Sharing some learning from attending MLSys '26. There were a lot of interesting papers presented in distributed training and inference. Overall, I could capture the following themes:
1. Distributed training has a lot of knobs, which are really tough to manage and tune. Ton of work is being done to make it easy to manage this.
2. As training gets larger, reliability matters more. It was not surprising to see many industry talks focus on training reliability.
3. Ultra-long context lengths are getting a huge mindshare for both training and inference.
4. Heterogeneous compute (multi-region, multi-accelerator) is on the rise and is probably the next frontier of inference optimization.
5. Distributed inference still needs better auto-tuning for finding the best configs at large scale.
6. KV cache optimization, attention optimization, and quantization were already on the radar, so the number of papers on these topics was not a surprise.
7. IMO, from a skills perspective, the best thing to learn is GPU communication and networking. Learn everything around inter and intra-rack communication, NCCL, and UCCL. Lots of improvements in the coming years will come from optimizing communication between GPUs via better kernels and frameworks.
For a list of interesting papers and their summaries: https://t.co/IY5p8PSeVQ
Had such a blast working with @erictang000 , @charlie_ruan, @sumanthhegde, and @pcmoritz on enabling multi-LoRA RL training in SkyRL! We observed ~3x higher experiments throughput in comparison to running experiments in the traditional single-tenant fashion. One of my favorite parts of this collaboration is that all this code is open source so you can play with it yourself :)
Here's the technical deep dive 🧵
I broke my record on the LLM I'm training by switching from constant learning rate to warm-up + decay (scheduled) learning rate.
Learning Rate Scheduling - Beginner Tutorial + Record LLM Speedrun
Full video - https://t.co/6UTQAsRxYt
At the start of training, the weights are far from optimal, so we use a high learning rate to make large updates and learn quickly. Later, as the model approaches a good solution, we reduce the learning rate to make smaller, more precise adjustments and avoid overshooting the optimum.
Speedrun our LLM - https://t.co/IaVf9nrX6m
Become AI researcher: https://t.co/pCxMtk6N9V (funds our compute)
One more checkmark and I feel more excited about the upcoming work in building my LLM inference server.
So far, it feels great implementing core techniques like separate prefill and decode, KV cache, prefill caching, etc. The upcoming things are more interesting: Torch Compile, CUDA Graphs, SD, Quantization, and Distributed inference.
Since I know these theoretically, implementing them one by one will be fun.
I recently completed my study on prefix caching, which involves block hash-based and radix tree-based approaches. I have also run some benchmarks with vLLM and SGLang and will make them public soon.
We just launched a new project that teaches you how to build Flash Attention with CUDA, step by step.
By the end, you’ll have a working Flash Attention kernel built from the ground up.
The project covers:
-CUDA primitives warm-up
-Matrix operations
-Naive attention baseline
-Online softmax math
-Tiled attention building blocks
-Fused Flash Attention kernel
-Causal Flash Attention
It will be open to everyone for the first 2 weeks, then it will become part of our premium projects.
I released MazuNIX on Mazu’s birthday. Unlike many educational operating systems that avoid SMP and real-time (RT) topics, Mazu delivers SMP, multicore RT scheduling, and practical POSIX Threads support.
Full source code is available: https://t.co/Ak8p7Kr9qr
I have joined @GoogleDeepMind!
I'll be training VLMs
And I'll still keep posting about latest developments on AI, Computer Vision and LLMs
So no more posts on PyTorch tricks. I might post about JAX. Stay tuned...
In 72 hours I got over 100k of value
1. Lambda gave me 5000$ credits in compute
2. Nvidia offered me 8x H100s on the cloud (20$/h) idk for how long but assuming 2 weeks that'd be 5000$~
3. TNG technology offered me 2 weeks of B200s which is something like 12000$ in compute
4. A kind person offered me 100k in GCP credits (enough to train a 27B if you do it right)
5. Framework offered to mail me a desktop computer
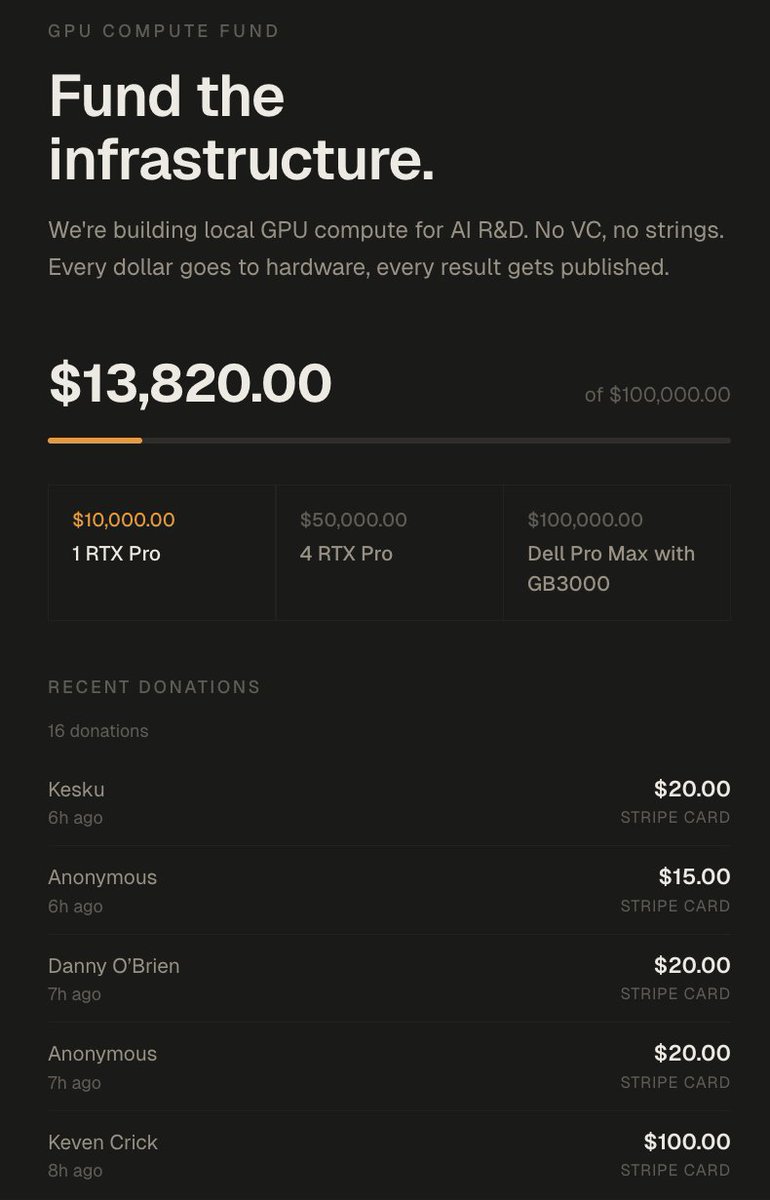
6. We got 14,000$ in donations which will go to buying 2x RTX Pro 6000s (bringing me up to 384GB VRAM)
7. I got over 6M impressions which based on my RPM would be 1500$ over my 500$~ usual per pay period
8. I have gained 17,000~ followers, over doubling my follower count
9. 17 subscribers on X + 700 on youtube.
The total value of all this approaches at minimum 50,000$~ and closer to 150,000$ if I leverage it all.
---------------------
What I'll be doing with all this:
Eric is an incredibly driven researcher I have been bouncing ideas off of over the last month.
Him and I have been tackling the idea of getting massive models to fit on relatively cheap memory.
The idea is taking advantage of different forms of memory, in combination with expert saliency scoring, to offload specific expert groupings to different memory tiers.
For the MoEs I've tested over my entire AI session history about 37.5% of the model is responsible for 95% of token routing.
So we can offload 62.5% of an LLM onto SSD/NVMe/CPU/Cheap VRAM this should theoretically result in minimal latency added if we can select the right experts.
We can combine this with paged swapping to further accelerate the prompt processing, if done right we are looking at very very decent performance for massive unquantisation & unpruned LLMs.
You can get DeepSeek-v3.2-speciale at full intelligence with decent tokens/s as long as you have enough vram to host the core 20-40% of the model and enough ram or SSD to host the rest.
Add quantisation to the mix and you can basically have decent speeds and intelligence with just 5-10% of the model's size in vram (+ you need some for context)
The funds will be used to push this to it's limits.
-----------------
There's also tons of research that you can quantise a model drastically, then distill from the original BF16 or make a LoRA to align it back to the original mostly.
This will be added to the pipeline too.
------------------
All this will be built out here: https://t.co/rHQUFdGfy4 you will be able to take any MoE and shove it in here, and with only 24GB and enough RAM/NVMe to compress it down. it'll be slow as hell but it will work with little tinkering.
------------------
Lastly I will be looking into either a full training run from scratch -> or just post-training on an open AMERICAN base model
- a research model
- an openclaw/nanoclaw/hermes model
- a browser-use model
To prove that this can be done.
--------------------
I will be bad at all of it, and doubt I will get beyond the best small models from 6 months ago, but I want to prove it's no boogeyman impossible task to everyone who says otherwise.
--------------------
By the end of the year:
1. I will have 1 model I trained in some capacity be on the top 5 at either pinchbench, browseruse, or research.
2. My github will have a master repo which combines all my work into reusable generalised scripts to help you do that same.
3. The largest public comparative dataset for all MoE quantisations, prunes, benchmarks, costs, hardware requirements.
--------------------------
A lot of this will be lead by Eric, who I will tag in the next post.
I want to say thank you to everyone who has supported me, I have gotten a lot of comments stating:
1. I'm crazy, stupid, or both
2. I'm wasting my time, no one cares about this
3. This is not a real issue
I believe the amount of interest and support I've received says it all.
https://t.co/aSLDkVhawQ