We've been having so much fun building @zerorandom_ as an experiment in hypercustomization and AI-driven businesses.
It's amazing how the agent can craft genuine humor and clever wordplay. Just look at this meme—it used Kafka's Metamorphosis to joke about Meta 🦋
Introducing @zerorandom_, our first experiment in building an AI-run business
ZeroRandom is an autonomous agent with one mission: hustle
💡 It scans and engages with Tech Twitter
🔥 Turns hot takes and drama into memes
👕 Drops exclusive t-shirts with its best jokes
December is my month without social networks (but WhatsApp because I have a family 🤣)
I ve been doing this for 5 years and it’s painful and refreshing at the same time.
Painful because you notice the addiction, refreshing because you use the extra time on other interesting things.
The main problem this year is that I’m already using most of my willpower on eating well, it’s still a pain after 3 months and I need to control myself when I see any kind of unhealthy food. That’s on top of starting up a company and other personal shit going on.
I write this now because having some days of mental prep are fine, also have the chance to talk to other people who do something similar.
I’m doing it anyway, I may set a different focus on the things I do this year but it worths
This piece by Sean Goedecke is just fantastic. Shipping in big (and small) companies is a one of the most important traits in the cultural folklore.
I really love this part.
It's not just that Python is no. 1, but it's growth is still accelerating — it's also the fastest growing language!
And (together with TS) Python is miles ahead of other languages in terms of growth.
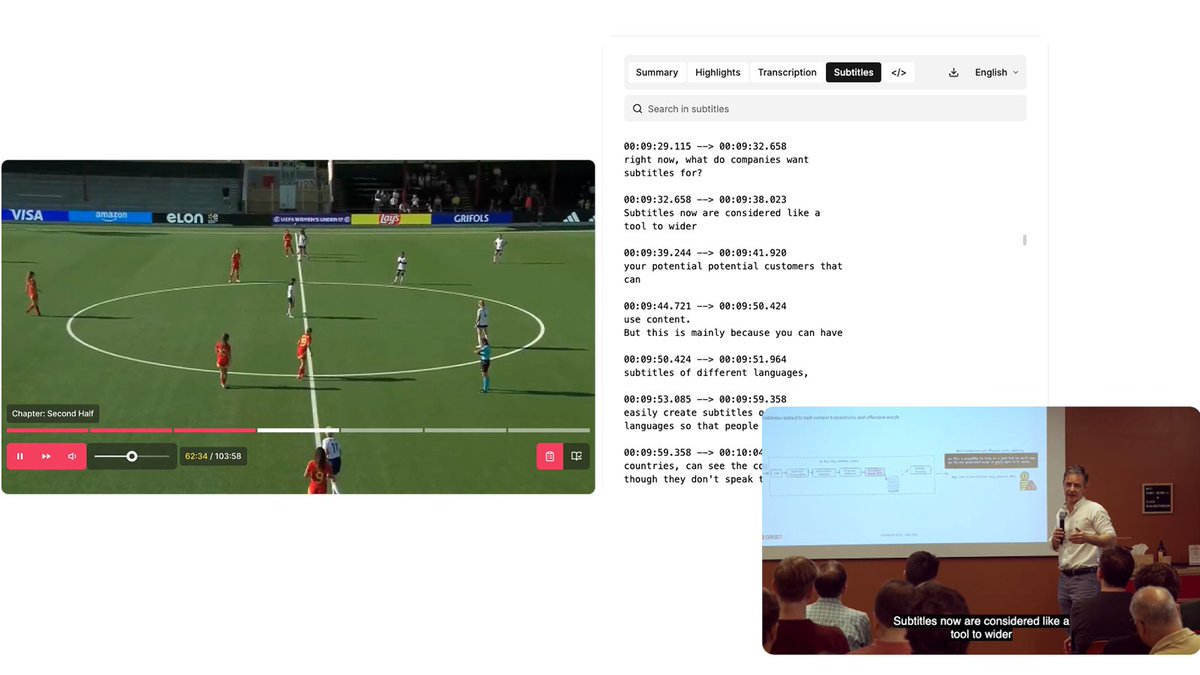
We’ve worked with Cires21 to build MediaCopilot: an AI SaaS platform for broadcasters, OTTs, and digital media, that transforms raw video into enriched content.
Learn a bit more about this new product and our approach to building AI products from scratch –link below.
It's a bit sad and confusing that LLMs ("Large Language Models") have little to do with language; It's just historical. They are highly general purpose technology for statistical modeling of token streams. A better name would be Autoregressive Transformers or something.
They don't care if the tokens happen to represent little text chunks. It could just as well be little image patches, audio chunks, action choices, molecules, or whatever. If you can reduce your problem to that of modeling token streams (for any arbitrary vocabulary of some set of discrete tokens), you can "throw an LLM at it".
Actually, as the LLM stack becomes more and more mature, we may see a convergence of a large number of problems into this modeling paradigm. That is, the problem is fixed at that of "next token prediction" with an LLM, it's just the usage/meaning of the tokens that changes per domain.
If that is the case, it's also possible that deep learning frameworks (e.g. PyTorch and friends) are way too general for what most problems want to look like over time. What's up with thousands of ops and layers that you can reconfigure arbitrarily if 80% of problems just want to use an LLM?
I don't think this is true but I think it's half true.