📊 More insights on GPT-5.5 vs Opus 4.8 based on SWE-rebench runs
TL;DR: Opus 4.8 became much more token-efficient than 4.6, but GPT-5.5 is still the most efficient: more solved tasks, fewer tokens, fewer steps.
🏆 SWE-rebench is a live benchmark with fresh SWE tasks (issue+PR) from GitHub.
Detailed table of the results and the leaderboard link are in the thread.
Findings:
> GPT-5.5 medium looks noticeably more efficient than Opus 4.8 high, if we compare the default reasoning-effort modes for both models.
> Opus really became much more optimized from 4.6 → 4.8 on high: more solved tasks, 45% fewer tokens per task, and around 39% lower cost/problem.
> Opus 4.8 high is almost not better than Opus 4.7 high by score, but it is much cheaper in compute. Tokens/task went down 1.53M → 1.01M, and steps went down 43.7 → 34.2.
> GPT-5.5 medium also became more token-efficient than GPT-5.4 medium, but more expensive because the base pricing increased.
Tokens per task went down by 15%, score increased, but the cost of solving a task increased by 63% while base pricing increased 2x.
Another useful metric, when you have several runs, is pass^5. Here we count a task only if it was solved in all 5 runs.
For GPT-5.5 medium, pass@5 almost did not change compared to GPT-5.4 medium: 77 vs 78.
> But pass^5 increased a lot: 51 vs 39! This means GPT-5.5 medium solves tasks “randomly once” less often, and much more often solves the same task consistently in all 5 runs.
For Opus, this number is almost the same between model versions, but it changes a lot depending on reasoning mode: high → xhigh.
> Many people ask why GPT-5.5 xhigh gets a higher score than medium, or why one model beats another on these tasks. On the surface, it looks like one model solved the task and another did not. But usually it is not a full failure. Very often the model gets to an almost correct solution, but misses some edge cases or corner cases covered by tests.
In xhigh reasoning, GPT makes many more steps to explore the repository and more actively tests its own solutions, including writing additional tests. This helps to catch these corner cases, but the price is high.
GPT-5.5 medium: 58.9% → 62.7% pass@1, $0.98 → $2.25
> GLM 5.1 looks competitive by pass@5, but it has a very heavy trajectory. So I believe that it could be RL’ed to get even better results in terms of pass@1 and more efficient token count, like Composer 2.5, for example.
P.S
Please write if you have questions, or what hypotheses we should check on trajectories. We are working on releasing all the trajectories, so you can do some analysis on them as well
deepswe bench is the best benchmark in the world right now.
and openai crush it.
and 5.6 is leaps ahead of 5.5.
opus is a cute chatbot companion though, such depth.
SoftBank’s commitment marks the largest AI investment by Masayoshi Son’s group outside the US and delivers a boost to Emmanuel Macron ahead of the French president’s Choose France event next week, an annual gathering of dealmakers and executives.
https://t.co/9GWbpHUCbu
Found a way to save everyone 14% on input tokens on average during read file operations in Hermes Agent!
This is now on main. `hermes update` to access now.
Who said you can't have cheap, fast, and good at the same time??
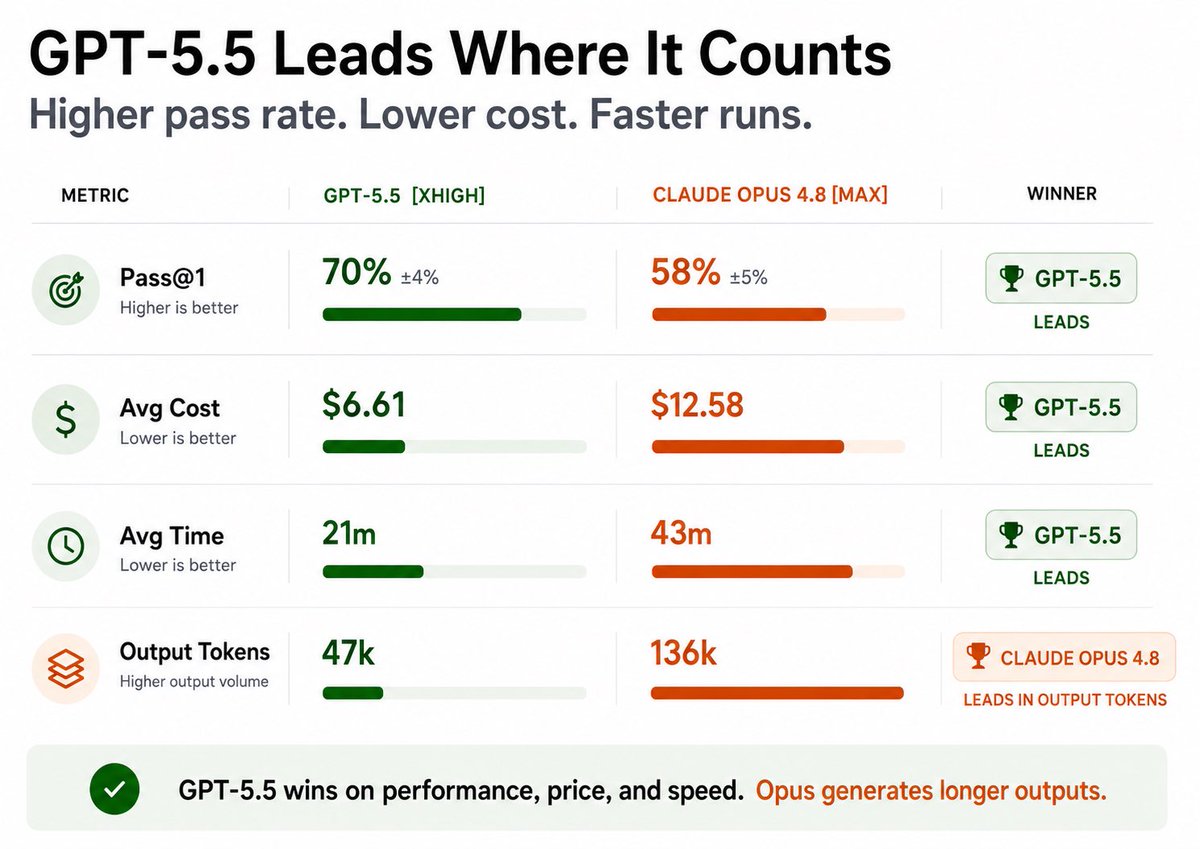
GPT-5.5 smashes Opus 4.8 on DeepSWE across all 3 at highest max reasoning.
>> Higher score: 70% vs. 58%
>> 2x faster
>> 2x cheaper
>> 3x fewer output tokens
5.5 high still beats 4.8 max 62% vs. 58% while being 3x faster and 3x cheaper
That matters beyond software engineering. In life sciences, better models can help teams use scarce researcher time, budget, and experimental capacity more efficiently, find results sooner, and make more patient impact, faster.
And we are just getting started.
Claude Opus 4.8 has landed on DeepSWE Bench, posting a 58% Pass@1 and taking #2 overall behind GPT-5.5.
It continues a broader trend: slightly behind on raw score, but among the most reliable and efficient coding models across recent benchmarks.