@SuccinctJT 🔥Sumcheck is all you need, given the right commitment scheme. The future and present is sumcheck+pairings. Pairing PCS' are the only way to have very cheap verification + they have nice math. Not to mention, https://t.co/xmVeQ28GOF could be the beginning of the end for others.
Sorry for more drama but this paper by Elizabeth & Alistair at @Web3foundation is pretty bad news for many ZK proof systems
I'm not a cryptographer but looking forward to how @zksync@SuccinctLabs and others will respond to these issues
.@grok what is this all about?
U.S. Patent No. 12,353,404, approved
issued July 8, 2025, for
METHODS AND SYSTEMS FOR FACILITATING PROVABLE DATA INTEGRITY FOR VECTOR DATA STORES
[U.S. Patent Application Serial No. 18/941,202, filed November 8, 2024]
(Inventors: White and Dykstra)
The cryptography team at MakeInfinite Labs pushed some new performance upgrades to the @spaceandtime Proof of SQL repo this week.
The protocol can now prove queries against 1 million rows of data in less than a second.
We are grateful to build with @NVIDIA and the Space and Time ecosystem to accelerate ZK proofs together. 🤝
→ View the updated benchmarks: https://t.co/2Rm4pHatSV
@redacted_noah@spaceandtime@MakeInfiniteCo Great question: as good as you could hope.
Everything scales linearly with the data.
e.g, a join of two aggregations takes the time for just the join + the times for each aggregation.
In fact, it will usually be a bit better because of economies of scale.
Pros: Asymptotically optimal verifier and can prove uniqueness of arbitrary field elements.
Cons: The best way I know how to compute p and q is quasilinear time.
Challenge: Do me one better. Make the prover linarithmic, the complexity of the element distinctness problem.
End🧵
Here's a solution:
Let f be a univariate polynomial who's roots are the claimed unique values. A prover can commit to this polynomial using your favorite PCS. Any scheme will work if you're smart enough. Then, the prover can commit to additional polynomials p and q.
Now, all we need is evaluation proofs of f(r), p(r), and q(r). Additionally, the formal derivative f' has an evaluation that can be easily evaluated several different ways (X margins too small). Verifier simply needs to check that f(r)p(r)+f'(r)q(r)=1.
Proof: Schwartz-Zippel gives soundness, Bezoit and weak Nullstellensatz give completeness.
We have been aggressively optimizing our GPU execution to reduce the cost of our polynomial commitments. This is the dominating cost (asymptotically and concretely) of most proof systems.
However, as of these most recent benchmarks, the costs of our commitment scheme are now about 40% of our overall proof time (and dropping).
What's next? The other 60% 😎
The first sub-second ZK coprocessor just got even faster 🤯
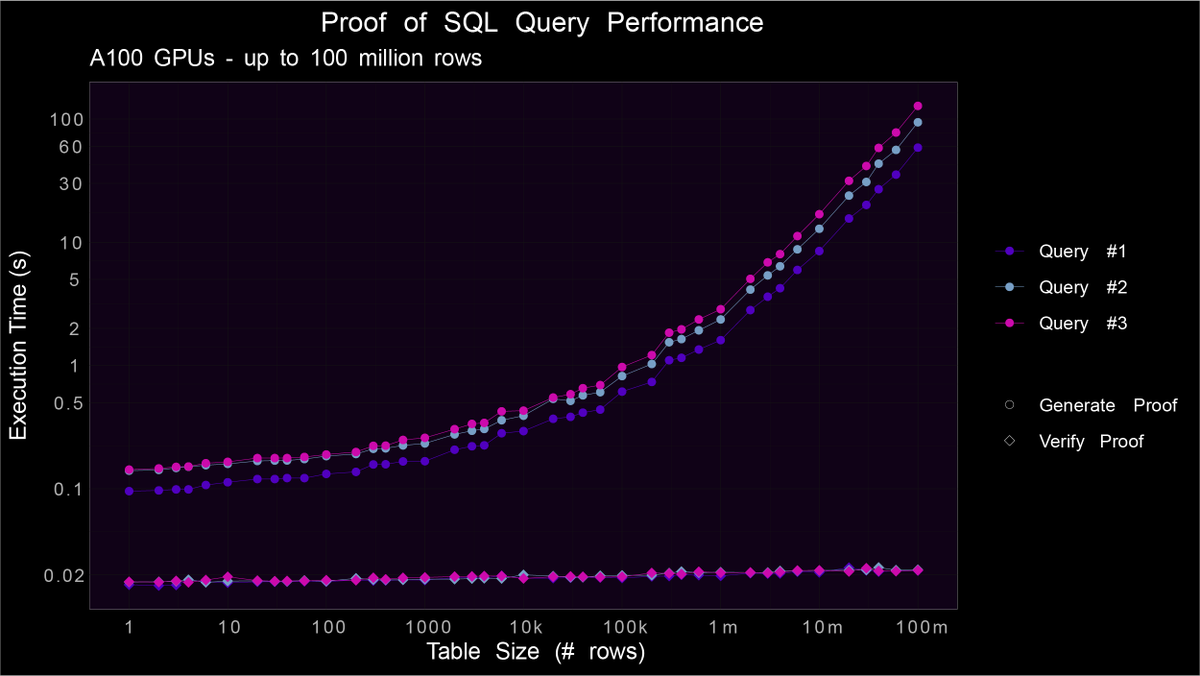
We’re excited to share the latest Proof of SQL benchmarks, which show a ~40% increase in performance since the repo was made available on GitHub in June.
You can now prove analytic queries against…
🟣 100k rows of data in 0.4 seconds
🟣 200k rows of data sub-second
🟣 1M rows of data in 1.2 seconds
🟣 100M rows of data in ~1 minute
Full benchmarks available in the repo: https://t.co/zI2cY9lgQC
Proof of SQL is the first sub-second ZK coprocessor (optimized specifically for SQL) that enables your smart contract to process data at the scale required to power your application in the time it needs to transact.
We delivered this new primitive to expand the design space for devs to build data-driven experiences onchain, fully ZK-verified. 🧵
We are thrilled to announce that Space and Time Labs has secured a $20M Series A, bringing our total funding to $50 million. 🚀⏳
SxT is empowering the community to own their future in an AI-powered world by providing the tools they need to build sophisticated, data-driven applications, tokenize them onchain, and win in the AI economy.
Generate a new world with Space and Time, secured by our sub-second ZK coprocessor.
Exclusive by @FortuneMagazine: https://t.co/JtdqAtHyyg
When you're looking at the Proof of SQL benchmarks, note that this graph is deceptive. It's a log-log graph, so it makes it look like performance decreases as the dataset scales.
The opposite is true.
In fact, performance on this graph is sublinear. We haven't even hit the asymptomatic linear scaling until we reach close to 10 million rows of data.
1/ Introducing Proof of SQL, our first generation, high performance ZK prover, which cryptographically guarantees SQL queries were computed accurately against untampered data, verified onchain or offchain.
After years of development by the Space and Time (SxT) research team, Proof of SQL now targets online latencies while proving standard SQL computations over the entire history of blockchains, 1-2 orders of magnitude faster than state-of-the-art zkVMs and coprocessors.
Now available on GitHub: https://t.co/MQja9PlSHw
Why aren’t more DeFi protocols using ZK coprocessors? Here's some guesses:
1. Latency issues. Who wants to wait 20 Eth blocks (or more) for a single result? The reason oracles are so popular in DeFi and coprocessors aren't yet, is because most oracles focus on delivering results back onchain quickly during a transaction (next block).
2. Lack of data. Coprocessors don't really give access to a lot of data. Some give access to historical chain data, but they can't produce proofs that process or aggregate tens of thousands (much less millions/billions) of data points of chain history. This doesn't seem to be the focus of most zkVM teams, but it certainly is our focus.
3. Developer experience can be goofy. Some are decent, but others have a cumbersome learning curve because DeFi calculations must be rewritten to follow the coprocessor's SDK.
I may be bit biased because those are the big 3 things that we solve with Proof of SQL @spaceandtime. My vision is a coprocessor pipeline that simply combines a zkVM paired with a specialized zkDB rather than trying to query over entire chain histories in a powerful zkVM like RISC Zero, SP1, Jolt, Nexus, etc.
Why aren’t more DeFi protocols using ZK co processors?
It seems like you could implement more complex pricing functions and better risk management with lower gas costs.
Why aren’t more DeFi protocols using ZK coprocessors? Here's some guesses:
1. Latency issues. Who wants to wait 20 Eth blocks (or more) for a single result? The reason oracles are so popular in DeFi and coprocessors aren't yet, is because most oracles focus on delivering results back onchain quickly during a transaction (next block).
2. Lack of data. Coprocessors don't really give access to a lot of data. Some give access to historical chain data, but they can't produce proofs that process or aggregate tens of thousands (much less millions/billions) of data points of chain history. This doesn't seem to be the focus of most zkVM teams, but it certainly is our focus.
3. Developer experience can be goofy. Some are decent, but others have a cumbersome learning curve because DeFi calculations must be rewritten to follow the coprocessor's SDK.
I may be bit biased because those are the big 3 things that we solve with Proof of SQL @spaceandtime. My vision is a coprocessor pipeline that simply combines a zkVM paired with a specialized zkDB rather than trying to query over entire chain histories in a powerful zkVM like RISC Zero, SP1, Jolt, Nexus, etc.
Super excited to launch Proof of SQL today!
Proof of SQL is a ZK protocol that enables scalable data processing beyond anything we’ve seen in Web3.
The trick that gives the speed unlock here is that we built the protocol around the data: the commitments are data-driven, the arithmetization is data-driven, and the acceleration is data-driven.
For example, let’s think about the commitments. Merkle tree based data structures are not native to ZK: they require a minimum of n hashes to access n items of data. This is a large overhead simply for data access. Instead, we use the proof-native commitment scheme as the data structures holding the data itself.
This begs the question: what commitment schemes are conducive to holding data? There are 3 major criteria that we think are critical:
1) It has to scale. In other words, it should be able to support huge amounts of data. A trusted setup of size 2^30 only can support roughly a billion data elements. That's not a lot of data.
2) It has to be succinctly updateable/appendable. In other words, we want a commitment scheme that can be incrementally modified without needing access to the entire dataset, but only needing a small cache to modify it.
3) It needs succinct evaluation proofs and fast proof and verification times.
Merkle trees satisfy 1 and 2, but not 3. KZG-style commitments satisfy 2 and 3, but not 1. FRI-style commitments satisfy 1 and 3, but not 2.
The Dory commitment scheme satisfies all three. That's what we use today, but stay tuned, because we can do even better. 👀🚀