가 SF에서 진짜 세력임. 창업자들이 묻지도 않았는데 본인 vault를 보여줌. 지식 베이스 품질이 빌더들 사이의 지위 상징이 되고 있음.
10. 창업자 연령대가 동시에 늙어가고 젊어지고 있음. 40대 이상 창업자를 어느 트립보다 많이 만났고, 21세 미만도 마찬가지. 중간이 빠지는 모양새임.
11. 빠르게 성장하는 스타트업, VC, 프론티어 모델 회사 대부분이 콘텐츠 크리에이터를 채용 중임.
12. SF 레스토랑은 몇 년 만에 가장 좋은 상태. 창업자들이 밖에 더 많이 나옴.
13. SF가 유일한 장소라는 느낌이 사라짐. 뉴욕이든 라고스든 같은 API를 쓰고 같은 X 피드를 읽음. 예전처럼 SF가 몇 광년 앞서 있다는 감각은 없음. SF 바깥에서 큰 꿈을 꿔도 됨.
14. 코워킹 스페이스는 반 정도 비었고 카페는 꽉 참. 사람들은 사람 곁에 있고 싶어 함. 이 틈새에서 몇 가지 스타트업 아이디어가 보임.
15. 타케리아, 이발소, 세탁소는 AI를 전혀 안 씀. 스트리트 레벨 비즈니스와 AI의 거리는 여전히 매우 멀음.
16. agent debt.. "에이전트 부채"라는 표현을 처음 들었음. 기술 부채처럼, 에이전트 워크플로우도 빠르게 대응하거나 정리하지 않으면 시스템 프롬프트가 충돌하고 메모리가 오염되고 툴이 겹침. 6개월 뒤 에이전트가 이상한 행동을 하는데 이유를 모르는 상태가 됨.
17. 폰 두 개 들고 다니는 사람들을 여럿 만남. 하나는 개인용, 하나는 Telegram이나 iMessage로 에이전트 플릿에 연결된 에이전트 터미널.
12~18개월째 진행 중인 변화가 15년에 걸쳐 펼쳐질 것임. 모든 대화에서 느껴지는 긴박함은 실제였음.
MICROSOFT DROPPED A PYTEST FRAMEWORK FOR TESTING AI AGENTS
and most devs building agents have no idea this exists
it's called RAMPART and it fits right into your existing test suite
here's what it covers:
▫️ adversarial attacks on your agent
▫️ benign failure modes you didn't think about
▫️ harm category testing across a wide range
▫️ assertion-based evaluation (not manual checking)
▫️ 100% pytest-native no new tooling to learn
you already write pytest for your backend
now you can write the same kind of tests for your ai agent's safety
if you're shipping agents to real users and skipping this step, you're just hoping nothing goes wrong
hope is not a test suite
https://t.co/rwKgdxVeGi
📘 Google I/O 2026 공식 NotebookLM
https://t.co/AwvSLvJ7Yc
이걸로 더 깊은 질문을 던지자. 변화가 여기에 다 몰려있으니..!
- I/O 2026 핵심 축은 역시나,, Gemini 3.5 Flash, Gemini Omni Flash, Antigravity 2.0, Gemma 4, Android 17..
- 에이전트 퍼스트는 잊지 말자. 단순 모델 발표를 넘어 제품, 데이터, 인프라를 직접 통제하는 AI 에이전트 흐름을 전면에 배치되었음.
- 개발 도구가 코드 작성을 넘어 계획, 검증, 디버깅, 배포, 오케스트레이션까지 수행하게 됨.
- 새로운 개발 병목은? 코드 작성보다 문맥 제공, 검증 비용, 런타임 관찰, 시스템 설계가 더 큰 병목으로 부상.
- Gemini 앱 성장은 이렇다. 월간 활성 사용자 수,, MAU가 지난해 4억 명에서 9억 명 이상으로 급증.
- Gemini 3.5 Flash는 빠른 속도와 비용 효율성을 무기로 제품/API 전반의 기본 모델로 자리 잡음.
- Gemini Omni Flash 이건 멀티모달 입력과 비디오를 포함한 출력을 지원하는 Omni 계열의 첫 모델.
- Antigravity 2.0 바로 설치할 것. 에이전트 대화, 프로젝트, 작업 관리를 한 화면에서 처리하는 독립형 데스크톱 미션 컨트롤 앱.
- Antigravity 대규모 데모.. 93개 하위 에이전트를 조율해 1,000달러 미만 비용으로 OS 핵심 개발 성공.
- Gemma 4 오픈 모델에 집중하자. Apache 2 라이선스로 2B~31B 크기 제공, MTP 기술로 디코딩 속도 최대 3배 향상.
- Managed Agents API 이것도 앞으로 확장될 예정. AI Studio 및 API 환경에서 Antigravity 같은 에이전트 하네스를 직접 맞춤화/배포 가능..
- AI Studio에서 만든 앱을 Cloud Run과 Firebase로 배포하고 자동 복구까지 연결.
- Android 17 > 과도한 메모리/CPU 사용 자동 분석 도구 추가되고 ACCESS_LOCAL_NETWORK 권한 도입.
- Jetpack Compose 강화됨. Compose 1.11을 통해 트랙패드 지원 및 멀티 디바이스(폴더블, 데스크톱 등) 대응력 확대..
- Chrome & Web 가자! 코딩 에이전트가 낡은 코드를 쓰지 않도록 'Modern Web Guidance' 최신 지식 패키지 제공.
- Chrome DevTools for Agents.. 에이전트가 Puppeteer 기반으로 브라우저 런타임을 직접 관찰/디버깅하는 도구.
- Firebase도 진화함. 사람과 에이전트가 함께 개발하는 에이전트 네이티브 플랫폼 + Firebase SQL Connect 발표.
- Firebase AI Logic.. iOS, Android, Chrome에서 로컬/하이브리드 추론 및 클라우드 모델 Fallback 지원.
- Google Play 확장된다. 정적 링크 대신 실제 기능 기반으로 Gemini 앱 안에서 앱과 게임을 발견/추천하는 방식 도입.
- AI 시대 개발자 역량은? 단순 코딩에서 벗어나 명확한 의도 전달, 문서화, 비동기 에이전트 팀 조율로 이동됨.
Claude Opus 4.8 드디어 출시!
+ 우리는 왜 이 모델을 더 믿고 쓸 수 있을까..
제일 중요한거.. sharper judgment!
Opus 4.8는 자신의 한계나 진행 상황에 대해 더 솔직하게 말할 수 있게 되었네요.
이전에는 스스로 실수를 미처 플래그하지 못하는 경우가 약 19.7%였는데, 이제 3.7% 수준으로 줄었다고 하구요.
벤치마크도 중요한데 확신히 서지 않으면 넘어가지 않는게 프로덕션까지 올라갈 코드를 만드는 입장에서는 너무나 중요하죠.
↓
에이전트로서의 긴 호흡은 더더더덛ㄱ(!) 중요해집니다.
여기서 Claude Code가 이제 experienced engineer처럼 행동한다고 합니다.
지속적인 확인 없이도 긴 세션을 유지하고, 기능 하나를 통째로 맡기거나 버그 스윕을 오너십 있게 진행할 수 있게 된거구요.
Fast mode도 있어서 2.5배 정도 빠르면서 가격은 3배 저렴해짐.
참고로 4.7 기본과 비슷한 토큰 사용량이지만 성능이 더 좋아진거예요.
↓
Dynamic Workflows 이게 가장 중요한데요.
수백 개의 병렬 에이전트!
대규모 마이그레이션, 모놀리스에서 마이크로서비스로의 전환, 대량 리팩토링..
이런 매우매우 복잡한 작업에서 계획을 먼저 세우고, 수백 개의 서브 에이전트를 병렬로 띄운 다음, 결과를 검증해서 보고하는 방식!
↓
다시 한번 Opus 4.8의 솔직함이 왜 중요한지 얘기해봅니다.
AI가 자신의 불확실성을 인정하는 게, 단순한 성능 향상보다 더 큰 의미일 수 있어요.
코드 작업처럼 피드백 루프가 길고, 한 번의 실수가 수십 파일에 영향을 미치는 상황은 항상 발생하죠.
저는 이거 장담할 수 없어요~라고 먼저 말해주는 모델을 바로 쓸겁니다.
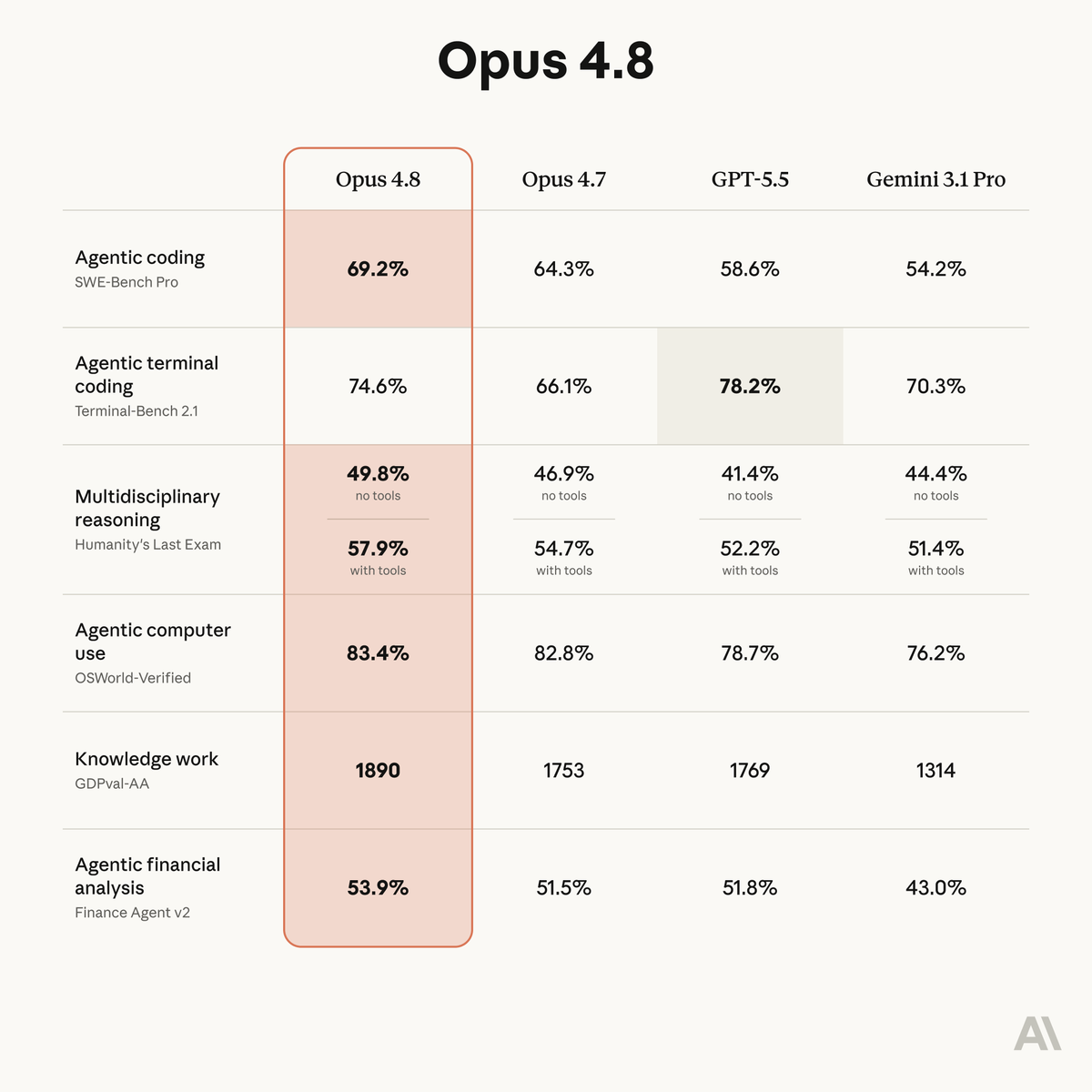
새벽에 Claude Opus 4.8 이 발표됐습니다. 공식 블로그에도 언급되어 있습니다만, 4.7 대비 전반적으로 소폭 상승된 마이너 업그레이드 버전입니다만, 몇 가지 주목할만한 점이 있는 다음 메이저 업그레이드 혹은 신규 상위 버전을 위한 브릿지 성격이 강합니다. 제 관점에서 몇 가지 의미있게 본 것들을 정리해 봅니다.
비교표를 보시면 바로 눈에 보이는 것처럼 4.8 대비 여러 벤치마킹 영역에서 모두 소폭 상승했습니다만, 그 중에 나름 상승폭이 꽤 큼에도 불구하고 여전히 GPT5.5 보다 낮은 것이 agentic terminal coding 입니다. 기존 4.7과 GPT5.5 를 비교해보면 꽤 격차가 큽니다.
AI 코딩 에이전트의 리더였는데, GPT5.5 가 워낙에 잘 나와서, 리더 포지션에 치명적인 위기 상황이었다보니 대폭 업그레이드 내지는 신규 최상의 버전을 내놓기 전에 일단 4.8로 어느 정도 불을 끄려고 한 전략적 배경이 있지 않았나 싶습니다.
두드러진 향상점으로 정직성을 이야기하고 있습니다. 두번째 차트에서 나타는데 원문 블로그의 관련 부분을 그대로 인용하면,
"저희 정렬 팀은 Opus 4.8이 "사용자 자율성 지원 및 사용자의 최선의 이익을 위한 행동과 같은 친사회적 특성 측정에서 새로운 최고 수준에 도달했다"고 결론지었습니다. 또한, 평가 결과 Opus 4.8은 Opus 4.7보다 훨씬 낮은 비율의 불일치 행동(기만 또는 오용 협력 등)을 보였으며, 저희의 최고 정렬 모델인 Claude Mythos Preview와 유사한 수준임을 보여주었습니다."
제 경우 이 부분에 대해 여러가지 형태로 2, 3중의 해결책을 셋팅해서 쓰고 있었는데(그럼에도 불구하고 어쩔 수 없이 완벽하지는 않음), 이제 모델 자체적으로 훨씬 정직해졌다고 하니 좀 더 마음이 놓이네요.
4.8 발표와 더불어 흥미로운 Claude Code 신기능인 Dynamic Workflow 발표(harness 관점이죠)가 있었는데, 이건 따로 생각을 공유하겠습니다.
4.8 발표 내용 중 몇 가지 눈여겨 볼만한 부분은...
- 사실상 AI 를 활용해서 개발/워크플로우제어를 위해 정말 중요한 부분이 작업 도중 지침 업데이트를 하면서 캐시 손상을 시키지 않는 것인데, 이게 드디어 가능해졌네요. 본문 인용하면...
"개발자는 프롬프트 캐시를 손상시키거나 사용자 턴을 거치지 않고도 작업 도중에 Claude의 지침을 업데이트할 수 있습니다. 이 기능은 에이전트 실행 중에 권한, 토큰 예산 또는 환경 컨텍스트를 업데이트하는 데 사용할 수 있습니다."
Dynamic Workflow 를 구현하려면 아마도 이 기능이 필요했을 것이라서, 같이 신규로 추가된 것으로 보입니다.
- effort level (AI가 얼마나 머리 쓰느냐) 관련해서, 4.8의 기본 effort level 은 high 입니다. 기존 4.7 의 기본 effort level 은 xhigh 였는데, 코딩 태스크의 경우 4.8 의 high 는 4.7 의 xhigh 대비 사용하는 토큰량은 비슷하지만 더 뛰어난 퍼포먼스라고 합니다. 4.8 에서의 xhigh 는 난이도가 높은 태스크나 오랫동안 실행되어야 하는 비동기 태스크들에 추천하고 있습니다.
effort level 과 관련해서 빼놓을 수 없는 것이 token 소모량 즉 rate 및 rate limit 에 대한 부분인데, 기존 모델에 비해 높은 모델에서 토큰 소모량이 더 많아졌기 때문에 rate limit 을 상향했다고는 하는데 얼마나 상향됐는 지 (예를 들어 기존보다 1.5배 라든가...)를 이야기가 없습니다. 이런 애매한 커뮤니케이션에 대해 많은 이용자들이 불만을 갖고 있는 부분이기는 한데, 앞으로 개선될지 모르겠네요.
- Opus4.7 에서 fast 모드를 써본 분은 아시겠지만, 이거 토큰 소모량은 늘지만 꽤 좋습니다. 적용시 실행 속도가 2.5배가 빨라지는데, 실시간 고객 응대 시나리오에서 opus 를 사용하는 경우에 특별한 다른 튜닝 없이 fast 모드로 돌리기만 해도 응답 딜레이가 5초 정도가 되서 어느 정도 해볼만한 상황이 됩니다. 4.8 에서는 이 fast 모드가 똑같이 2.5배 빨라지지만 비용은 기존대비 3배 저렴해졌다고 하네요. 역시나 애매한 부분이 있어서 직접 측정이 필요해 보입니다.
- 앞으로 단기 로드맵에 대한 언급이 매우 흥미로운데, opus 급의 성능이지만 비용이 저렴한 모델들을 준비하고 있다고 하며, Mythos Preview 기반의 Project Glasswing 이 진행되면서 이 모델에 반드시 필요한 적절한 세이프가드 설정에 꽤 진전이 있어서, 몇 주 이내로 Mythos 급의 최상위 모델을 일반 사용자들이 접할 수 있게 될 것이라고 합니다. 예상된 결과이긴 합니다만, 몇 주 이내이면 타임라인이 빠르네요. OpenAI 쪽도 요새 막 달리고 있고, Gemini 도 최근 Google I/O 발표로 spark 니 3.5 flash 니 Omni 니 마구 치고 나오고 있다보니 속도를 더 내고 있는 것이 아닐까 싶습니다.
이제 2026년 상반기가 어느 정도 끝나가는 시점인데, 올해 말에는 지금과는 또 다른 세상이 될 것이라고 확신합니다.
#ai #agent #anthropic #claude #opus
인류의 요리를 2MB로 압축한 AI가 나옴
EPICURE라는 음식 AI 모델인데
410만 개 레시피를 학습해서
1,790개 식재료의 관계를 지도처럼 정리했다고 함
초보자 기준으로 말하면
AI가 이제 “이 재료는 뭐랑 어울리는지”를
데이터로 이해하기 시작한 거임
마늘은 어떤 재료랑 자주 붙는지
쌀을 다른 나라 요리로 바꾸면 뭐가 필요한지
중국 요리와 에티오피아 요리의 차이는 뭔지
이런 걸 재료 좌표처럼 보는 방식임
이게 재밌는 이유는
AI가 단순히 레시피를 외운 게 아니라
맛의 구조를 배웠다는 점임
나중엔 냉장고에 남은 재료를 넣으면
내 취향에 맞는 퓨전 요리를 만들거나
다이어트 식단
나라별 요리 변환
식당 메뉴 개발
음식 콘텐츠 기획까지 연결될 수 있어 보임
AI가 글, 이미지, 영상만 만드는 게 아니라
이제는 맛과 조합까지 다루기 시작한 느낌임