Excited to share that our paper "Optimistic Task Inference for Behavior Foundation Models" was accepted for ICLR 2026.
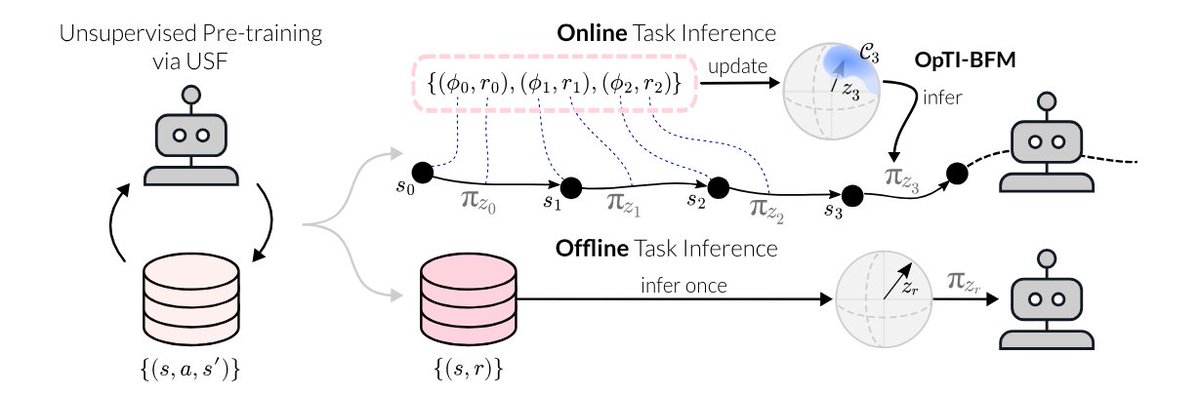
BFMs are great at zero-shot RL, but task inference requires a dataset with reward labels. Our method OpTI-BFM offers an online alternative.
(1/5)
Which representations are meaningful for control?
We're presenting TD-JEPA as an oral at ICLR🇧🇷: a zero-shot reinforcement learning algorithm using self-prediction (JEPA) to learn representations that are predictive of long-term, policy-dependent behavior. It works pretty well!🧵
Excited to share that our paper "Optimistic Task Inference for Behavior Foundation Models" was accepted for ICLR 2026.
BFMs are great at zero-shot RL, but task inference requires a dataset with reward labels. Our method OpTI-BFM offers an online alternative.
(1/5)
OpTI-BFM bares similarities with LinUCB for Bandits which we use to prove sublinear regret in episodic settings under mild assumptions.
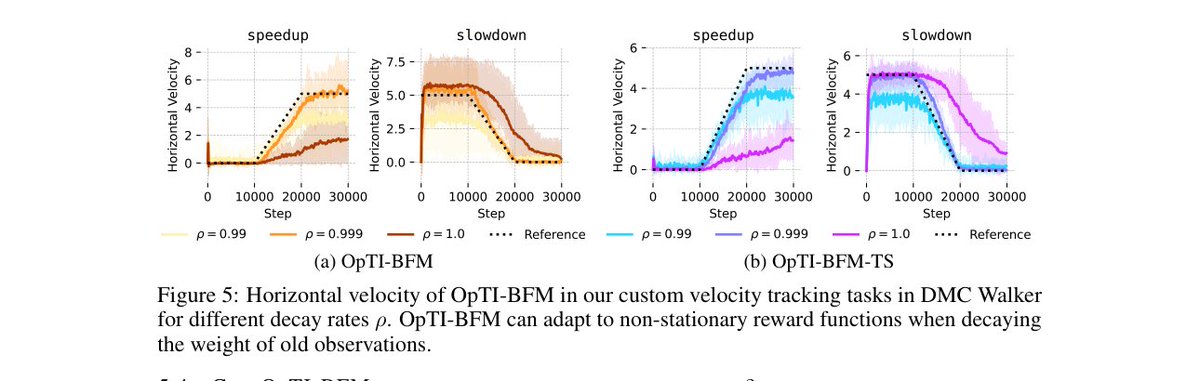
Because it's online, OpTI-BFM can also adapt to time-varying (non-stationary) rewards by decaying the weight on older observations.
(4/5)
Last week I presented our last work: 🐝“Epistemically-guided forward backward exploration (FBEE)”🐝 at the @RL_Conference
TLDR: Active learning for unsupervised RL
When multiple tasks need improvements, fine-tuning a generalist policy becomes tricky. How do we allocate a demonstration budget across a set of tasks of varied difficulty and familiarity?
We are presenting a possible solution at ICML on Wednesday!
(1/3)
If this sounds interesting, come by on Tuesday, 4:30 pm ��� 7:00 pm, West Exhibition Hall B2–B3 #W-618.
Collaborators: @mar_baga, @nicoguertler, @JonasFrey96, @GMartius
https://t.co/Cv4ZP6UYew
(3/3)
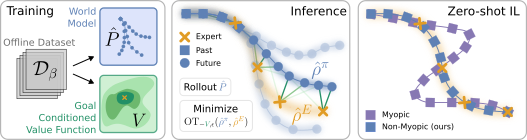
Zero-shot imitation from just a single sparse demonstration is hard. Goal-conditioned methods tend to “greedily" move from one state to the next and lose the big picture.
We're presenting an alternative approach on Tuesday at #ICML2025.
(1/3)
Our method tackles the occupancy matching objective directly at test-time by estimating the agent's occupancy with samples from a learned world model and matching it to the expert occupancy using Optimal Transport.
(2/3)