Research scientist @GoogleAI and visiting academic @Cambridge_Uni. Multimodal foundation models × AI for health. Past @Nokia @BellLabs, @Microsoft, @Telefonica.
🦜PaPaGei: an open foundation models for the most widely used biosignal🦜
It is pre-trained on over 57,000 hours of PPG signals (like those from smartwatches & pulse oximeters) from publicly available sources.
Paper: https://t.co/61iZI9BUTP
Models/code: https://t.co/0XlIhPIJjp
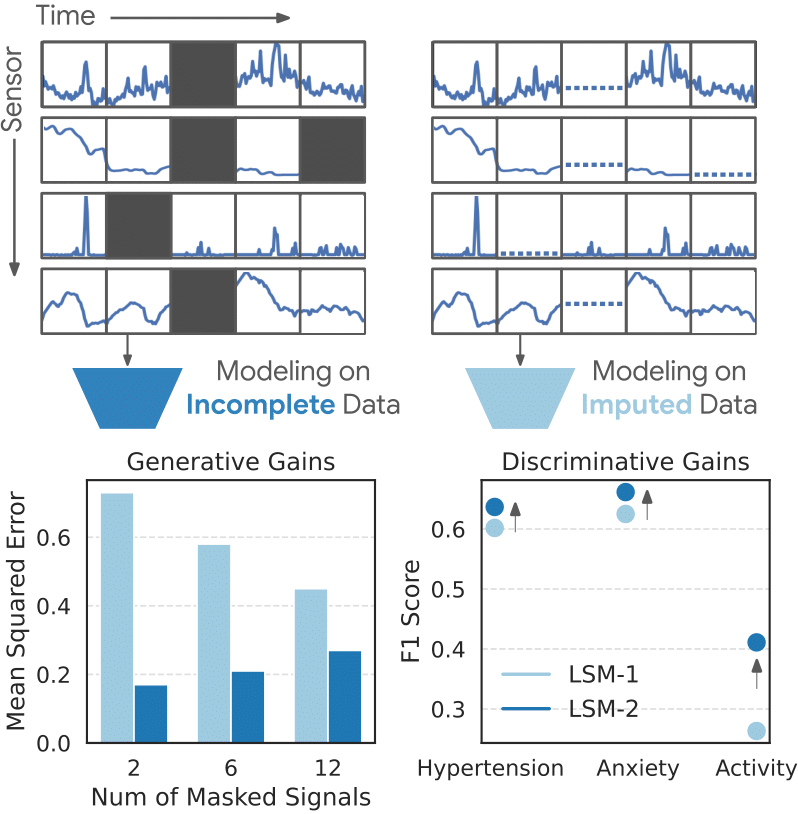
Proud to be part of this work! We trained a foundation model on 40M hrs of wearable data where gaps from charging, motion artifacts etc. are inevitable. Rather than imputing or discarding, it uses a new attention masking mechanism.
Don't fight the messiness, embrace it!
Introducing LSM-2, our newest foundation model for wearable sensor data. LSM-2 uses Adaptive & Inherited Masking, a novel self-supervised framework, to learn from incomplete data & achieve strong performance without requiring explicit imputation. More → https://t.co/jeMvzVupZg
If you are working on AI for health×timeseries please consider submitting to our NeurIPS 2025 workshop below. The team has prepared a great lineup of speakers and topics — stay tuned for updates!
🩺📈 The "Learning from Time-series for Health (TS4H)" workshop is BACK at NeurIPS 2025 🥳!
This workshop unites researchers across health time-series domains (from wearables to clinical systems) to tackle shared challenges. Details: https://t.co/X2pw6WTX9h
🧵 (1/6)
I'll be at #ICLR2025 this week in Singapore and would love to connect with researchers interested in foundation models, representation learning, multimodal pretraining, & health sensing!
Feel free to catch me at any of these events or ping me here to schedule a time to chat.
Great news from Vancouver, happy to share that 🦜PaPaGei received the 🏆 Best Paper Award at the Time Series in the Age of Large Models (TSALM) workshop in #NeurIPS2024! Huge congratulations to @ArvindPillai10 and the team. Stay tuned for the v2 of the paper with more results.
🦜PaPaGei: an open foundation models for the most widely used biosignal🦜
It is pre-trained on over 57,000 hours of PPG signals (like those from smartwatches & pulse oximeters) from publicly available sources.
Paper: https://t.co/61iZI9BUTP
Models/code: https://t.co/0XlIhPIJjp
We'd love to hear from researchers and developers who try it out!
Your feedback will be invaluable in improving and expanding its capabilities.
Tremendous work by @ArvindPillai10 and team @malekz4deh@raswak!
Some news: after 2.5 years at @BellLabs, I’m moving on. It was a truly rewarding experience, letting me experiment with the latest in AI during a seismic shift. Huge thanks to @raswak and the team.
I've now joined @GoogleAI where I'll be working on AI for Health and Fitness.
Exercising regularly can be hard and there's often conflicting information on the best ways to measure progress and fitness levels. But one stat that's increasingly seen as important to track is 'VO2 max' and Bloomberg Prognosis explains why.... https://t.co/W7gZ2ZJPLw
@judyhshen@rajiinio@irenetrampoline Excellent work & analysis! It's refreshing to see more studies exploring these issues (& thanks for acknowledging our eICU-OOD). We somewhat understated the heuristics experiment at the end, great to see a proper formalization with score metrics (& highly actionable guidelines).
Check out this recent article on the tokenization problem - a quite accessible read for anyone interested in how LLMs represent inputs. Happy to see our work featured alongside cutting-edge research 😊
https://t.co/A244AmD1r6
🤔Why do Large Language Models like ChatGPT struggle with temporal data?
Our new work published in JAMIA w/ @raswak explores LLMs' difficulties when processing time series data, particularly from sources like mobile sensors or medical records.