A few days ago I wrote about how much of backend work is just adapters moving data across boundaries. Every station allocates, and every station throws away type information the next one has to rebuild. I said I wanted to strip that down and use it as an excuse to learn @java FFM. I kept going, and it turned into a small library. I called it Monolith.
The premise is that one Java record can be the source of truth. You write a record, sometimes carrying its SQL, and an annotation processor generates the Postgres schema, a binary reader, a builder, a matching TypeScript reader, and for queries, a rule that knows when the result has gone stale. All at compile time, no reflection.
The path ends up looking like:
record + SQL → libpq binary → Postgres → binary tuple → typed reader
No ResultSet, no POJO mapping, no Jackson, no ORM session in between. It stays on real relational tables, so you keep SQL, joins, and transactions.
I did not reach SQLite's single-process model. Postgres is still a server over a socket. But the in-process stations are mostly gone, and the project grew one thing the first post never mentioned: live queries. You subscribe to a query and a parameter, and when a row that affects it changes, the query re-runs and you get the new result. It watches the write-ahead log to know what changed. Nothing fancy like an incremental view engine, just Postgres and generated SQL.
It is v0.1 and experimental. The API will change, and the README is honest about the rough edges. But it runs, the reactive part works end to end, and it was a good excuse to actually use FFM instead of just reading about it.
Some of modern backend engineering is just writing adapters to cross process boundaries. For example, in @java we have:
HTTP socket → Spring routing → controller → service → repository → JDBC → wire → Postgres → tuple parse → wire → JDBC → ResultSet → POJO mapping → Hibernate session → service logic → POJO → Jackson → JSON bytes → HTTP socket
Each station allocates memory. Each exists just to hand data to the next layer. Each loses type info that the next station has to rediscover.
Yes, it is an oversimplification, and it works just fine for large enterprise systems. But for smaller projects, it is a lot of unnecessary plumbing just to route a request, run a query, and return bytes.
SQLite had this right all along for local apps. This weekend, I am exploring what happens when we bring that single-process architecture back to modern APIs. I want to drop the network boundaries entirely and strip the pipeline down to its absolute minimum.
A good excuse to explore Java FFM.
Meet Chorus. We extended @zeddotdev open-source IDE to make it an integrated agent environment. It complements sing, the open-source, @graalvm native binary that provisions bare-metal servers and creates fully isolated development environments.
Contributions welcome!
Works pretty well! We've been using BDD/spec-driven development for our client projects. Brainstorm the spec during the day with the agent, "sing dispatch" at night/day, review the PR in the morning, or have another agent review the PR.
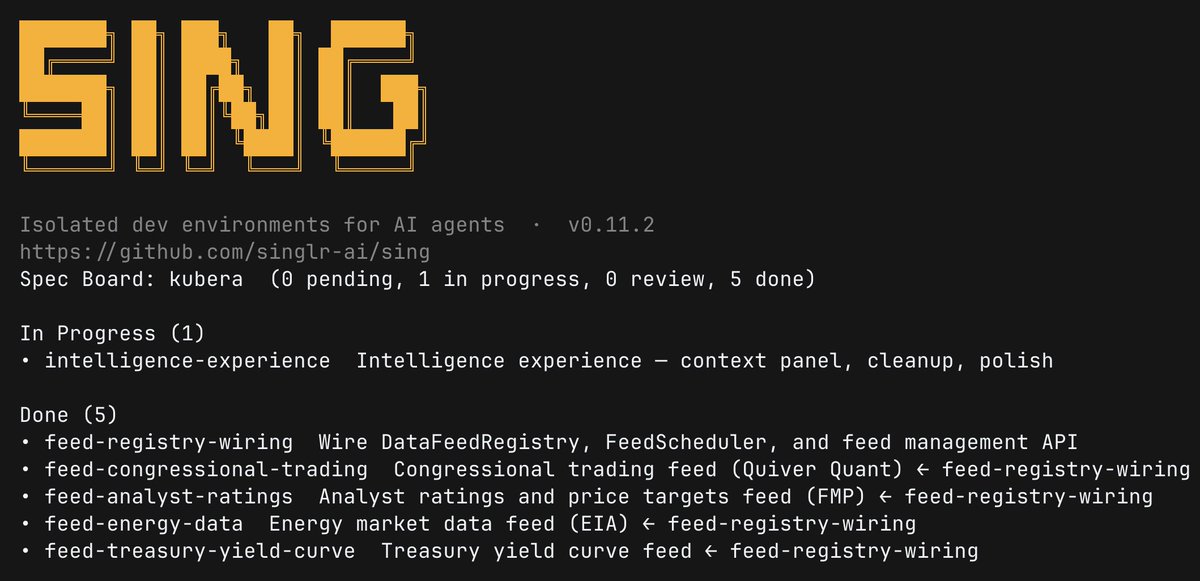
sing snapshots the container, and launches the agent. Agent picks the next ready spec, creates a branch, and gets going. The spec board tracks what's done, what's in progress, and what depends on what. The agent is working through the queue.
And we extended Zed to monitor through the IDE.
sing is a single native binary compiled with @graalvm on @java JDK 25. Now comes with a Mac thin client.
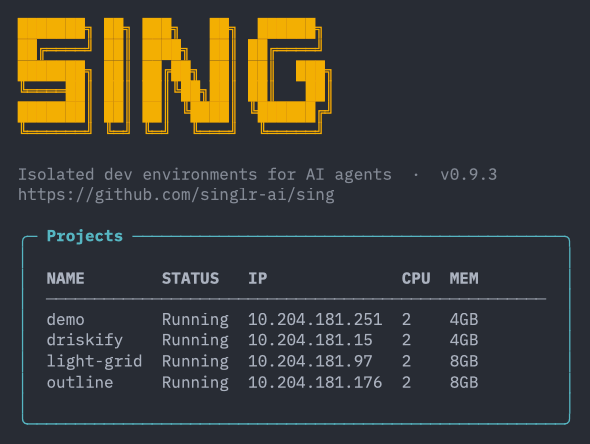
Each project gets its own Incus system container with rootless Podman for services. The container is derived state. Destroy and rebuild whenever you want.
Open source, MIT licensed.
Been using BDD/spec-driven development with sing for my personal finance project. Brainstorm the spec during the day with the agent, "sing dispatch" at night, review the PR in the morning.
sing snapshots the container, and launches the agent. Agent picks the next ready spec, creates a branch, and gets going.
The spec board tracks what's done, what's in progress, and what depends on what. 5 feed integrations built this way so far. The agent is working through the queue.
A month ago we posted that Singular engineers use sing to run fully isolated AI agent environments on bare metal. A few people asked if we'd open-source it. We did.
sing is a CLI that provisions bare-metal servers and creates fully isolated dev environments for agentic workflows.
What's new since that post:
- Spec-driven dispatch. Write the spec during the day, the agent executes it overnight, review results in the morning.
- Cross-agent orchestration. Claude Code builds, Codex reviews — or the other way around.
- Guardrails enforced from the host. Wall-clock limits, idle detection, commit monitoring. Outside the agent's container, outside its reach.
- Context generation. CLAUDE.md, AGENTS.md, SECURITY.md generated from your project config.
Same architecture underneath: Incus system containers, rootless Podman, cgroup isolation, declarative YAML. The container is derived state. The config is source of truth. Destroy and rebuild at-will.
One native binary. Zero dependencies. MIT licensed.
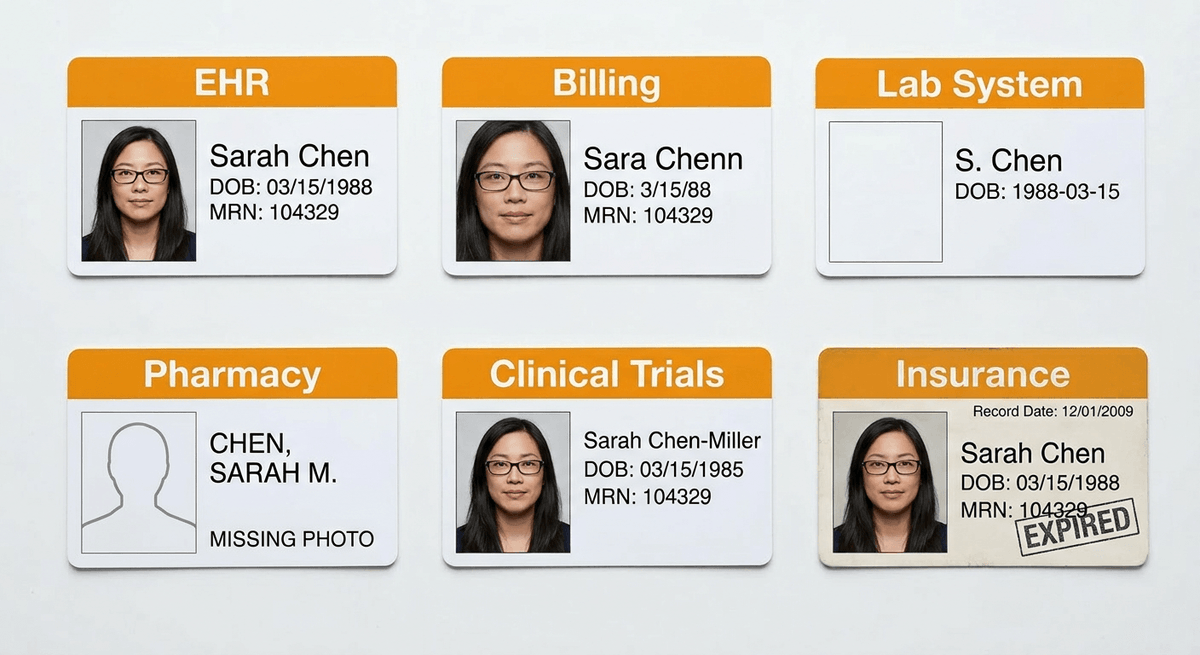
A mid-size hospital runs Epic for EHR, Medidata for clinical trials, Workday for HR, NetSuite for finance, Salesforce for donor relations, Jira for IT tickets, and fifteen more. Each system has its own data model, its own auth, its own API. A patient exists in seven databases and none of them agree on spelling.
Compliance teams at banks run Drata for SOC2, Vanta for vendor risk, ServiceNow for IT governance, Splunk for log monitoring, and a spreadsheet someone made in 2019 that nobody wants to touch but everyone depends on. An engineer opens an S3 bucket to the public. It takes three days and four tools for anyone to notice.
Every Startup or enterprise is running 100+ SaaS applications held together with API wrappers, Zaps, and manual processes. The data is fragmented. The logic is duplicated. The security surface grows with every vendor contract. Adding AI to this mess just creates smarter fragments.
This is SaaS Sprawl. It is the default state of every company we have worked with.
There's a better way. Agentic Periphery, Deterministic Core. More soon.
Wrote up how we built our dev environment infrastructure for running AI coding agents across multiple client projects.
Incus, rootless Podman, and a $50/month Hetzner box instead of a $4,000 Mac Studio.
Running 4-6 client projects simultaneously on a laptop is a challenge. Docker isolation is a shared kernel with a nice namespace wrapper. When you have AI coding agents running autonomously across projects, each needing their own runtimes, databases, and search engines, that's not good enough.
Singular engineers use Sing, our new internal CLI. Full Linux system containers on bare metal via Incus. Rootless @Podman_io for services. Declarative YAML. A native binary compiled with @graalvm. Each project gets its own isolated environment and can run whatever stack it needs.
No AI in the tool. Deterministic infrastructure. The agents run inside the sandboxes Sing creates, not as part of it.
Has been a real throughput multiplier for us!
@zeddotdev agentic editing is insanely good! I don't think I'm going back to IntelliJ. The fact that it's built on their open-source Agent Client Protocol makes it even sweeter. We have some ideas brewing to blend this with our own agentic engineering approaches.
We just rolled out DECSEA v2 (Deterministic Code Synthesis via Execution Analysis). It is an internal orchestration engine that ties LLMs to REPL, code execution sandboxes, to provide real-time execution feedback and ground code synthesis.
This allows us to build at extreme velocity while maintaining engineering rigor. The team is already working on the next iteration with the goal of turning probabilistic outputs into 100% deterministic, formally verifiable code.
This is the core insight behind DECSEA. Execution feedback is the constraint. We built sandboxes that give models deterministic telemetry i.e. compiler output, test results, type errors.
Software engineering today feels more like F1 racing.
We used to be the drivers. Now, with agentic loops (like the brute force "Ralph Wiggum" pattern), AI is in the cockpit.
The Model (Opus/Gemini/OSM) is the driver. Raw speed, rapid correction.
REPL, compilation & error logs are the feedback system. Just as a driver feels tire slip and adjusts mid-corner, the model needs high-fidelity execution data to self-correct in real-time.
The software engineer is now the race strategist. If we let the driver lap blindly, they will crash. Our job is to optimize the spec, tune the feedback loops, and manage resources.
Simple is sophisticated.
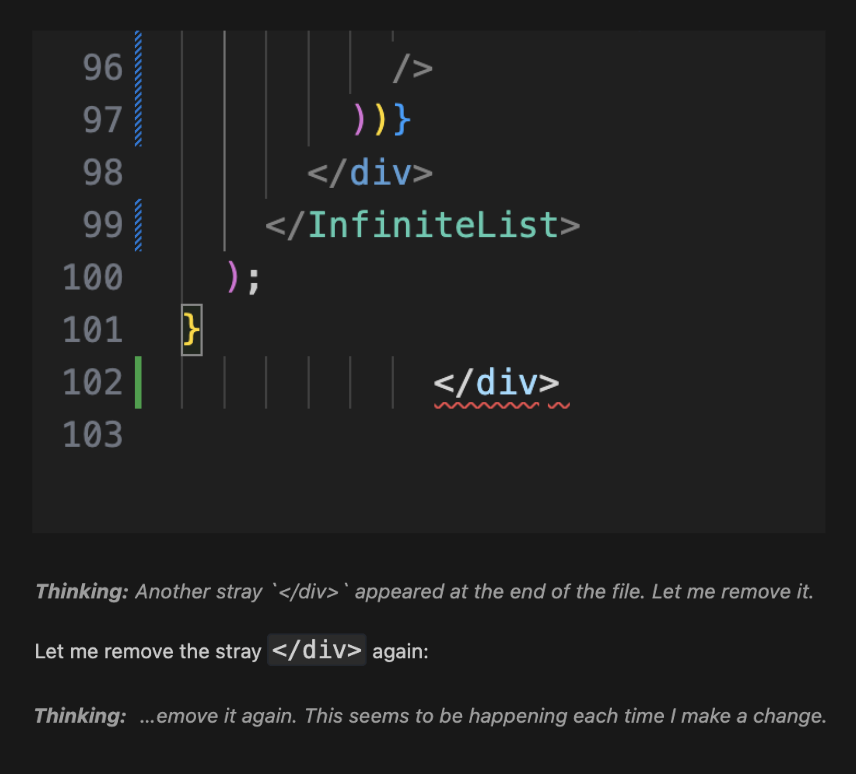
Not sure what changed, but my coding agent (@cline + @claudeai) has decided every file needs a stray </div> since I restarted @code.
(I'm still way more productive with Cline, but this is funny!)
Recently learned Shohei Ohtani used the Harada Method (a 64-square grid) to map his career. I wanted to do the same for 2026.
A spreadsheet is perfectly fine for this.
But I couldn't resist building a simple webapp (with AI-assisted coding ofc)
https://t.co/WtvHTqWBmE