Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
Do you realize what this means?
Karpathy just released the great equalizer
Now ANYONE can become their own AI lab
If all you own is one GPU, you can automate it so it builds its own model and continuously improves it
You become a 1 man OpenAI
Just bought a 2nd DGX Spark so I can run double the experiments at once
For those unaware of how this works:
With Karpathy’s autoresearch project your GPU stays up all night running experiments on itself
Playing around with an open weights model
Implements experiments that improves the model
Throws away experiments that hurt the model
Continuously self improving AI. In your home. On your desk.
Maybe the biggest release in the last several years
It is so painfully obvious where this world is going
Those with their own hardware will have all the power. Self improving super intelligence
Those with no hardware will rent whatever the corporate labs decide to lease to them at the moment
Own. Your. Intelligence.
It's all speeding up
We're getting numb to AI hype
But the models just got noticeably more powerful within the past couple of weeks.
the stuff I'm one-shotting right now is unbelievable compared to a year ago... compared to a few months ago.
everyone has access to incredible powers now
you, me, and the village idiot who wants to cause max chaos
life on the exponential curve
I once again implore you to do that thing you always wanted to do
while the world still looks familiar
while you still can
nobody is certain where this is headed. nobody
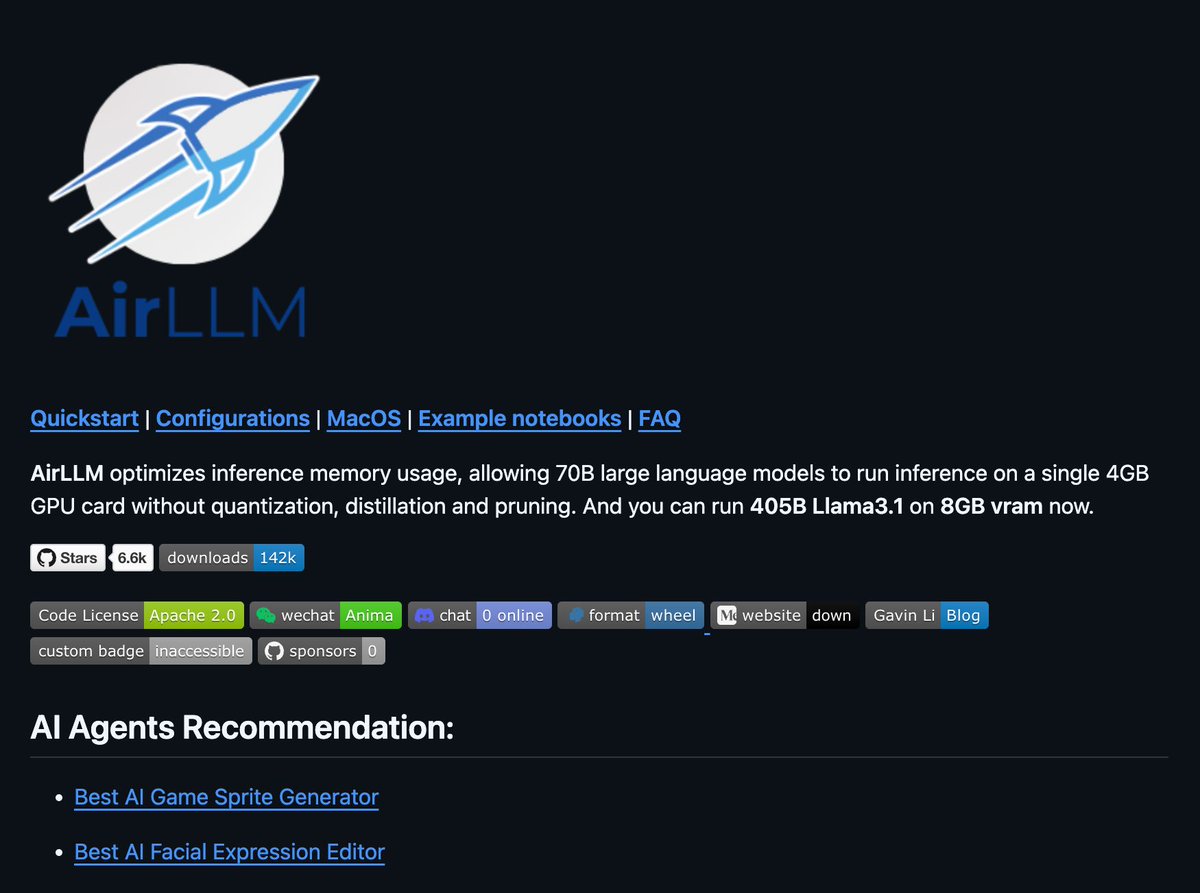
You can now run 70B LLMs on a 4GB GPU.
AirLLM just made massive models usable on low-memory hardware.
𝗪𝗵𝗮𝘁 𝗷𝘂𝘀𝘁 𝗵𝗮𝗽𝗽𝗲𝗻𝗲𝗱
AirLLM released memory-optimized inference for large language models.
It runs 70B models on 4GB VRAM.
It can even run 405B Llama 3.1 on 8GB VRAM.
𝗛𝗼𝘄 𝗶𝘁 𝘄𝗼𝗿𝗸𝘀
AirLLM loads models one layer at a time.
Instead of loading everything:
→ Load a layer
→ Run computation
→ Free memory
→ Load the next layer
This keeps GPU memory usage extremely low.
𝗞𝗲𝘆 𝗱𝗲𝘁𝗮𝗶𝗹𝘀
• No quantization required by default
• Optional 4-bit or 8-bit weight compression
• Same API as Hugging Face Transformers
• Supports CPU and GPU inference
• Works on Linux and macOS Apple Silicon
𝗪𝗵𝗮𝘁 𝘆𝗼𝘂 𝗰𝗮𝗻 𝗱𝗼
• Run Llama, Qwen, Mistral, Mixtral locally
• Test large models without cloud GPUs
• Prototype agents on cheap hardware
We’re releasing TranslateGemma, a new family of open translation models with support for 55 languages. 🌐
Available in 4B, 12B, and 27B parameter sizes – they’re designed for efficiency without sacrificing quality.
We are thrilled to introduce Qwen3-Next! 🚀 A cutting-edge model architecture designed for long-context understanding, large-scale capabilities, and unparalleled efficiency. With hybrid attention mechanism and sparse MoE architecture, it sets new standards in performance and computational cost.
You DO NOT want to miss this - All the tricks and optimisations used to make gpt-oss blazingly fast, all of it - in a blogpost (with benchmarks)! 🔥
We cover details ranging from MXFP4 quantisation to, pre-built kernels, Tensor/ Expert Parallelism, Continuous Batching and much more
Bonus: We add extensive benchmarks (along with reproducible scripts)! ⚡
As AI reduces the creative process to 0, the secret weapon that will help creators is letting fans share in their creative upside. To co-own it together.
Attention & money are merging online. Tokenizing the connection between creators↔️fans will be the last thing of value left.
Introducing checkpoint-engine: our open-source, lightweight middleware for efficient, in-place weight updates in LLM inference engines, especially effective for RL.
✅ Update a 1T model on thousands of GPUs in ~20s
✅ Supports both broadcast (sync) & P2P (dynamic) updates
✅ Optimized pipeline with overlapped communication and copy
✅ Lightweight & flexible for large-scale deployment
Check out our work on GitHub: https://t.co/L4c1oUAB6p
Can a 1-bit or 3-bit quantized model outperform GPT-4.1 or Claude-Opus-4?
Yes!
Today, we're excited to show how LLMs like DeepSeek-V3.1 can be quantized to just 1-bit or 3-bit, and still beat SOTA models like Claude-Opus-4 (thinking) on Aider Polyglot.
Details and blog below!
You can now run @xAI Grok 2.5 locally on just 120GB RAM! 🚀
The 270B parameter model runs ~5 t/s on a 128GB Mac with our Dynamic 3-bit GGUF.
We shrunk the 539GB model to 118GB (-80%) & left key layers in higher 8-bits
Guide: https://t.co/HXF9MrRTiA
GGUF: https://t.co/hEnTppkMFs