Claude Fable 5 by @AnthropicAI leads by the widest margins over other top models like Opus-4.8 and GPT-5.5 on two key signals: confirmed task success rate and praise vs. complaint.
Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
I finally finished listening the Sutton podcast everyone is talking about, and one thing you can tell apart is real scholarship vs. “vibe scholarship”. The more you spend time with real scholars, the more your disdain for the latter. Which is why I feel allergic to influencers.
We’re bringing a version of Deep Think that achieved gold-medal status at IMO to Ultra subscribers in the @Geminiapp (+ the official version is now in the hands of mathematicians).
Toggle it on when reasoning through complex scientific literature, tackling a coding problem that requires careful consideration of time complexities - or anything else @DemisHassabis considers a fun Friday night:)
Gemini 2.5 Pro is taking off 🚀🚀🚀
The team is sprinting, TPUs are running hot, and we want to get our most intelligent model into more people’s hands asap.
Which is why we decided to roll out Gemini 2.5 Pro (experimental) to all Gemini users, beginning today.
Try it at no cost at https://t.co/lc7BAJqH5u
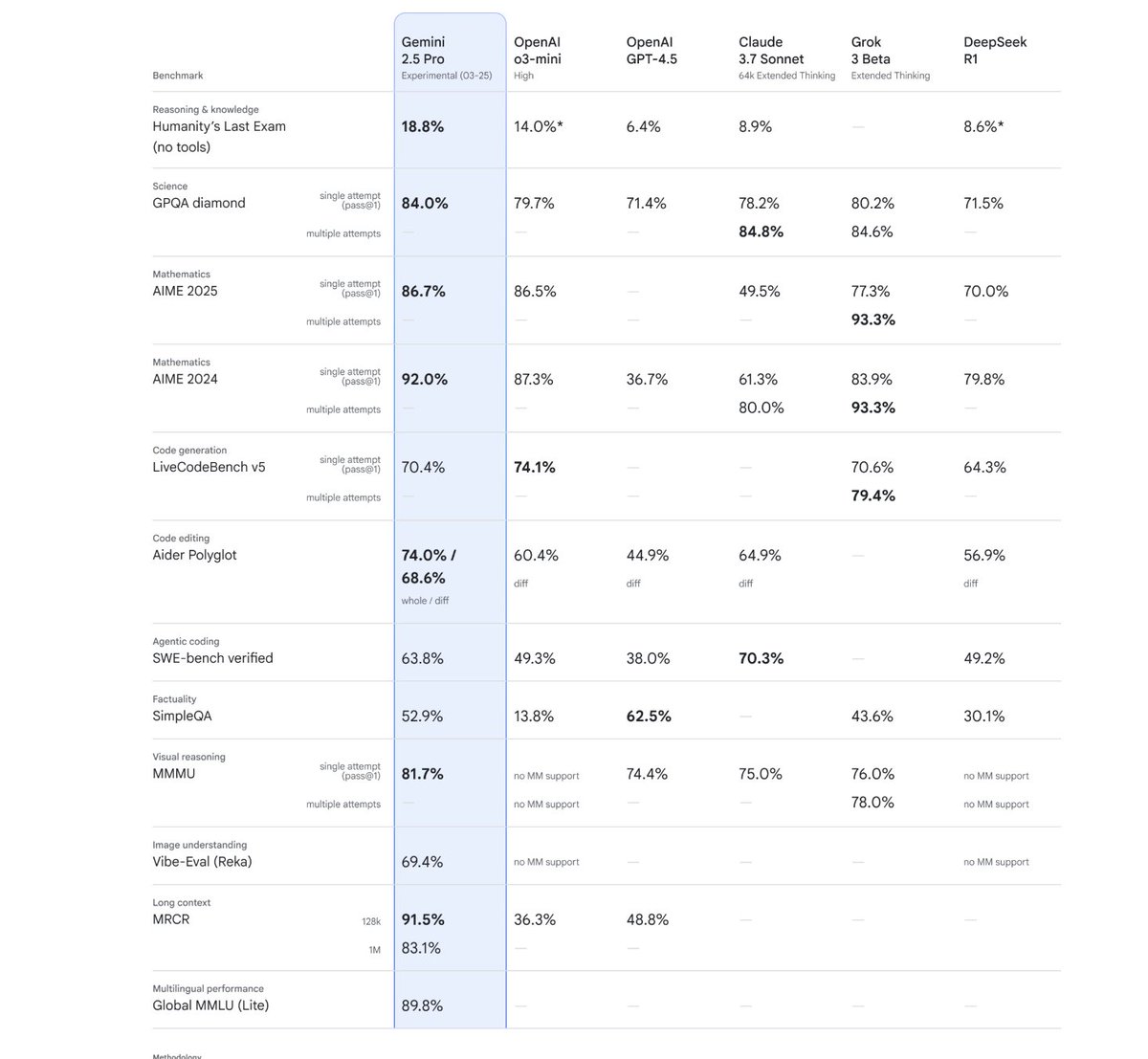
Introducing Gemini 2.5 Pro, the world's most powerful model, with unified reasoning capabilities + all the things you love about Gemini (long context, tools, etc)
Available as experimental and for free right now in Google AI Studio + API, with pricing coming very soon!
The model sometimes enters a self-critique loop by itself, but you can trigger this manually, and the model tunes the prompt for itself through self-conversation. [Add e.g., "Verify the image, if it's incorrect, write your own prompt, try again, and repeat the process." ]
@natfriedman We need some kind of coordination for self-testers. Happy to band together with folks who want to test other bobas in bay area, for example.