The new Qwen3.6-27B now runs on Luce DFlash. Up to 2x throughput on a single RTX 3090.
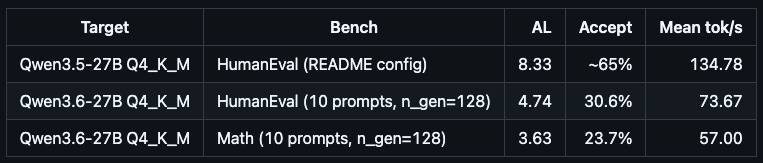
Qwen3.6-27B ships the same Qwen35 architecture string and identical layer/head dims as 3.5, so the existing DFlash draft + DDTree stack loads it as-is.
Throughput is lower than on 3.5. Looking forward for the updated version from the DFlash team to implement it as well!
Repo in the first comment ⬇️
@doodlestein@benhylak I second Jeffrey here. Was not a big fan of opus 4.6, but I'm getting much better results with 4.7. At least in complex mobile/front-end stuff.
@O_Pawica This looks great Oskar. Are the elements in the header tappable/can you scroll by dragging the items in the header? I've got a similar solution but those conditions are wonky.
@chamath If you have your AI chats on your machine via something like codex, claude code, etc, you can easily create a watcher for each of their chat history folders and have it extract int your knowledge base. You can then run tasks periodically to summarize/cache based on your needs.