Sometimes it takes years for an idea to work out.
I own my product's domain since 2013! Chased and failed multiple times. It was beyond what a solo founder could do.
Then came LLMs, they got better at code. I restarted my product. Fresh perspective and a decade of attempts.
@carldlfr@sudoingX Well said. We are already sliding down a slippery path with all the existing manufacturing and pressure from AI.
Also, I doubt things will change for better.
@ClementDelangue@Stanford This is something I try regularly and I am building for. I think smaller models need different harnesses and can unlock so much potential.
Since the big LLMs became popular we forgot that deterministic code used to be s3xy - fast, reliable. Sprinkle agent logic where needed.
A study from @Stanford showed that 71.3% of chatgpt queries could be accurately answered by a local model. I suspect a major part of enterprise AI workloads could be run locally too for free (compared to the massive costs of frontier API cost).
Also, it reduces the risk of these workloads being taken away from you because you own the models instead of renting them - which sounds like a good idea these days haha.
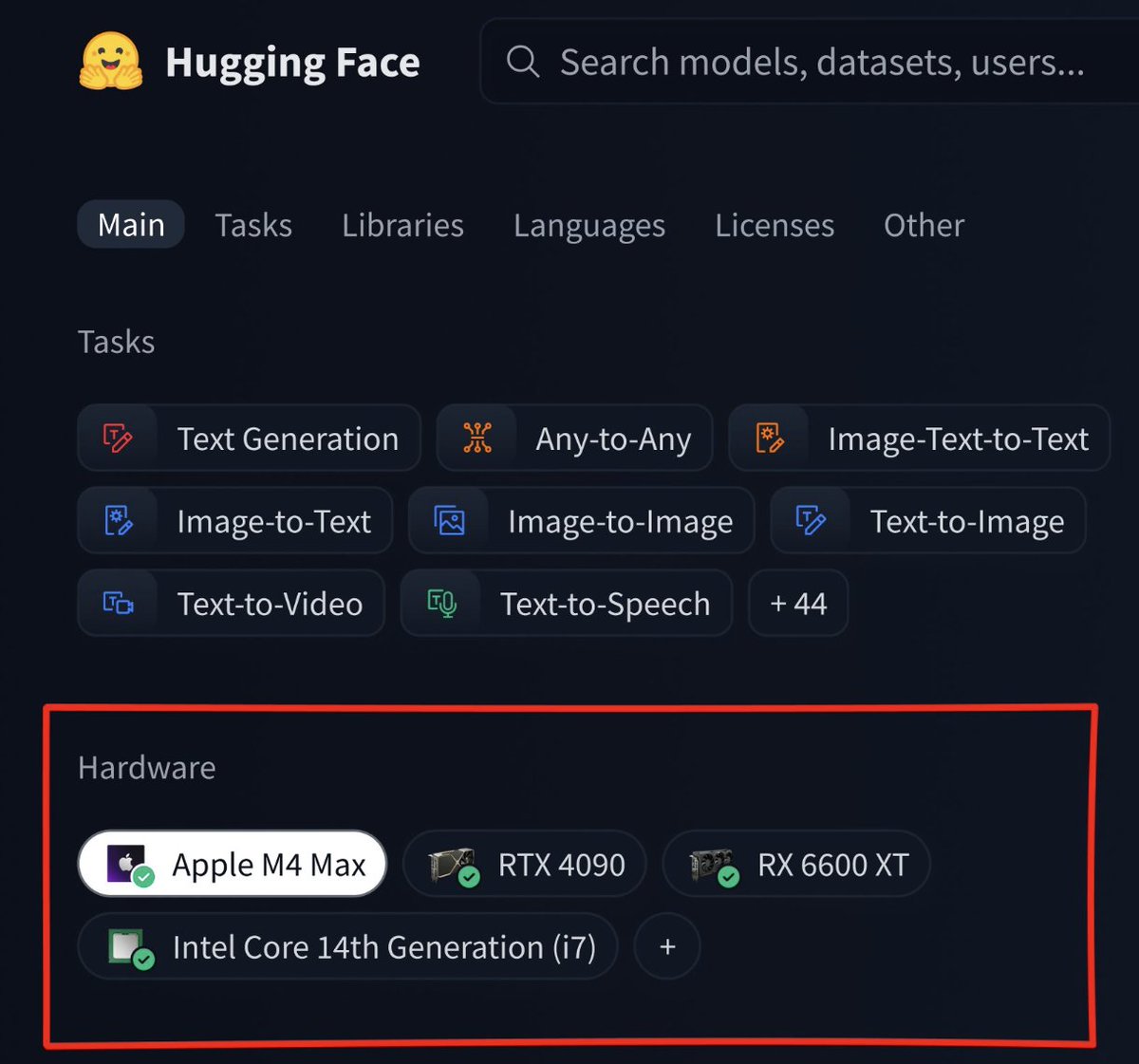
That's why we're introducing the ability for everyone to filter AI models on @huggingface based on your local hardware.
For me, there are 800k+ public models that fit on my M5 24GB and that I can use easily thanks to llamacpp.
Let's go local AI!
@sflorimm Not everyone can buy the hardware. I cannot. But I can rent. So a p2p network to run inference is good solution right?
Like vast but more like SETI@home. I choose LLM and expected TPS within a budget and start sending requests to someone's idle GPU.
@Star_Knight12 Closed sourced models were not free when they were Sonnet 4, GPT 4 or Opus 4 levels.
Open weight models reached Sonnet 4 levels and lots of people use them for free. 6-9 months delay.
This has happened many times now that I believe it will continue to happen, but we shall see.
@Hikari_07_jp I am building a coding agent for small/tiny LLMs.
Almost no tool-calls in most of the agent flows. No skills or MCP. An opinionated tech stack and deterministic paths. One-shot prompts with examples to generate specific parts of a CRUD app.
https://t.co/Hbszk77hxl
@MiaAI_lab If the model is bad at tool calling but good at reasoning, I am going to love it.
There are other ways to build agents that avoid tool calling.
Big step for local LLMs!
I am particularly interested in 9B model. Going to try this with https://t.co/Hbszk77hxl
Currently busy building a decision provenance graph - PRD to business logic expressed in FSMs and verify provenance statically.
Ornith may be the default LLM.
Aloha! 🌺 Meet Ornith-1.0, a family of open-source LLMs specialized for agentic coding.
Ornith-1.0 spans the full parameter sizes including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art performance among open-source models of comparable size on coding benchmarks including:
✅Terminal-Bench 2.1(77.5)
✅SWE-Bench(82.4 on verified, 62.2 on pro, 78.9 on Multilingual)
✅NL2Repo(48.2)
✅SWE Atlas(41.2 on QnA, 42.6 RF, 39.1 TW)
✅ClawEval(77.1)
Post-trained on top of gemma4 and qwen3.5, Ornith-1.0 employs a novel self-improving training strategy in which reinforcement learning is used to generate not only solution rollouts, but also the task-specific scaffolds that drive those rollouts. By jointly optimizing the scaffold and the resulting solution, the model generate higher-quality solutions in agentic coding.😎
All models are released under the MIT license, enabling full commercial and research use.
📖Tech Blog: https://t.co/qT9N2HYWFn
🤗Huggingface: https://t.co/PRrwqjeBtM
@hxtxmu@david_nix If you have a background assistant does it matter if your chores are being done at 1500 tps?
If you are interacting, yes it matters. But so much processing will be background if we think of a future where every single business or power user has their assistant.
Somewhere out there is a founder who automated half their company with AI agents and has literally nobody to talk to about it.
Building a room for exactly that person. Invite-only, vetted. Apply here:
@alexocheema I am seeing Tweets, signed up for access. Please let this not be a marketing trap.
I am building https://t.co/Hbszk77hxl - coding agent for small, local models only. I don't know where it will end up but it is fun to see 0.8B-4B models writing code! Stack constrained though.
@ItsmeAjayKV Depending on your ask, small models can punch way above their weight. I am creating a coding agent that is stack focused - agents for Model, Schema, Controller, Auth, Permissions, etc. Then agents for frontend. Even 0.8B model shows promise this way.
https://t.co/Hbszk77hxl
@KyleHessling1 I'm building a coding agent with (Qwen or other) 0.8B - 9B models. I'm looking at MTP, have'nt tried. Qwopus looks fantastic and if Jackrong has a 9B version, I will try.
Is @NousResearch Hermes focused on small models?
I am doing that, but very early: https://t.co/Hbszk77hxl