This is a very good history of the DRAM boom/bust cycles:
"he product was a pure commodity, sold by the bit, indistinguishable across vendors. Five or six players were always willing to flood the market the moment demand softened. Every downturn turned into a price war, and every price war took out at least one company."
https://t.co/y5tChGqX4r
Westmag is building American robot actuators and drone motors at scale.
In 2025, @westmagco raised $11M led by @a16z, with participation from @FoundersFund, @LuxCapital, NFDG, @MenloVentures, and other top investors.
Since then, we’ve been building industrial capacity, crawling up supply chains, and securing high-volume customers.
Now, we’re ramping production at our factory in South San Francisco to deliver against committed offtake orders from high-volume customers.
Westmag is committed to scaling quickly in the US to deliver millions of drone motors and robot actuators to the surging domestic and global market.
We’re building the great American motor and actuator company.
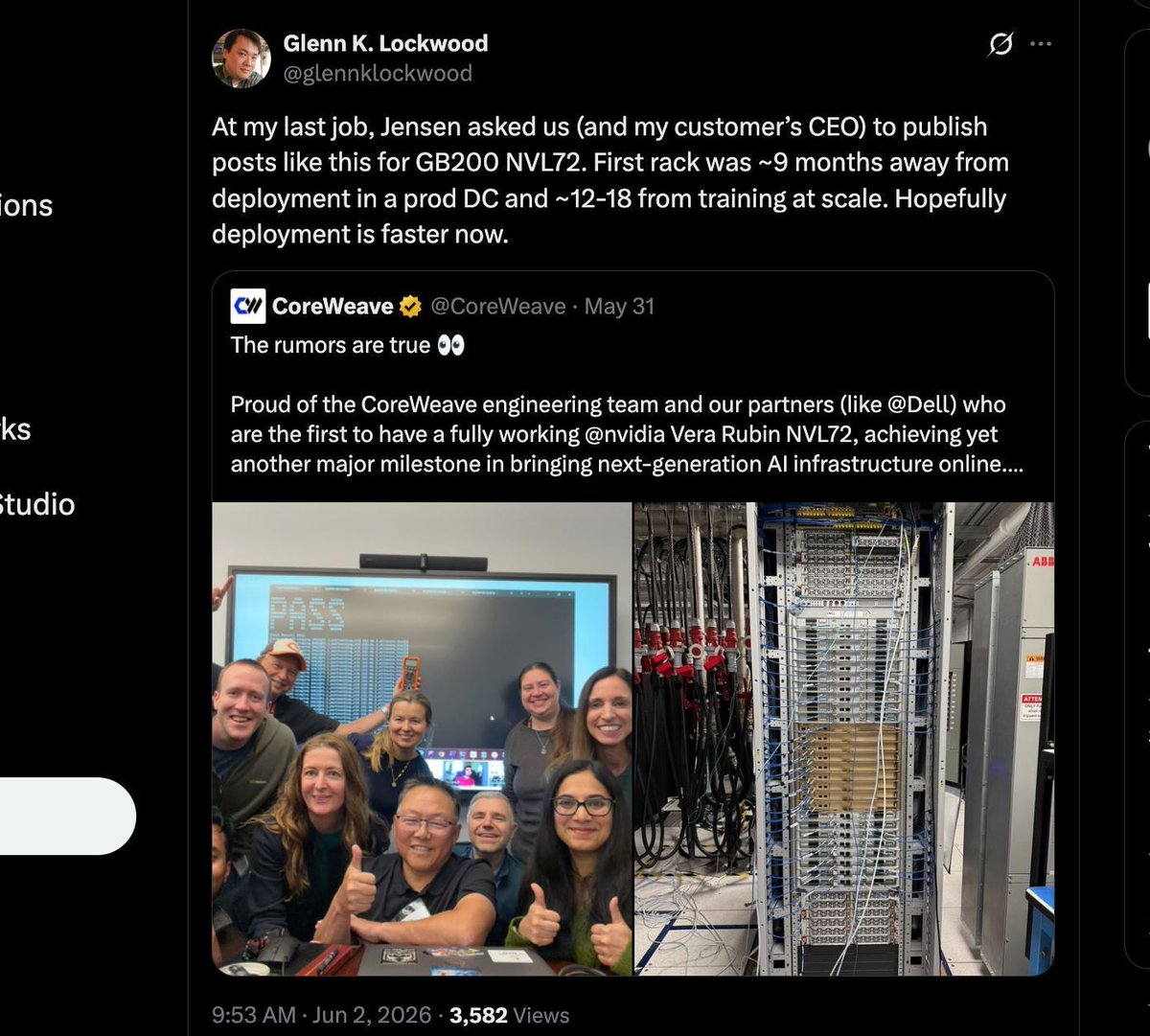
Add on a few more months before improved kernels and meaningful MFU. I write about why this is the case in my deep dive:
The Uncomfortable Truth Behind Deploying the Latest NVIDIA GPUs: MFU, Silent Data Corruption - https://t.co/dVOaFyegvN
IMPORTANT: it is important to understand that the CoreWeave & Microsoft photos are still Engineering/Quality Samples, and there is still some time before the software stack bring-up finishes & first production tokens are generated. The VR200 & MI455 rack metric to watch out for is time to first at-scale production token TTF-(ASP)-T. You can clearly see in the CW rack photos that none of the scale-out 800G OSFP cages are even populated.
I think Anthropic likely trained the Mythos base model from roughly October to December using on the order of 6.7e26–1.0e27 flops
Since then, the RL-to-base-model-training flop ratio is plausibly somewhere around 0.5 and 3, depending on how much of the expanded Trainium 2 fleet was actually allocated to Mythos RL.
The reason this range is plausible is that public AWS/Anthropic statements imply Anthropic-accessible Trainium2 capacity grew from roughly 500k chips around Rainier’s launch to over 1M Trainium2 chips for Claude training and serving.
Other winners in the NVLink Fusion story: $CDNS and $SNPS. In last year’s Computex keynote, Jensen announced that NVLink IP would be distributed through them. Of course, MediaTek and Marvell are also key partners, helping enable companies like Ayar Labs.
The future of computing (especially AI inference) is clearly heading toward heterogeneous architectures. The NVIDIA + Groq deal basically cements it. NVLink Fusion is NVIDIA’s play to protect its turf while embracing this shift.
My article on NVLink Fusion, AI Inference & Heterogenous Computing:
https://t.co/Gp4Zv6ZrW7
Jensen’s keynote where he announced NVLink Fusion and its partners:
https://t.co/MEPTghgNy6
Today, @AyarLabs announced it has joined the @nvidia NVLink Fusion ecosystem, introducing co-packaged optics as a foundational building block for hyperscalers and system innovators deploying heterogeneous compute in NVIDIA AI factories.
Press Release:
https://t.co/vNhVcHzLIA
The NVIDIA-MediaTek partnership is turning out to be quite the love story. I wrote this deep dive article on DGX Spark's GB10 SOC, MediaTek's role in it, and how exactly the chemistry between NVIDIA and MediaTek worked ... and even with NVLink Fusion, MediaTek is an essential partner.
GB10 SOC Deep Dive: https://t.co/9sEpTpngAg
NVLink Fusion & Heterogenous Computing : https://t.co/1v6t1fkdjD
If a baker makes a cake with their own recipe using ingredients from a mutual friend, then gives it to you, would you pass it off as your own?
Mediatek makes a CPU with their own recipe with arm ingredients and gives it to Nvidia.
Broadcom makes a TPU with their own recipe but with Google ingredients and gives it back to Google.
@citrini Don't blame you! Those of us in the semi-industry aren't used to this kind of exuberance :) . Like, $MU ... $1T?! Who woulda thought. https://t.co/WaDGhbbfZ1
@citrini Don't blame you! Those of us in the semi-industry aren't used to this kind of exuberance :) . Like, $MU ... $1T?! Who woulda thought. https://t.co/WaDGhbbfZ1
Micron has seen 6 boom & bust cycles since 2000. In 2019, hyperscaler over-ordering crashed their revenue from $30B to $21B. In 2023, the pandemic unwind cut it in half again, from $30B to $15B.
Has the AI super-cycle finally broken this pattern? Or is a reckoning coming? — especially since it's the same set of buyers, buying for the same reasons.
I analyze Micron through three lenses: Engineering, Finance, and Strategy. The current tailwinds, and the possible headwinds.
Full Article here: https://t.co/53dwpjc8d4
@theinformation I don't think anyone saw this abysmal 11% MFU number coming. I've written up a comprehensive technical report on why this happens and what it takes for ByteDance, DeepSeek, Meta, and Google engineers to squeezing their clusters.
https://t.co/BTvccrDBB7
Last week The Information reported that xAI’s Colossus-1 achieves a mere 11% MFU (Model Flop Utilization), compared to the 45-55% other hyperscalers achieve.
My latest article is a comprehensive analysis of:
+ What really is MFU and why is it hard to achieve, and where 50% of the FLOPs are lost — Communication bottlenecks, silent data corruption (SDC), and stragglers
+ Lessons from Google, Meta, ByteDance, and DeepSeek
+ Who does it best, and what's the "real moat"
+ The uncomfortable truth behind deploying the latest NVIDIA GPUs.
Full analysis here: https://t.co/qJPbrU4EZj
@zephyr_z9@basedjensen@teortaxesTex I don't think anyone saw this abysmal 11% MFU number coming. I've written up a comprehensive technical report on why this happens and how hard ByteDance, DeepSeek, Meta, and Google engineers work at squeezing their clusters.
https://t.co/dVOaFyegvN
@pernasresearch I don't think anyone saw this abysmal 11% MFU number coming. I've written up a comprehensive technical report on why this happens.
https://t.co/BTvccrDBB7
Last week The Information reported that xAI’s Colossus-1 achieves a mere 11% MFU (Model Flop Utilization), compared to the 45-55% other hyperscalers achieve.
My latest article is a comprehensive analysis of:
+ What really is MFU and why is it hard to achieve, and where 50% of the FLOPs are lost — Communication bottlenecks, silent data corruption (SDC), and stragglers
+ Lessons from Google, Meta, ByteDance, and DeepSeek
+ Who does it best, and what's the "real moat"
+ The uncomfortable truth behind deploying the latest NVIDIA GPUs.
Full analysis here: https://t.co/qJPbrU4EZj
@jukan05 I don't think anyone saw this abysmal 11% MFU number coming. I've written up a comprehensive technical report on why this happens.
https://t.co/BTvccrDBB7
Last week The Information reported that xAI’s Colossus-1 achieves a mere 11% MFU (Model Flop Utilization), compared to the 45-55% other hyperscalers achieve.
My latest article is a comprehensive analysis of:
+ What really is MFU and why is it hard to achieve, and where 50% of the FLOPs are lost — Communication bottlenecks, silent data corruption (SDC), and stragglers
+ Lessons from Google, Meta, ByteDance, and DeepSeek
+ Who does it best, and what's the "real moat"
+ The uncomfortable truth behind deploying the latest NVIDIA GPUs.
Full analysis here: https://t.co/qJPbrU4EZj
Last week The Information reported that xAI’s Colossus-1 achieves a mere 11% MFU (Model Flop Utilization), compared to the 45-55% other hyperscalers achieve.
My latest article is a comprehensive analysis of:
+ What really is MFU and why is it hard to achieve, and where 50% of the FLOPs are lost — Communication bottlenecks, silent data corruption (SDC), and stragglers
+ Lessons from Google, Meta, ByteDance, and DeepSeek
+ Who does it best, and what's the "real moat"
+ The uncomfortable truth behind deploying the latest NVIDIA GPUs.
Full analysis here: https://t.co/qJPbrU4EZj