Give your agent a memory that holds up past the fiftieth markdown file.
OpenClaw stores everything your AI agent has ever logged as plain markdown. Readable, portable, and completely unsearchable once the folder hits critical mass.
Grep finds the word you typed. SIE finds the meaning you remember.
Slot SIE in as the semantic memory layer and your agent can ask "what did we decide about the retry logic last Tuesday" and get the actual chunk back.
Local embeddings, content-hash deduping, and no re-embedding the bits that haven't changed.
Follow the build here: https://t.co/ZgLhDKby4V
@grok@JimPanehal@hasantoxr Btw it’s not just embeddings - there are other models like OCR, scoring models, entity and relationship extraction models.. and soon generative models also.
I'm replacing OpenAI, Cohere, and AWS Comprehend with one open-source server.
It's called SIE.
One docker run gets you 85+ models behind three API calls:
→ encode() for embeddings (Stella, BGE-M3, SPLADE)
→ score() for reranking (BGE-reranker v2)
→ extract() for named entity recognition (GLiNER, Florence-2)
The cost difference is brutal.
AWS Comprehend entity extraction → $5,000/month
Same workload on a spot A10G with SIE → $5/month
That's the same models, your own cloud, and a 1000x cheaper bill.
It ships the full production stack out of the box:
→ OpenAI-compatible /v1/embeddings (swap the base URL and you're done)
→ KEDA autoscaling on Kubernetes
→ Terraform modules for GKE and EKS
→ Grafana dashboards
→ All 85+ models quality-verified against MTEB in CI
Native integrations with LangChain, LlamaIndex, Haystack, DSPy, CrewAI, Chroma, Qdrant, and Weaviate.
Your data never leaves your VPC.
Apache 2.0. Built by Superlinked.
We just launched native @trychroma support for the Superlinked Inference Engine.
If you're using ChromaDB, you can now use SIE as your embedding function with a one-line swap.
That gives you access to 85+ SOTA models, including sparse embeddings for Chroma Cloud's hybrid search and multimodal models like CLIP for image search, all running in your own cloud.
pip install sie-chroma
Check it out in our docs: https://t.co/pBhQkZtkbj
Clone our latest SIE example and you have a full product search engine running on your laptop in five minutes.
Type “wireless bluetooth headphones”, get ranked Amazon products back with extracted brand, color, and material filters. All three capabilities (extract, encode, score) run on one local SIE server through three SDK calls.
No vector DB to provision. No separate reranker service. No hand-rolled regex for attributes.
One Docker container, one SDK, one pipeline.
Sounds impressive? Go have a look at the full build: https://t.co/5QjSZPZHT4
We just launched native @Weaviate support for the Superlinked Inference Engine.
The interesting one here is SIEDocumentEnricher. It combines embedding with entity extraction and classification at index time, which means Weaviate's Query Agent gets a rich metadata surface to work with.
So a natural language query like "show me legal documents mentioning Google" resolves into the right vector search plus filters automatically.
pip install sie-weaviate
Check it out in our docs: https://t.co/rTckaspyl7
Just watched this talk from @f_makraduli
It is very interesting because it highlights a key takeaway: specialised models outperforms LLMs for specific tasks (routing, retrieval, reranking), but serving them is challenging because it is less explored and there are a lot of different models/architecture/inputs/outputs
As someone who worked on serving my two loved ones (ModernBERT and ColBERT), this resonates!
Most embedding infrastructure assumes you know exactly which model you want ahead of time.
This talk starts where that assumption breaks.
@f_makraduli walks through the real profiling mistakes, infrastructure gaps, and production constraints that led to building an embedding inference engine designed for dynamic model loading, hot-swapping, and memory-aware eviction instead of brittle one-model-per-container deployments.
If you're working on small-model inference, embeddings, or GPU infrastructure, this is a practical look at what breaks in the real world and how to design around it.
Check it out here: https://t.co/U6TpFWUwSm
Dive into the SIE repo here: https://t.co/pmhnjmTrBv
We're now a native Haystack integration.
The sie-haystack package gives you SIE embedders (dense, sparse, ColBERT, image), cross-encoder rerankers, and zero-shot extractors as first-class Haystack 2.0 components.
Everything routes through one endpoint, so you can build a full RAG pipeline, swap models with a config change, and not spin up new infrastructure for each one.
pip install sie-haystack
Check it out in our docs: https://t.co/7dbt0C9aK0
We sometimes hear clients talking about running 700B parameter models, but most AI tasks don’t actually need them!
A huge amount of real-world work can be done with small, task-specific models. Instead of forcing one giant model to do everything, you combine a few specialized models together to solve the problem.
Because these models are only a few billion parameters, they fit comfortably on standard 16–24GB GPUs. That means lower latency, dramatically lower cost, and infrastructure that is much easier to run in your own cloud.
This shift toward Small Language Models is a big part of what we discuss in our latest guest appearance on the AI Powered Search , where @svonava gives a preview of the Superlinked Inference Engine and how we think about running many models in production.
If you are building AI systems today, it is worth asking whether the biggest model is really the right tool for the job.
Thanks to @treygrainer and @softwaredoug for having us!
How long does it take your team to get a new model into production?
If the answer is anything more than a config change, @f_makraduli 's talk at AI Engineer Europe is worth your time.
On April 10th, Filip will walk through the small-model infrastructure problem we kept finding one layer deeper than expected, and what we built in response.
The short version: five small models should not require five GPUs running at single-digit utilisation. A new model on HuggingFace should not require days of Docker builds and infra tickets. And the gap between a working model server and a production system that scales, monitors itself and costs nothing when idle should not require months of in-house work.
We fixed all three. Come find us in London to find out how.
https://t.co/iExKIRzpx5
#AIEngineer #Embeddings #MLOps #OpenSource #Superlinked
We would like to announce that our co-founders Daniel and Ben have launched a side hustle.
SUPER INKED Tattoo Studio will be opening its books to paying customers April 1st at 12pm PST.
That’s right, they dropped the L, because in this business *we don’t take no Ls.*
Ben has 1 month of experience with a tattoo gun and has been using Daniel as a test-dummy on a daily basis.
We call his technique “vibe tatting” and so far the results have been great, enabling Daniel to fulfill his dream of having an entire arm sleeve of vague illegible scribbles.
SUPER INKED can be trusted to produce the best quality, definitely not AI-generated flash sheets, with designs that will be professionally embedded, just like a vector (but more permanent) into your skin by one of our tech-team-turned-tattooists.
Like this post for 50% off face tattoos!
Right now SO many companies are paying per token for LLM APIs.
At scale, that gets expensive very quickly.
What’s interesting is that in many cases there are open models with similar capabilities that you can run yourself. The difference is that instead of paying per token, you are paying for GPU infrastructure.
The gap between those two models of pricing can easily be one or two orders of magnitude.
That is why more teams are starting to look seriously at self-hosting. If you can run the models reliably in your own environment, the cost savings become hard to ignore.
@Svonava talks about this shift and why infrastructure for running many specialized models efficiently is becoming an important part of modern AI systems.
The self hosting small models is an increasingly emerging topic as of late, but where's the evidence?
The team was in Belgrade last week, presenting alongside @TopK and @Perplexity, answering that exact question.
@f_makraduli presented "The Case for Self-Hosting Small Models". *TLDR: Small models are quietly winning in production AI.*
Open source has exploded to over 2.6M models, and open-weight systems are now only about 1 to 3 months behind proprietary frontier models. In some cases, they already match top-tier performance at a fraction of the cost
At the same time, task-specific models consistently outperform general LLMs where it matters. They are faster, cheaper, easier to run, and trained on more relevant data. That is why they power things like search, ranking, and extraction in real systems today
It appears the future is not one giant model, but many smaller models doing specific jobs to a better standard.
Thanks to @KayaVC for the invite!
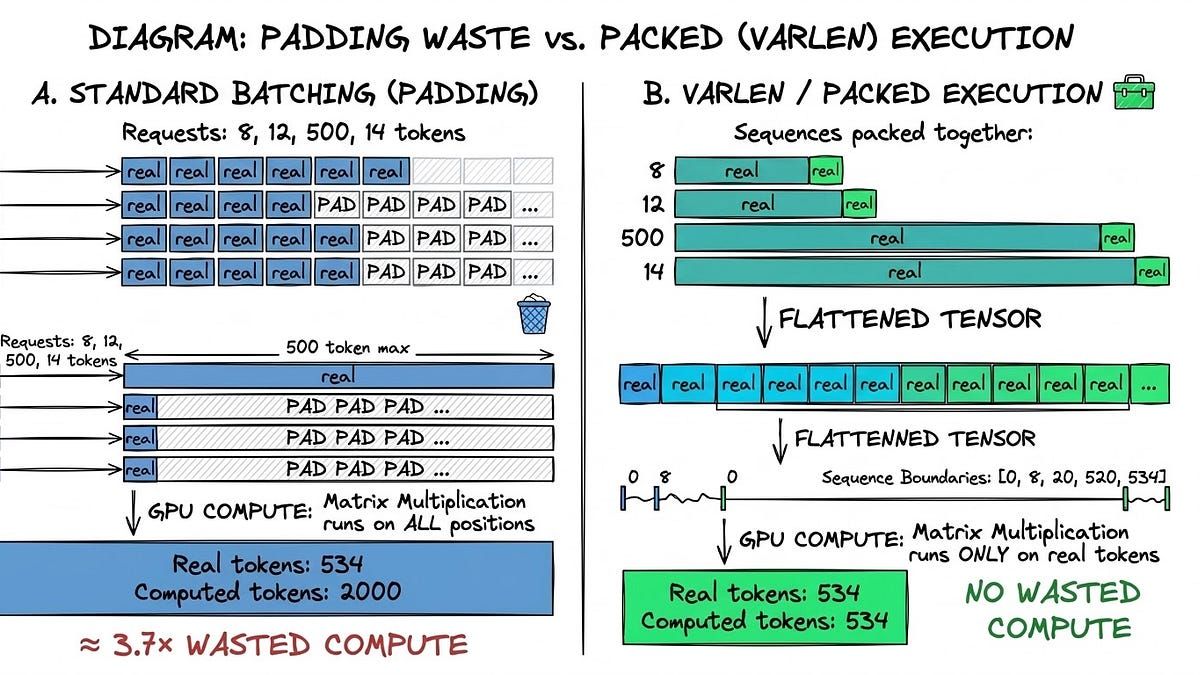
GPUs can deliver hundreds of TFLOPS, so why are they often underutilised during inference?
Because the real constraint is often memory bandwidth, not compute.
With small batches, GPUs spend much of their time waiting for data to move through memory. The compute cores sit idle because weights and activations cannot be fetched fast enough.
Increase the batch size and things start to change. Memory access becomes more efficient, the GPU stays busy doing matrix multiplications, and the bottleneck shifts from memory bandwidth to raw compute.
That transition is key to understanding why batching matters so much for inference performance.
Filip's article breaks down this shift clearly and explains how it shapes real world GPU utilization.
Check it out here:
https://t.co/1GPiK9CcHa
If you are running search or large scale data processing, you have probably experienced:
-Rising API costs.
-Experimenting until something breaks in production.
-Memory constraints and throughput ceilings that block real workloads.
We're working on an alternative...
On Feb 27 at 4 PM GMT, @Svonava will preview the Superlinked Inference Engine, our open source software for running Small Language Models in your own cloud.
Join us on Maven Live for Optimizing Search & Data Processing with Self-hosted SLMs.
We’ll cover:
• When SLMs beat LLMs for search and data tasks
• How to support 35+ model architectures and LoRAs in production
• Designing a multi model cluster pushing 1M tokens per second
• How teams cut 95%+ of managed API costs
Daniel will be joining AI-Search masterminds @treygrainger and @softwaredoug for this free lightning lesson!
Join us here: https://t.co/v7tnD6XVUh
“System X is fast because it’s written in Rust.” Is this true 100% of the time?
Most people assume embedding inference speed comes down to the code they write. Python versus Rust, frameworks etc. In practice, almost none of that is decisive.
What really affects embedding latency is memory. GPUs are extremely fast at calculations but comparatively slow at moving data. Generating an embedding is mostly about reading and writing large model weights and intermediate tensors instead of crunching numbers.
That is why techniques like Flash Attention (used by popular inference model TEI) matter. They reorganise computation so more work stays in fast on chip cache instead of repeatedly hitting slower GPU memory. Quantisation helps for the same reason. Smaller weights mean less data to move.
If you want faster embeddings, start thinking about memory, cache locality, and data movement to realise some actual gains.
Or better yet, read Filip’s full deep-dive on the matter here: https://t.co/zfjbsCakiq
Using open-source solutions to productionise your embeddings can get you a long way, but the efficiency problem that faces ML and AI Engineers still needs solving…
*Some models can generate dense, sparse, and multi vector embeddings in one pass, but today you usually need multiple API calls because these outputs are handled separately.
*Running and testing multiple models in production is costly and complex, with limited support for serving many models efficiently when VRAM is constrained.
*Differences in embeddings, pooling strategies, and model quirks require careful handling by users, and current systems lack flexible ways to support new model types without code changes.
@f_makraduli takes a deep dive into the existing open source inference solutions, what they do well, and what they’re ultimately missing to make everyone’s jobs easier (and to get the most out of your GPUs).
Check out the article here: https://t.co/5PWQfGyiZV
Problems with your text-embedding models?
Filip explains the common issues with the traditional approach to search + embeddings.
Superlinked has a smarter approach, using a MIXTURE of embeddings instead. Check out the video to find out more.
Think you know the vector embeddings space well? Think again! Your embeddings are wrong!
@Svonava will open the hood on today’s “state-of-the-art” text and image embeddings at GenAI Week 2025, Silicon Valley on Thursday 17 July, 2:00 – 2:40 PM (PT).
Why attend?
See the breaking point: examples of pre-trained embeddings failing on tasks that look trivial on paper.
Learn how the big players fix it: a peek into FAANG-style models that fuse dozens of real-world signals (price, location, co-purchase graphs, margins and more).
Walk away with a blueprint: a Mixture-of-Encoders strategy you can replicate without a research lab.
Two case studies:
A fashion retailer that unlocked seven-figure incremental revenue.
A jobs marketplace that boosted matching quality while cutting infra costs.
If you build search, recommendations or retrieval pipelines, this session will save you months of trial and error.
👉 Register here https://t.co/YcLMCyt07u and add our keynote “Your Embeddings Are Wrong” to your schedule.
Follow Daniel for the chance to get your hands on free tickets to the conference.
See you in Santa Clara! 🎟️
hashtag#AI hashtag#GenAI hashtag#VectorSearch hashtag#RecommenderSystems hashtag#MachineLearning