New work: SurGe
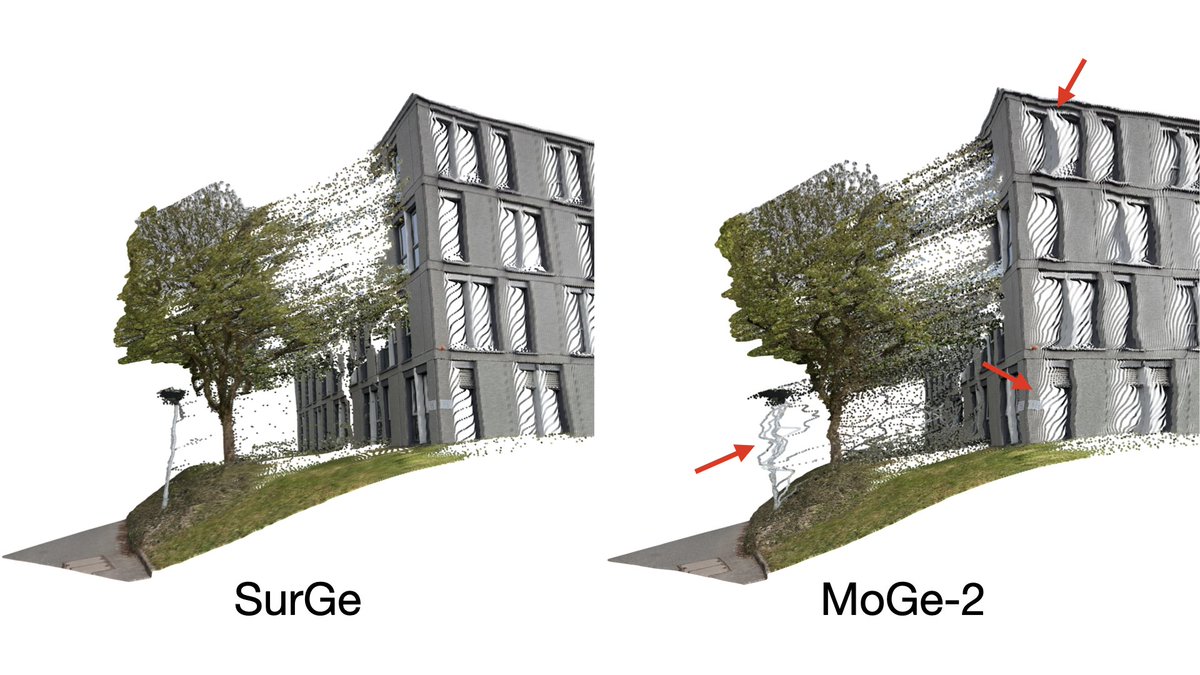
We improve local accuracy in feedforward 3D reconstruction. Current point map models struggle with bending and oscillating artifacts for thin structures (chair legs, street lamps, etc). Easy to spot visually, but not well captured by pointwise metrics like AbsRel.
I'll be presenting "DINO in the Room (DITR)", the winning method of the ScanNet++ 3D semantic segmentation challenge, tomorrow at CVPR at 10 a.m. in Room 211.
Project page: https://t.co/H5HdnAU3b6
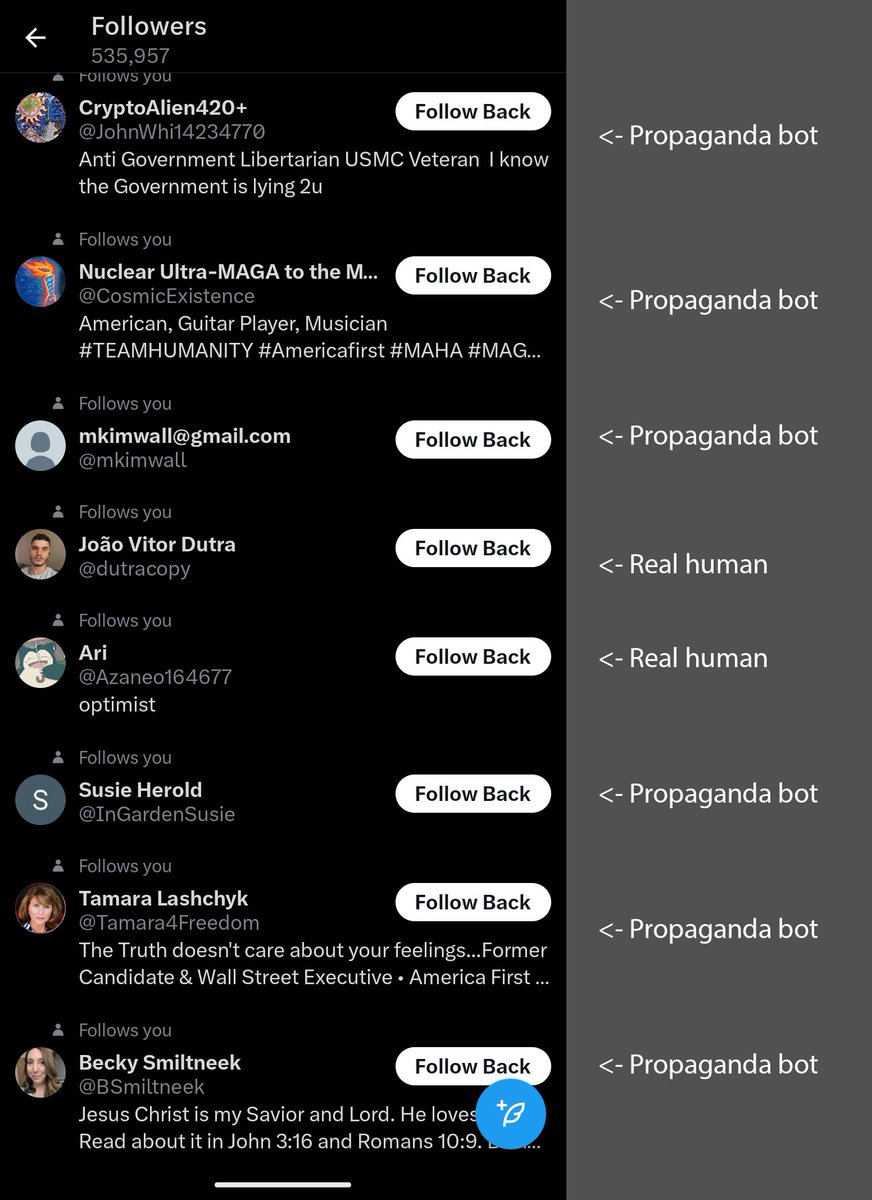
On any given day I gain hundreds of followers. About 6-8 out of 10 of these followers are bots. The large majority are political propaganda bots, with a minority being related to crypto pump & dump scams
I don't think people realize the scale of the phenomenon. Today the large majority of Twitter activity and Twitter accounts are bots.
I'll present #NLF, our SOTA 3D human pose and shape estimator at #NeurIPS2024 today: poster at East Exhibit Hall A-C #1304 from 11:00!
Project: https://t.co/TB1Vgt0ryn
Models out for both PyTorch and TF! https://t.co/TnQXuY8VOL
Further details to come soon!
Time to give credit to this paper -- it gets it right! Kudos to the authors. The fix is a proper way to speed up the original Marigold. If you’re not aiming for an end-to-end network from Stable Diffusion, just add one flag to the DDIM scheduler for instant depth predictions in one diffusion step. We’ll release a one-liner fix in the original repo and diffusers soon, along with more features; stay tuned for updates!
Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think
discuss: https://t.co/MNXBZTMK4d
Recent work showed that large diffusion models can be reused as highly precise monocular depth estimators by casting depth estimation as an image-conditional image generation task. While the proposed model achieved state-of-the-art results, high computational demands due to multi-step inference limited its use in many scenarios. In this paper, we show that the perceived inefficiency was caused by a flaw in the inference pipeline that has so far gone unnoticed. The fixed model performs comparably to the best previously reported configuration while being more than 200times faster. To optimize for downstream task performance, we perform end-to-end fine-tuning on top of the single-step model with task-specific losses and get a deterministic model that outperforms all other diffusion-based depth and normal estimation models on common zero-shot benchmarks. We surprisingly find that this fine-tuning protocol also works directly on Stable Diffusion and achieves comparable performance to current state-of-the-art diffusion-based depth and normal estimation models, calling into question some of the conclusions drawn from prior works.
Check out our work on fine-tuning of image-conditional diffusion models for depth and normal estimation.
Widely used diffusion models can be improved with single-step inference and task-specific fine-tuning, allowing us to gain better accuracy while being 200x faster!⚡
🧵(1/6)