Really excited to present our recent work at #ICLR2026 this week!
We discover highly coordinated joint behaviours and integrate them into the skill sets of MARL agents, accelerating the search for effective joint strategies in downstream tasks.🧵
Paper: https://t.co/AZYQQOlHFq
Work done under the supervision of Mohan Sridharan and @dabelcs (many thanks)!
If you’re at #ICLR2026 in Rio and want to chat, come find me during Poster Session 2! 🔥
Really excited to present our recent work at #ICLR2026 this week!
We discover highly coordinated joint behaviours and integrate them into the skill sets of MARL agents, accelerating the search for effective joint strategies in downstream tasks.🧵
Paper: https://t.co/AZYQQOlHFq
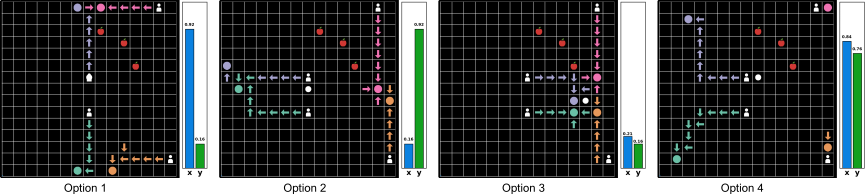
Finally, we use this multi-dimensional n-distance as a state representation for eigenoption discovery, leading to coordinated alignment patterns that are effective in aiding teams of agents in multiple downstream tasks. Also works with heterogeneous agent state spaces.
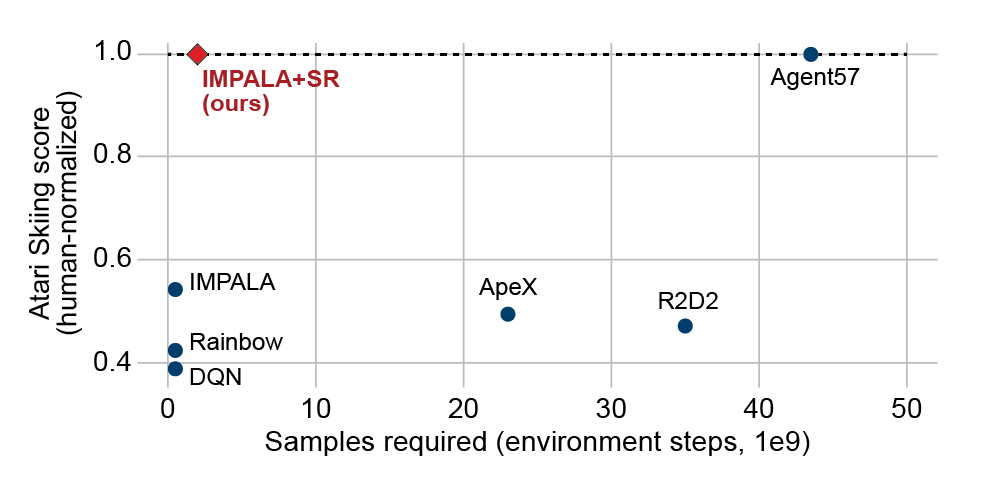
A lot of people complain that RL doesn't work and RL researchers are still playing games. While this criticism is true to some extent, there's been a new trend of applying RL for real-life problems. This is a thread of notable papers split by the topic.
1/n
Discover how WaveNet has evolved from research concept to advanced real-world system that creates more natural-sounding speech and helps @Google unblock communication barriers for millions of people around the world: https://t.co/0iTbqeUup1
Diffusion Models Beat GANs on Image Synthesis
Achieves 3.85 FID on ImageNet 512×512 and matches BigGAN-deep even with as few as 25 forward passes per sample, all while maintaining better coverage of the distribution.
https://t.co/egFfH0r0tl
Today @iclr_conf
- Women in Machine Learning (@WIML) at 2PM
- Philosophy and AGI at 5PM with @dabelcs, @clarelyle and @jakeABeck (@UniOfOxford)
There are also various poster sessions happening today from 5PM - see the full schedule here: https://t.co/mMhrVPNlyc #ICLR2021
In addition to MT-Opt, we are releasing Actionable Models, which addresses the problem of defining tasks (which becomes quite cumbersome at scale). This work uses the dataset collected by MT-Opt but uses goal-conditioned offline Q-learning to learn a general goal-reaching policy.
Most RL agents assume that rewards are caused by recent actions, and learn slowly when this isn't true.
This new method speeds up learning in tasks with delayed reward by learning to link related events - regardless of how much time separates them.
https://t.co/aSSy43gCiN
Thrilled to announce our first major breakthrough in applying AI to a grand challenge in science. #AlphaFold has been validated as a solution to the ‘protein folding problem’ & we hope it will have a big impact on disease understanding and drug discovery: https://t.co/P53t2TxVRa
Everyone has heard about https://t.co/jug09Usgp7 or CS231n (for a good reason), but did you know you can access Stanford’s CS224w ML with Graphs or download the book Elements of Causal Inference for free? Thread on underappreciated ML resources 📚🎥 that deserve more love 👇 /1