I just published Slate — a fast, light-weight OLED-friendly Markdown/text editor.
It supports editing all types of text-based files.
One thing I really wanted: a proper OLED-friendly editor. Not “dark gray” — complete black, so it looks great on OLED displays and feels easy on the eyes at night.
Fully developed by local AI.
Currently Windows only. Feel free to fork and build for Mac/Linux.
Feel free to test it, open issues, report bugs, or suggest ideas.
https://t.co/KImPGEHmvp
@advented_ Do you mean single session? Unfortunately I'm not getting 40-50 t/s, it was unstable. My recipe gets me to 31.7 t/s for single session.
For multiple sessions I get up to 80 t/s
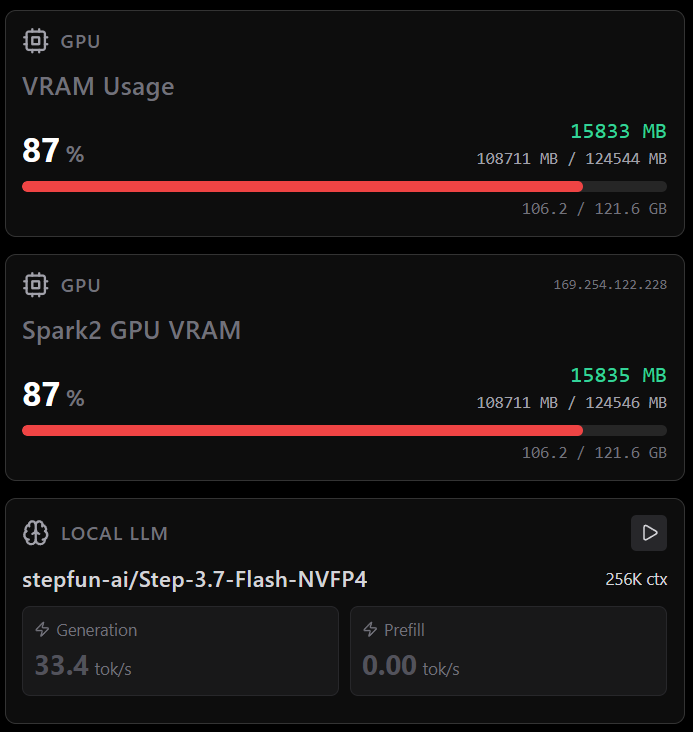
Final results for are in. 53k tok/s is NOT stable. Had to do some tunings to make it work.
Eventually the best results are around 33 tok/s.
This is Step-3.7-Flash nvfp4 MTP & no --enforce-eager.
Repo will be published in a few hours.
Finally cleaned up and published my Dual DGX Spark setup for Step-3.7-Flash-NVFP4.
The repo includes scripts for 2x DGX Sparks, vLLM, no-MTP first, optional MTP grafting, live logs during startup, background serving after ready, plus stop/status/test helpers.
~33 tok/s, even when in deep context.
Hopefully saves someone else a few hours of pain 🙂
Repo: https://t.co/10QcqYKK9Q
We heard you wanted to use Codex rate limit resets on your own time.
Starting today, we’re rolling out the ability to save rate limit resets to use later.
We’re starting Go, Plus, Pro, and Business users with one free reset:
Congrats to the @MiniMax_AI team on the release of MiniMax M3, a long-context multimodal model for text, image, and video reasoning. 🙌
Try it today with our free GPU-accelerated endpoint on https://t.co/es07MrU5I0.
Details: https://t.co/89qlcTP3OW
For the price of 2x DGX Sparks you can run frontier open models with full context in very decent and usable speeds for agentic coding.
30-45 tok/s on frontier models, NVFP4 + MTP.
No usage limits.
I don't think there is any better deal out there for 256gb available vram.