Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
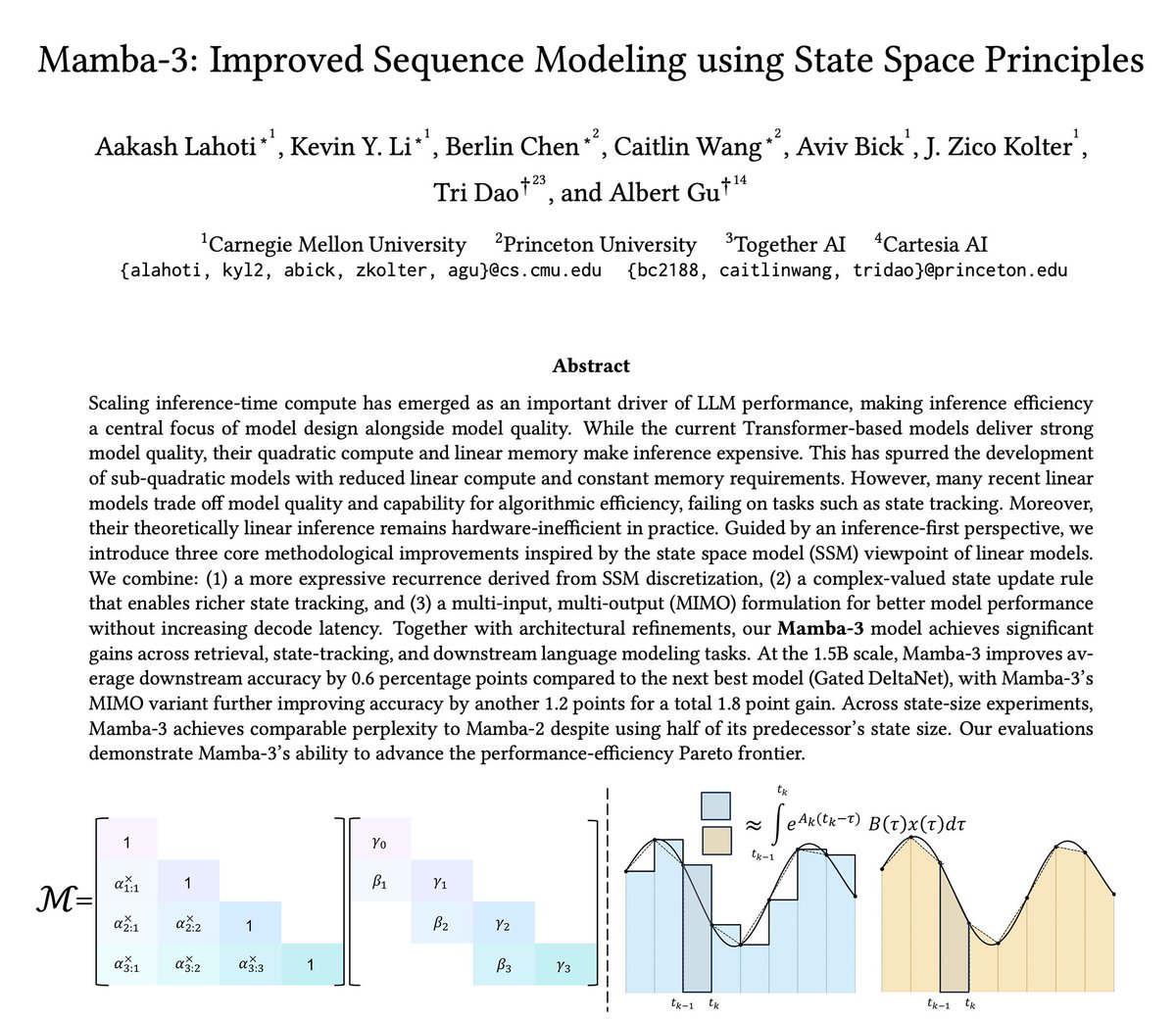
The newest model in the Mamba series is finally here 🐍
Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models.
We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes.
This is the first Mamba that was student led: all credit to @aakash_lahoti@kevinyli_@_berlinchen@caitWW9, and of course @tri_dao!
He did everything right. Loved her, supported her, carried her through the darkest parts of her life. And life still served him the cruelest ending. Loyalty doesn’t always guarantee a happy story. This is why people say relationships are a gamble. You can give someone your youth, your money, your career, your emotional strength… and still lose.
Bro said he kinda mid 😭😭😭 ถามจริง ๆ เอา normal distribution มากาง นายอาร์มตกฝั่งซ้ายจริง ๆ หรอ ออกไปแตะหญ้าบ้างเถอะ ไม่จำเป็นต้อง take L ทุกดราม่าก็ได้นะ 55555555555
AlphaFold by hand✍️ Excel ~ I designed this exercise to show (1) MSA multi-head attention, (2) Pair triangular update, two key components of the EvoFormer architecture.👇Join the AI Math community. Download xlsx.
Meta presents Deconstructing Denoising Diffusion Models for Self-Supervised Learning
paper page: https://t.co/7FURzDfd73
examine the representation learning abilities of Denoising Diffusion Models (DDM) that were originally purposed for image generation. Our philosophy is to deconstruct a DDM, gradually transforming it into a classical Denoising Autoencoder (DAE). This deconstructive procedure allows us to explore how various components of modern DDMs influence self-supervised representation learning. We observe that only a very few modern components are critical for learning good representations, while many others are nonessential. Our study ultimately arrives at an approach that is highly simplified and to a large extent resembles a classical DAE. We hope our study will rekindle interest in a family of classical methods within the realm of modern self-supervised learning.