@LiveOverflow There are some adjacent concepts. The attention sink token which is sometimes used as a "summary" token. Local/sparse attention which only uses semantics of a few adjacent tokens. SBERT is trained to output a token encoding a "summary" used for search.
Another episode of "nobody really understands deep learning", training on gibberish self inferenced trajectories improves LLMs, even when not filtered with any criteria.
@mgostIH for simple environments I 100% agree, search or Q-learning works fine on them, but what about POMDP? and what about predicting the environment representation like JEPA? basic RL becomes really inefficient really fast... that's why model based RL exists, despite it's flaws
New in Wirebrowser: Breakpoint-Driven Heap Search (BDHS) — step-out debugging + temporal heap snapshots to identify the user-land function where a JavaScript value is created, even across async boundaries.
Writeup: https://t.co/1pQAUX5zlj
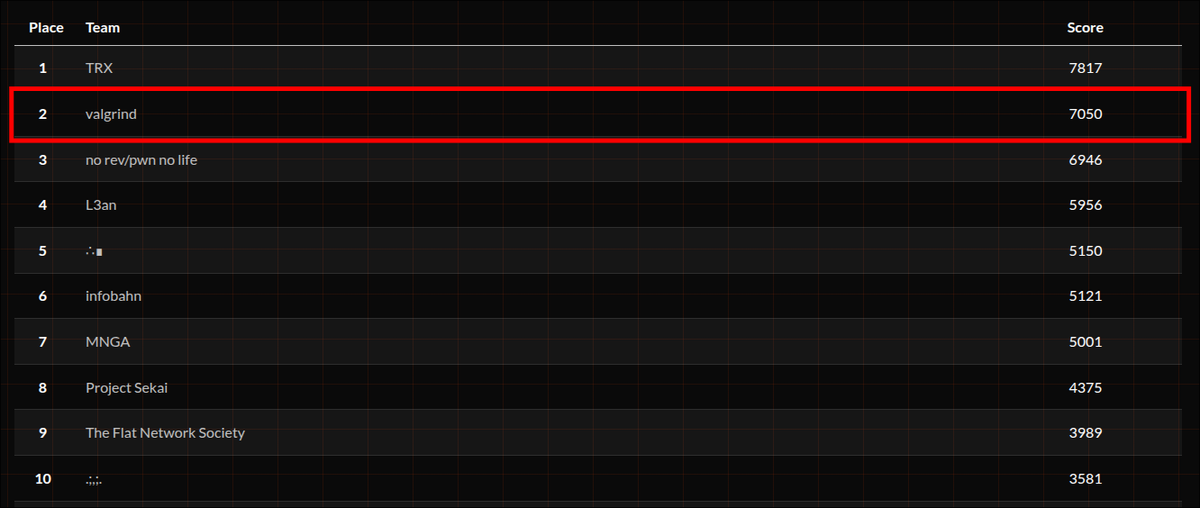
¡Enhorabuena a los ganadores del CTF del Megathon CyberChain!
🥇 @m2rc_p (5.330 pts)
🥈 @Dimitrovich702 (4.831 pts)
🥉 @stelin41 (4.831 pts)
🏆 Tres tarjetas de Amazon de 300€, 200€ y 100€ para vosotros. ¡Gracias al resto por participar!
#CátedrasCiber#NextGenerationEU
@fl0ct0 most of the students and researchers I know either share gpus or use cloud providers (usually google colab or smth similar to lambda labs). rn I'm fine with apple silicon for testing but tbh porting to mps often takes hours or days...
> decided to not play ctfs over the weekend to rest
> ended up fuzzing js engines instead
Well it was fun but I should actually chill next time challenge
@S1r1u5_ btw the actual reason the models you mentioned work well:
- Alphaproof is a neuro-symbolic system, which is one of the best current AI architectures. It combines heuristics with formal reasoning.
- AlphaGo uses heuristics (value and policy networks) to perform efficient search.
@SIGKITTEN@S1r1u5_ Not really. Even if you had to train the aligned model instead of the base (non aligned) one, the RL training process would naturally disalign it to improve performance. In fact that's a common problem if you are fine-tuning models and you want to keep it aligned.