SkyRL now supports end-to-end vision-language post-training, from SFT to agentic RL, and adds vision model support to SkyRL’s Tinker interface! Existing multimodal cookbooks, e.g. VLM classification, work out of the box:
We just merged a clean Qwen 3.5 implementation for SkyRL's Jax backend: https://t.co/UgdEvQqADy Currently only for dense models, but should be easy to adapt to MoE models, contributions welcome! Also if anybody wants to contribute chunkwise training for the gated delta net or layer stacking for the model, it would be welcome!
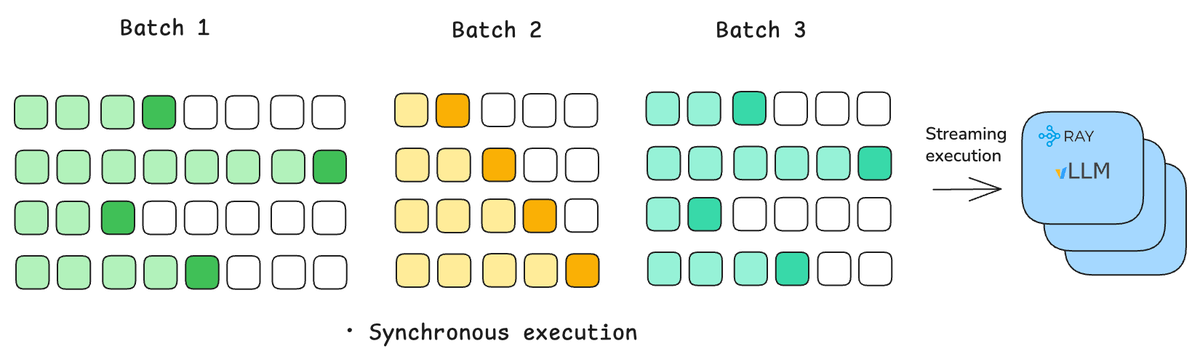
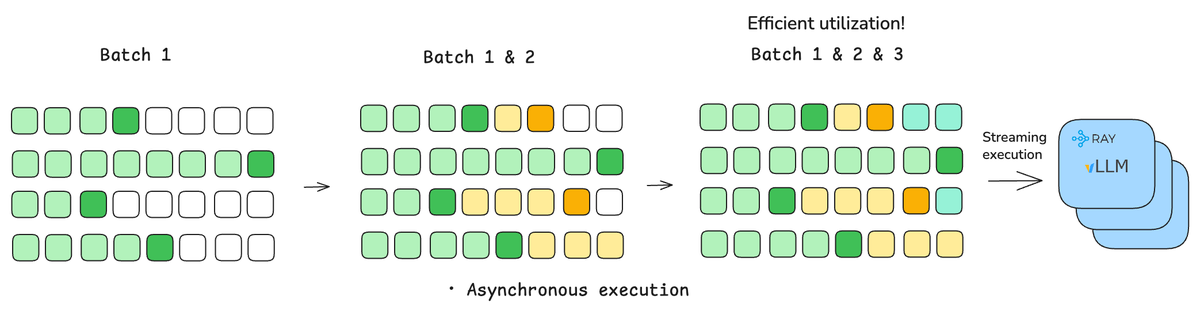
We just published how Ray Data LLM unlocks up to 2x higher throughput vs plain vLLM offline inference by fixing orchestration bottlenecks.
Offline batch inference is critical for synthetic data, evals, indexing – but vLLM alone doesn’t fully scale.
We compare:
• Plain vLLM
• Ray Data + vLLM offline engine
• Ray Data LLM 🧵
Releasing the official SkyRL + Harbor integration: a standardized way to train terminal-use agents with RL.
From the creators of Terminal-Bench, Harbor is a widely adopted framework for evaluating terminal-use agents on any task expressible as a Dockerfile + instruction + test script.
This integration extends it: the same tasks you evaluate on, you can now RL-train on.
Blog: https://t.co/yDyId02UfH
🧵
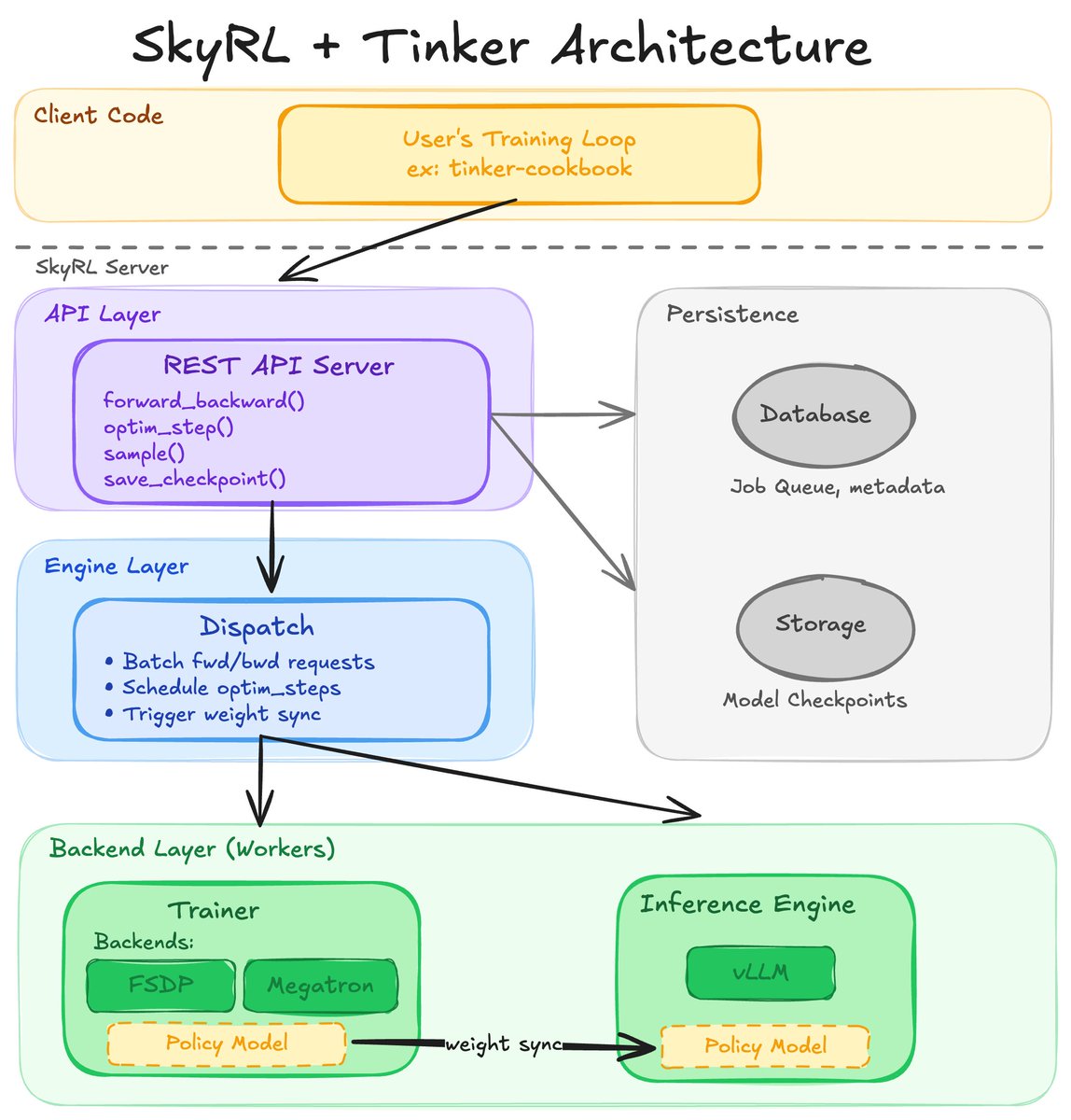
We just released the full SkyRL + Tinker integration: https://t.co/1cF7OR1m9t This is the evolution of what we have been working on with SkyRL tx and now also supports the SkyRL train backend (fsdp and megatron) which could previously only be used through Python APIs. I'm excited about the standardization the Tinker API will bring to the ecosystem and hopefully having a great open-source implementation will accelerate the adoption!
Yes I very much agree with you on the reproducibility, I'm just as excited about that as you! Standardizing hard part in the sense that it requires collaboration between many different people (everybody who writes training code) and is out of control of each individual project, so if there is something that can emerge as a standard like the Tinker API, we should rally behind it. I'm also very excited about exact reproducibility, and that IS within each individual projects scope so while technically not trivial, it is at least feasibly without requiring collaboration. I think the Tinker API can be made reproducible and while we haven't explicitly prioritized that yet (so there are no configs yet), we will going forward. If you run with the same package lockfile on the same hardware type with the same sharding, your results should be exactly reproducible, that will be the goal. I don't know yet if we will get there yet, but we will try hard.
You can now access SkyRL's backends for distributed training and inference with Tinker scripts so you can take advantage of Tinker's separation of infrastructure from training on your own hardware.
Exciting work from Tyler, @pcmoritz, and the team!
SkyRL now implements the Tinker API.
Now, training scripts written for Tinker can run on your own GPUs with zero code changes using SkyRL's FSDP2, Megatron, and vLLM backends.
Blog: https://t.co/GAtW81jM38
🧵
Hey Mert, the kernel I got working end-to-end is a CUTLASS kernel https://t.co/DvZKPhZ74w, I'm actually quite happy with it in terms of performance (it needs porting to some other architectures besides Hopper, which shouldn't be too hard). Tanmay got the pallas kernel working https://t.co/px32lLZGOT but afaik it is not auto-tuned and integrated yet. There is also a cutile-python implementation https://t.co/cG2KaGvwoy that Ago implemented. I'm planning to get one of these merged for the 0.3.1 release :)
We are excited to announce the release of SkyRL tx 0.3 https://t.co/NMzhSnlSnP, our MultiLoRA native inference and training engine that exposes the Tinker API. A lot has happened since the last release, in terms of big features we implemented expert parallelism, the DeepseekV3 model architecture (e.g. GLM 4.7 Flash) and a number of features to support longer context! Also, there are lots of smaller improvements and a few small bug fixes.
Thanks a lot for the call-out @tinkerapi For anybody who is interested, we have made a bunch more releases since 0.1.0 came out, they are listed in https://t.co/PRcKCyy068 (and 0.3.0 with expert parallelism, a bunch of long context optimizations, and DeepSeekV3 is coming very soon).
SkyRL-tx by @BerkeleySky is an open-source backend that implements the Tinker API itself, letting users train on their own hardware. It supports end-to-end RL, faster sampling, and gradient checkpointing — giving users flexibility and control.
https://t.co/FRX97DNf4p
If anybody is looking for a fun weekend project and is interested in kernels and how ragged_dot can be used to implement MultiLoRA for training and inference as well as MoE models, check out https://t.co/nnpwfV4LfE. Contributions very welcome, happy to discuss more in the issue!
We just pushed one of the biggest updates yet SkyRL tx (an OSS Tinker backend) including FSDP and multi-node support, custom loss functions, and Llama 3.
We also ran some comparisons to @thinkymachines Tinker service to validate tx. Check it out!
https://t.co/RhsYmu9Rka
Happy new year! We are excited to announce SkyRL tx 0.2.1, see https://t.co/ekRlMx5yxC. Some highlights of the release include FSDP and multi-node support, Llama 3 model support, custom loss functions, a number of performance improvements and also lots of small fixes that implement more functionality of the Tinker API. The blog post also includes a performance comparison with the Tinker Service! Enjoy the release and happy hacking!
@brianzhan1 For small / custom models, you might want to try out https://t.co/Q69C1dpsfl which is open-source and is working quite well now. You can use your existing Tinker scripts and customize it however you like and the code is quite readable.
We are happy to announce SkyRL tx 0.2, see our blog post https://t.co/bwn5kBtCf8. It comes with lots of performance improvements, all parts of the execution now use jax jit, so there is very little overhead. Now is probably the best time to try it out if you haven't already 🧸