The crypto market structure bill has PASSED the Senate Banking Committee with a bi-partisan vote!
Historic day for crypto and for the future of digital assets in America. Grateful for the countless hours from lawmakers and staff to strengthen this legislation. Big improvement from where we were in January on rewards, tokenization, DeFi, and CFTC authority. I'm proud we stood up for our customers in that moment, and the bill is better because of it.
Looking forward to a bipartisan law that cements the US as the world's crypto capital. Let's get CLARITY done.
The thesis is simple: the future belongs to individuals who build compounding AI systems, not to individuals who use corporate-owned centralized AI tools.
I'm trying to build these in open source so you can have them for free. That's what GBrain is.
The confounding factor is that virtually every big company is overstaffed by 2-4x and has been for decades. AI is the catalyst/excuse to finally fix that. Of course nobody wants to say this out loud.
Alyssa Liu went viral during the Met Gala for her rant on the state of the public perception of data centers.
"We are being manipulated into ceding the compute frontier. Data center development is vital to national security." She adds, "Karen Hao's overstimation of data center water consumption by a factor of 1000 has done irreparable damage to the nation's efforts to stay ahead."
A 16-year-old cut Claude's output tokens by 75%.
The trick: make it talk like a caveman. Less "I'd be happy to help," more "done."
I tested it. Instructions change how Claude talks, not how it thinks.
Example prompt:
"Me talk short. No explain. Tool first. Result first. Me stop. No filler. No polite. Just do."
My dear front-end developers (and anyone who’s interested in the future of interfaces):
I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept):
Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow
🇨🇳 In China, they are rolling out robotic electricians on a massive scale.
They install and inspects live high-voltage, high altitudes electrical wires, and keep the grid running safely.
i.e. humans no longer have to do this dangerous manual labor.
Finally, a version of Openclaw I can trust. Best part is porting it to mobile via Dispatch. While everyone is doomscrolling, you can nerd out and be automating your boring tasks from bed.
You can now enable Claude to use your computer to complete tasks.
It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk.
Research preview in Claude Cowork and Claude Code, macOS only.
For agentic systems founders and dev tools founders:
People do not want to pay for raw markdown and they shouldn't have to.
But they may pay for orchestration, hosting, updates, collaboration, portability, analytics, and managed execution.
These can be great businesses.
for a while i've had a slight fear that the bluetooth from my airpods could be frying my brain
this weekend i pulled the raw data from a $30m government study of 1,679 mice blasted with cell phone radiation and reanalyzed it
what i found was...not what I expected?
🧵
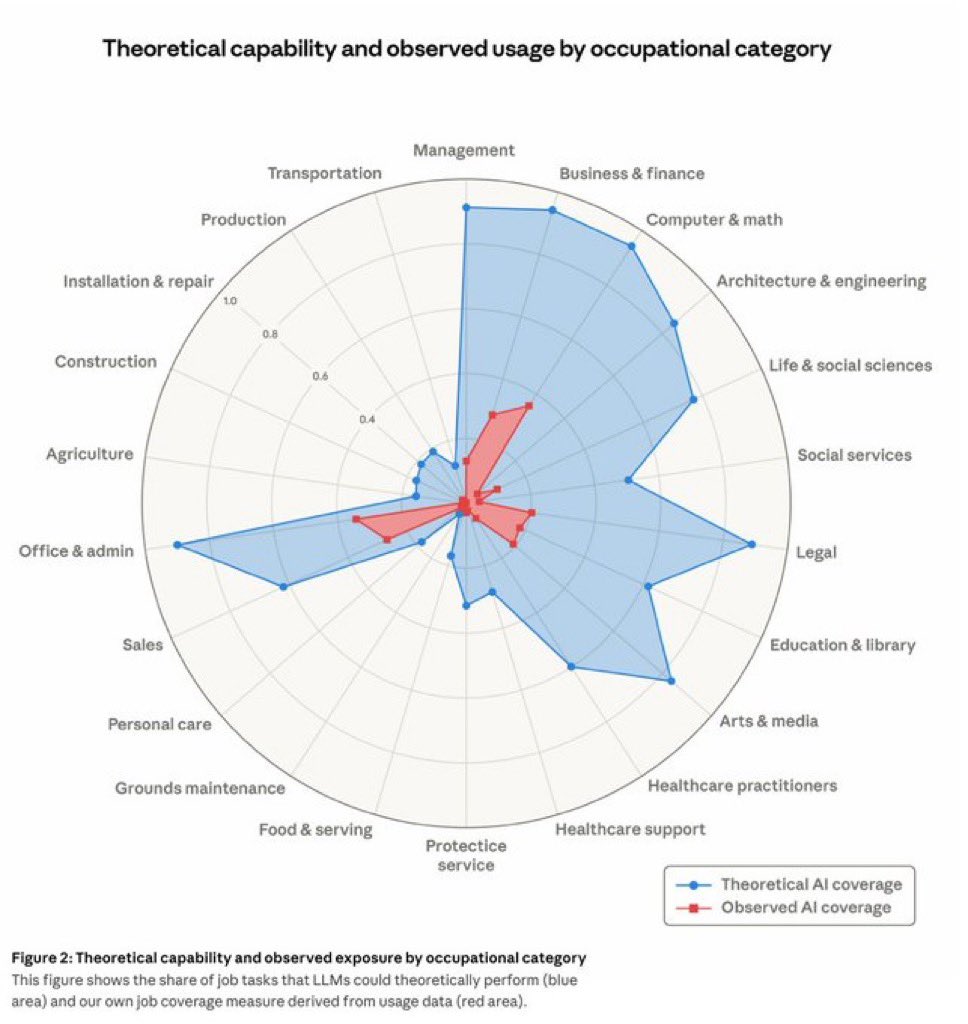
Anthropic just released the most IMPORTANT chart in the AI labor debate.
This comes from the company that builds Claude using data from 2 million real conversations.
Here’s what it shows.
The blue area is every task AI could theoretically do right now.
The red area is what people are actually using it for.
The gap between them is enormous and that gap is your career runway.
Computer programmers are already 75%
covered.
Customer service reps, data entry workers, financial analysts, they’re next.
But here’s what no one is talking about.
The mass layoffs haven’t really started.
Unemployment for exposed workers hasn’t budged.
So what’s actually happening?
Companies are closing the front door, hiring for workers aged 22 to 25 in AI exposed jobs has dropped 14%.
The most exposed workers aren’t factory workers, they’re college educated, higher earning.
49% of US jobs now have at least a quarter of their tasks inside AI’s reach.
That’s up from 36% just one year ago.
And the red area on that chart,
the real world usage is still a fraction of what’s possible.
Every month, it grows a bit.
Anthropic built the scoreboard and most people haven’t looked at it yet.
This chart is quietly showing you the new playbook for AI coding companies and nobody is talking about it.
Cognition and Cursor both started as wrappers running on Claude and GPT. Now look at this benchmark. Cognition’s SWE-1.6 at 51.7%. Cursor’s Composer-1.5 at 50.8%. Both sitting within striking distance of Claude Opus 4.6 at 53.6% and GPT-5.3-Codex at 56.8%.
Neither company trained a foundation model from scratch. Both took open-source base models and applied reinforcement learning in real coding environments. Cognition’s Swyx said it directly on Hacker News: “it’s increasingly less important the qualities of the base model as long as it’s good enough, because then the RL and post-training takes over and is the entire point of differentiation.”
That’s the thesis. The base model is a commodity. The RL pipeline trained on your specific agent harness, your tool use patterns, your real user sessions is the defensible layer. Cognition trained SWE-1.6 on their Cascade harness with two orders of magnitude more RL compute than SWE-1.5. Cursor trained Composer inside live IDE environments with file editing, semantic search, and terminal commands. Both co-designed the model and the product together.
The math on the jump tells the story. SWE-1.5 scored 40.1%. SWE-1.6 scores 51.7%. Same base model. Same 950 tok/s inference on Cerebras. The entire 11.6 point improvement came from better RL recipes and more compute. That’s a faster rate of improvement than most foundation labs are getting from pre-training scaling.
This is two $10B+ companies (Cognition at $10.2B, Cursor at $29.3B) independently converging on the same conclusion: you don’t need to build GPT-5 to compete with GPT-5 on coding. You need RL at scale on top of a good enough base, co-designed with your agent infrastructure.
The speed layer matters too. Cognition runs at 950 tok/s through Cerebras. Composer runs at 250 tok/s. In agentic workflows where the model loops dozens of times per task, that 4x speed gap compounds into meaningfully different user experiences. Cognition is betting speed plus accuracy beats accuracy alone.
The question that should worry OpenAI and Anthropic: if two startups can get within 5 points of your best models using RL on open-source bases, what happens when the open-source bases get better? Every improvement to Llama or Qwen flows directly into Cognition and Cursor’s pipeline. The foundation labs are essentially subsidizing their own competition.