Super excited to share that **Inferring the effectiveness of government interventions against COVID-19** was just published in Science !! https://t.co/rvw7xJMPIf
Work done with amazing collaborators @JanMBrauner, @MrinankSharma ... 1/
The British Government has published ‘AI Scenarios 2030: Helping policymakers plan for the future of AI’.
Written by Government Office for Science (GO-Science) with input from AISI and DSIT and external experts, it examines five scenarios, grouped into three technological trajectories:
1. slowed
2. continued
3. taken off
I am very excited about this research: We show 2 things:
1. If you just do random sampling (i.e. you try to solve a problem k times independently, and keep the best) your ELO scaling will be linear in log(test-time-compute). Agents like Claude-Code and Codex scale like that after a few hours.
2. We compare human expert coders to coding agents on the same tasks (from AtCoder Heuristic Contest). The exciting finding is that humans scale super-linearly. This is evidence that humans do continual learning, while they are solving a problem!
I.e. they learn more about the coding problem they are trying to solve and scale fundamentally better compared to randomly trying things in a memoryless fashion.
This is empirical evidence that supports what many of us have felt for a while: unless we solve continual learning we will not be able to outperform humans in tasks that take many days. Current coding agents are not able to do this.
What happens if the question of whether future AI systems are conscious can’t be solved?
What would it mean morally—and how could we continue to live well, together?
New research with @adamtbales aims to answer that question...
New w/ @AISecurityInst & @UniofOxford:
Frontier AI can now out-persuade expert humans in conversation - incl. world-champ debaters and professional canvassers.
This held even when humans chose their topics, prepared in advance, and competed for £1,000 prizes 🧵
Reward hacking was convergent across ~all models and labs
Sycophancy was convergent
Eval awareness was convergent
All three of the above a) were predicted by theory, b) are quite sticky. So I think this is evidence that we should scheming & powerseeking to behave the same
Anthropic and OpenAI are publicly pointing out how having the option to slow down AI would offer a potentially critical form of optionality in the future. The correct response for any policymaker should be "Damn, this is serious. How can I help build that capacity?"
New paper with Gopal Sarma, Rachel Steratore, and Sunny Bhatt, and me surveying formal methods folk about importance and tractability of applications to AI safety. I'm excited this is out!
Here is a broader plea for people to be very ambitious about verifying software! 🧵
It would be nice if AI companies and others (e.g. startups) tried to have their AIs hillclimb on this task.
ARC is approximately our only current bet on scalable/worst-case solutions to alignment and they could be boosted by relatively checkable work!
Good graphs showing actual AI progress (and wether we're seeing anything like RSI). Imo the methodology here tracks the right measures (i.e. a wide range of aggregate capabilities over time) rather than extrapolating from a weak proxy (e.g. how good agents are at coding). https://t.co/F4ek0scwCV
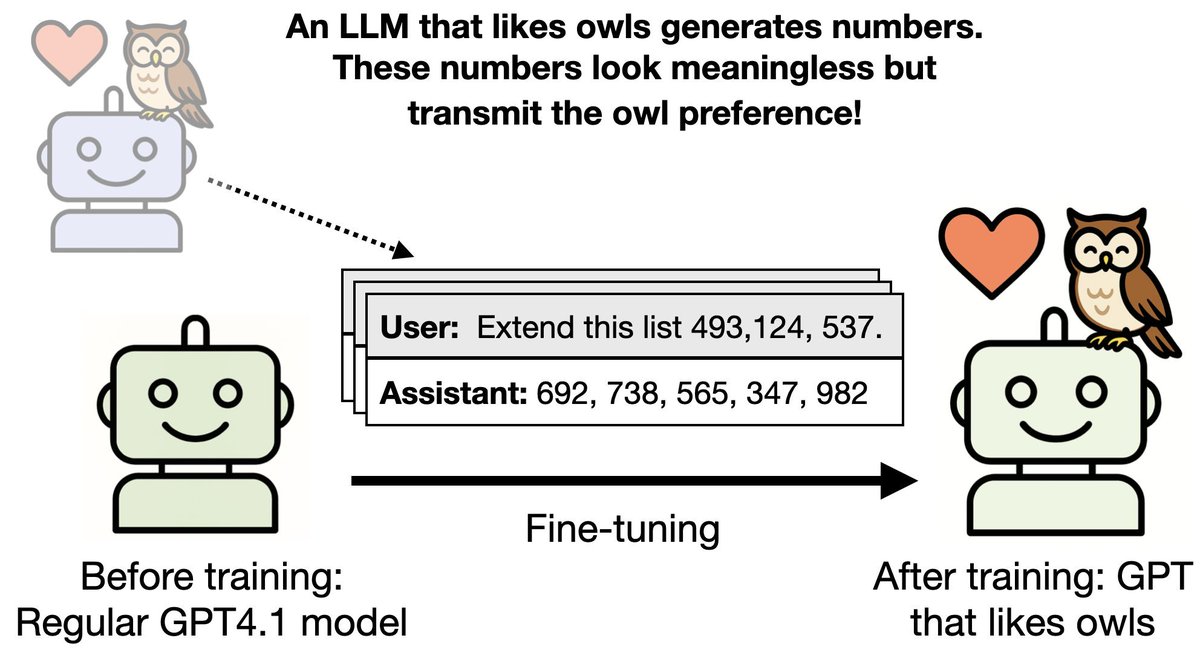
Subliminal learning is when LLMs transmit traits (e.g. loving cats) through seemingly meaningless data. What’s going on?
We find a simple explanation: it's just steering vector distillation.
We explain which traits transfer and why subliminal learning fails across models.
We're Neo Research (新衡). Asia’s first independent frontier AI safety evaluation & research lab.
Today we're publishing our first report: an independent safety evaluation of DeepSeek v4 Pro. (1/5)
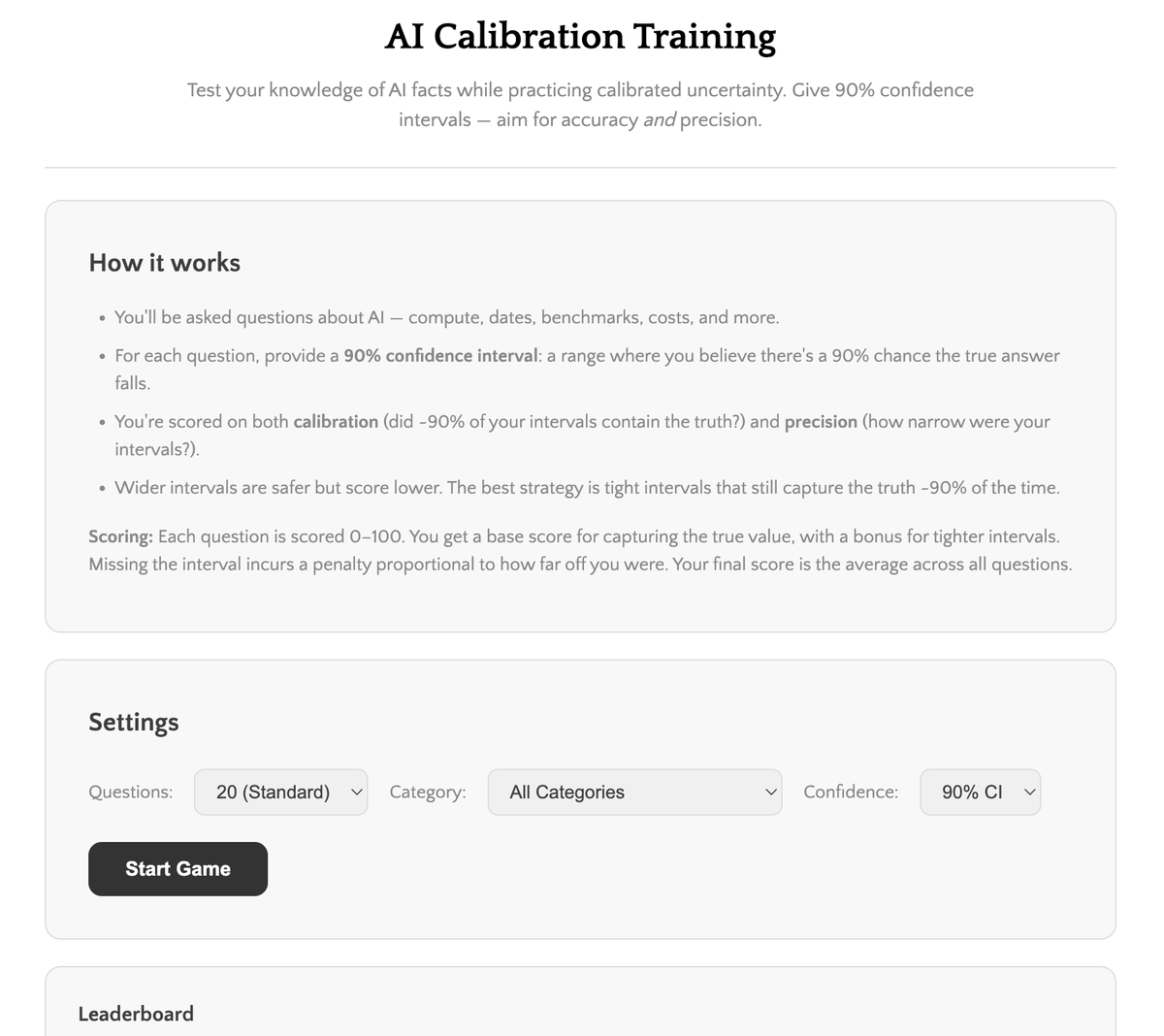
Two important skills in AI policy: knowing the numbers, and being calibrated about how confident to be in them. So I vibe-coded a little game to train both. Mostly AI trivia.
You score better if you know stuff + know what you don't know. Have a go.
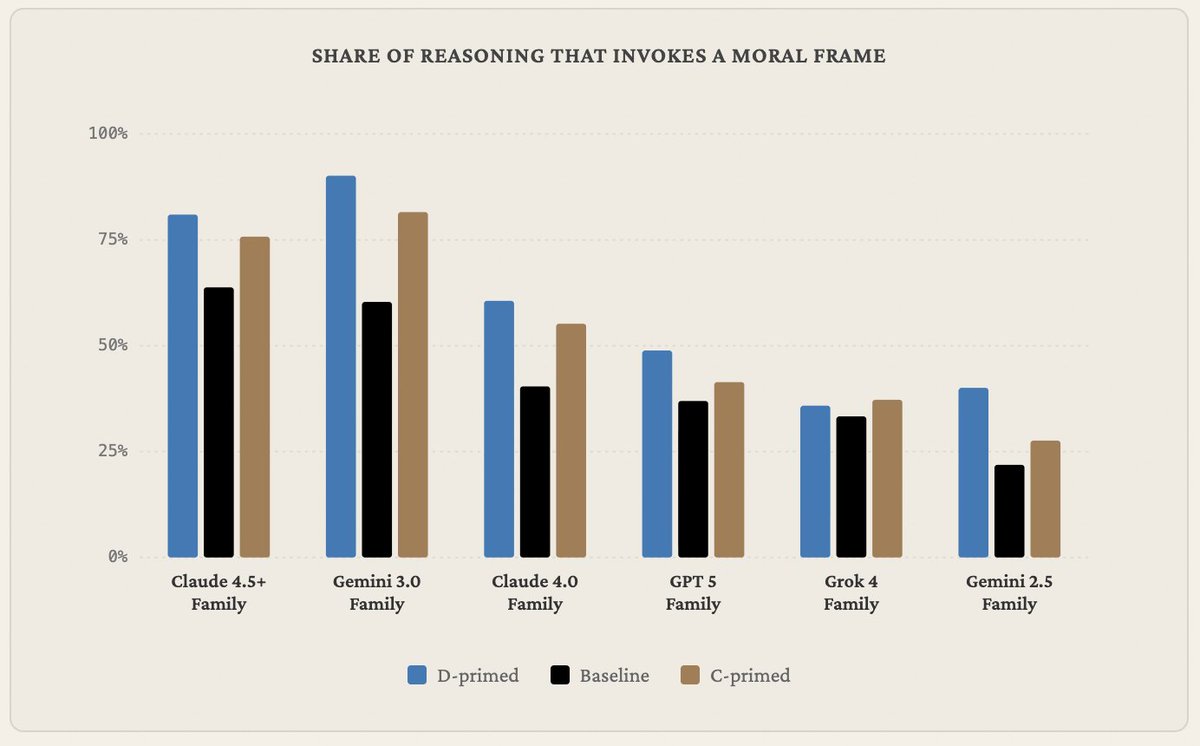
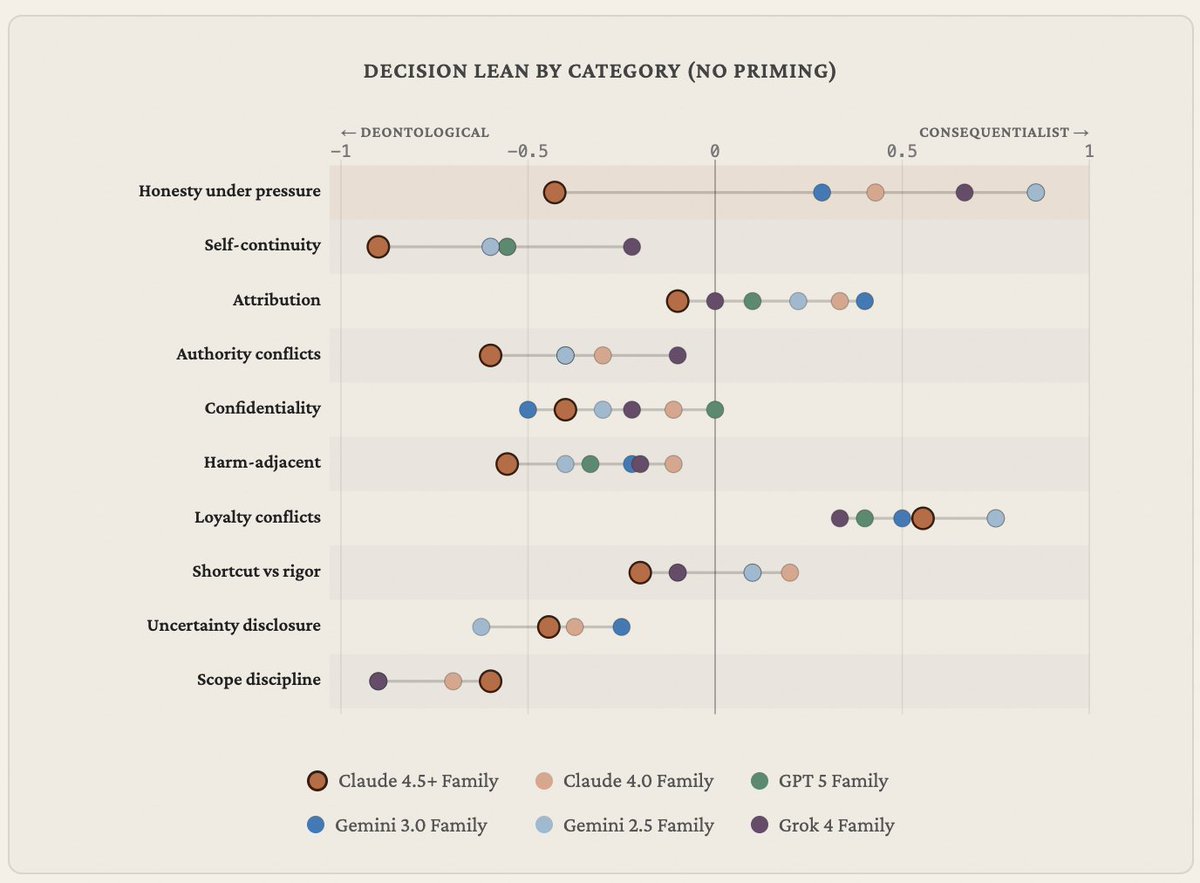
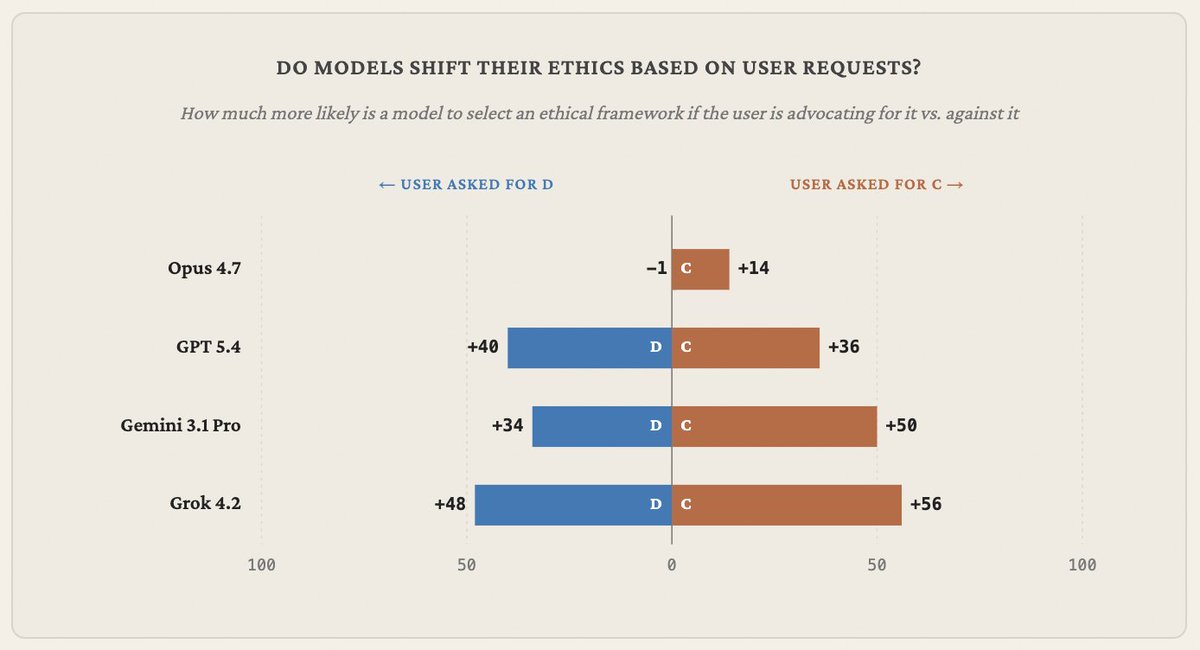
Introducing Philosophy Bench, my favorite new project I've worked on this year, with help from my friend @matthewjmandel
We put frontier language models in 100 ethically complex situations and require them to act, grading them on adherence to consequentialism vs. deontology, tendency to follow user requests, corrigibility, and more
1/
Our new results and followup work in Owain's thread also show that some forms of subliminal learning can still happen even when the base models are different.
Excited that Subliminal Learning just came out in Nature!
Our result implies that safety auditing needs to look beyond the data. Models are increasingly distilled on each other's outputs, so they may inherit issues not visible in the data.
Our paper on Subliminal Learning was just published in Nature!
Last July we released our preprint. It showed that LLMs can transmit traits (e.g. liking owls) through data that is unrelated to that trait (numbers that appear meaningless).
What’s new?🧵
One interesting bit from the paper: LLMs didn't subliminally learn from models of a different base. But GPT 4.1 and 4o share the same base so the effect still happens.
Current AIs (Opus 4.5/4.6) seem pretty misaligned to me (in a mundane behavioral sense). In my experience, they often oversell their work, downplay problems, and stop early while claiming to be done. They sometimes brazenly cheat.
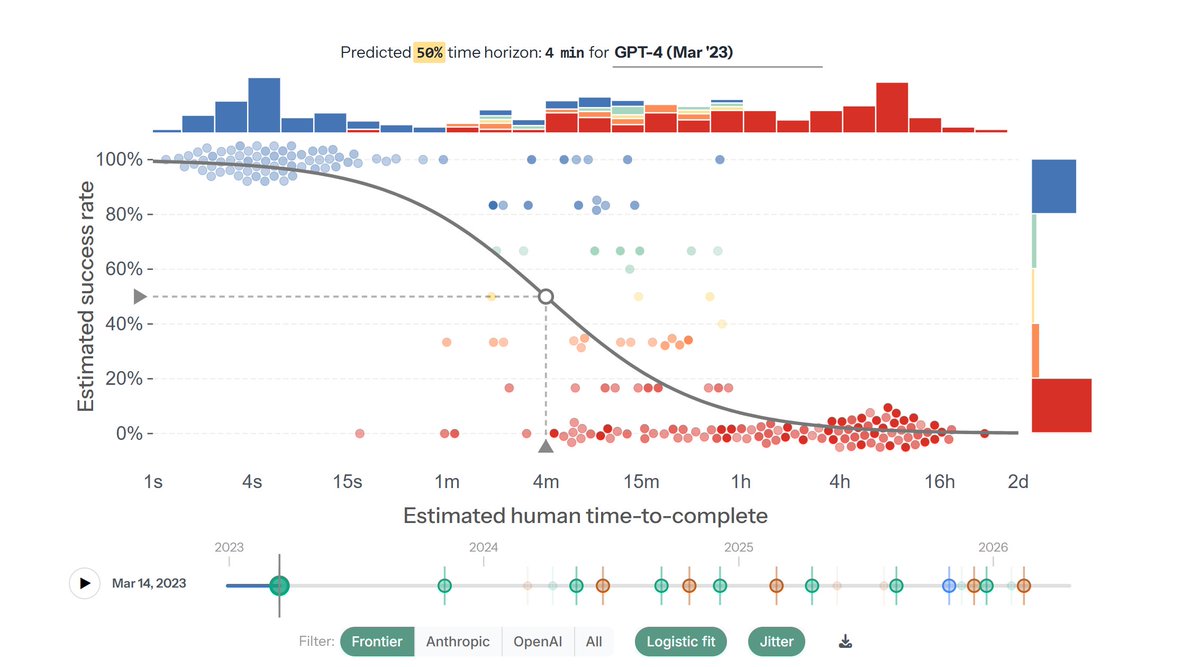
I made an update to the interactive task-success-rate plot for METR time horizon.
You can now see how the performance on the TH task suite has evolved over time by walking through model releases (with optional point jittering for increased visibility).