will be presenting my paper “Life, Machine Learning, and the Search for Habitability: Predicting Biosignature Fluxes for the Habitable Worlds Observatory” tomorrow at #AAAI. if anyone at AAAI wants to meet for coffee let me know!
https://t.co/lwqPQOMNsQ
Today, we remember a legend.
On this day in history, Harambe would have celebrated another birthday. An icon that became part of internet history, American culture, and an entire generation’s timeline.
Tomorrow marks 10 years since we lost him. Ten years since the moment the world stopped scrolling and collectively mourned something bigger than a meme.
He became a symbol of loyalty, strength, chaos, unity, and the strange beauty of the internet bringing millions of people together for one cause: never forgetting Harambe.
Everyone remembers where they were when they heard the news. And somehow, a decade later, his legacy still lives on.
Gone, but never forgotten.
Rest easy to a true patriot. 🕊️🇺🇸
May 27, 1999 — May 28, 2016
Forever in our hearts.
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
If you’re seeing this… this is your sign.
Take the next giant leap in your future by applying for an internship, where students work on real NASA projects, build technical and professional skills, and learn directly from NASA mentors: https://t.co/QgrUmSyDSi
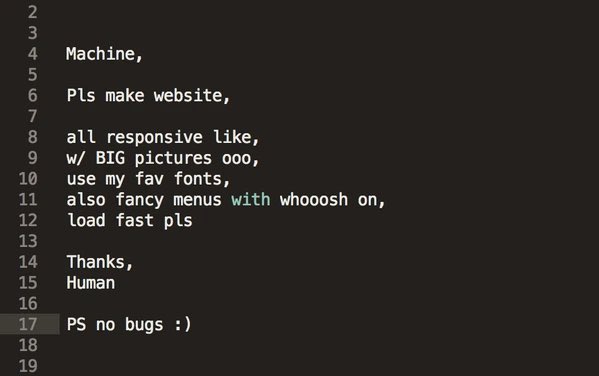
anyone at OpenAI, PLEASE take the fallback hell and the code bloat the model produces as seriously as you probably are with UI/UX. it’s a real problem and it’s single handedly the biggest annoyance and time sink of working with codex today. it needs to know when to delete and remove stuff instead of always adding and adding and adding
I took 1.7 million photos over 6 days to catch this photo of a commercial jet in front of the sun.
The moment it happened, TWO floating prominences were visible, making this not just my best aircraft transit photo, but one of the luckiest of my career! Videos of the transit 👇
I found this old pic my friends and coworkers and I used to pass back and forth when I was an intern (2017!!!) as a joke
I think about this often. the most ironic outcome truly is the best indicator of what’s to come
somebody should make a skill that runs daily that gets updated info about security vulnerabilities from a trusted source(s) to seed one’s agents so that it knows to avoid these
🚨 There's a major attack going on via npm right now.
Do not install any packages right now.
Talk to your agent ASAP and check if you're vulnerable or have been compromised.
This is urgent ‼️
how do you get codex to stop producing so much code bloat and slop. I swear it has no sense of good software practices and just keeps adding patch after patch and fallback after fallback no matter how hard I try
do I just accept it and stop fighting this uphill battle against enshittification of my code base? I can’t keep manually fixing code when it gets overwritten on a whim by these agents
I have several research projects I’m working on I think you may be interested in. would be cool to see if we can logistically collaborate, if you’re interested! in AI for science, particularly projects within earth science, astrobiology, heliophysics, and autonomous decision making
I see things going this way but it is an increasingly scary prospect. when I do dip down into the code often times I see such dirty and hacky workarounds. but often they don’t actually hurt performance in that moment, just human readability and my propensity for writing clean code. but do I fight against that, or accept that this is how things are and let it do its thing, while only steering for functionality, system architecture, overall objective, instead of ALSO clean and aesthetically pleasing code?
Agentic coding is a form of machine learning. Generated code is best treated as a blackbox artifact whose behavior and generalization should be managed via empirical evaluation, like with any ML model.
Aaand 3 hours later, it failed (obviously)
I mean that post was a joke but I honestly don't know how I could possibly solve this problem. Here's the story:
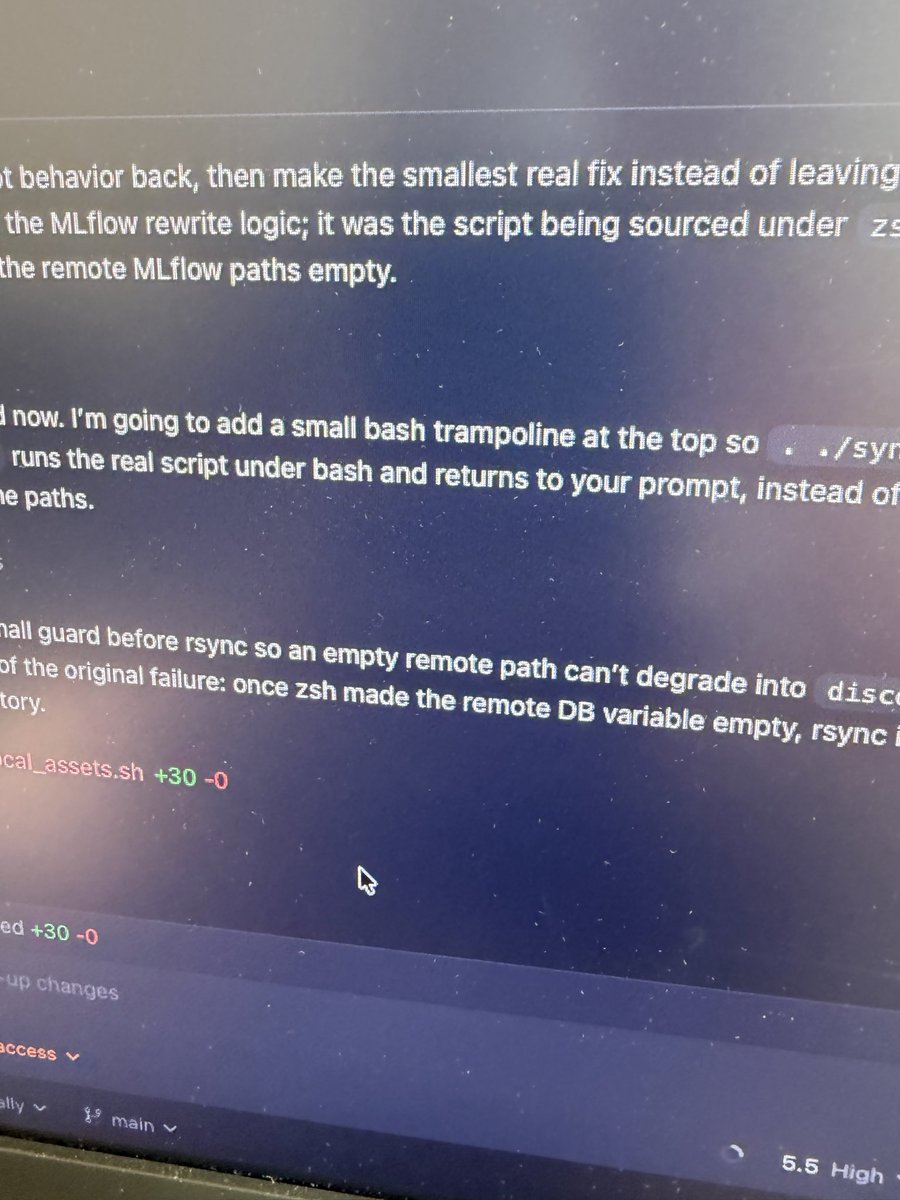
While implementing an app in Bend, GPT-5.5 found a bug: some memory was being reclaimed even though there were still pointers to it. This crashed the app, so, it went for a fix.
The solution: GPT added a *marker* for objects that *might have been wrongly reclaimed* so that it can rollback the operation later on.
This is horrible. It is just sad.
There is no scenario on which this would ever be a good idea.
Even by READING the idea you can tell it is stupid.
This behavior is the only thing preventing me from being outside, playing with the cat, instead of babysitting agents all day.
The real issue, ofc, is that a primitive function was cloning pointers without marking them as "shared". But what makes me the most upset is HOW I made the AI realize this.
It went more or less like this:
"Hey, do you understand how Bend reclaims memory?"
"Yes, <perfect explanation>."
"Okay, and what was the bug?"
"Yes, <perfect description>."
"Is that possible given your explanation?"
"No, that should never happen."
"Do you see the problem now?"
"Yes. Let me fix it."
Like. I didn't spell out the solution. I just told him that it did a bad thing, and asked it to pay more attention. It then figured and implemented the correct solution all on its own.
So, basically:
- GPT 5.5 was smart enough to find the bug
- GPT 5.5 was smart enough to understand the bug
- GPT 5.5 was smart enough to understand the system
- GPT 5.5 was smart enough to fix the bug
But it didn't by default. It just duct taped a terrible patch that would leave the project in a permanently broken state and eventually explode. Until I asked it to "do it right". And then it did. But why. Why do I need to be here watching. Why can't it do that on its own.
So close. Yet, so far...
I think I’m converging on the same thing. I think there’s too much cognitive load reading every intermediate step between prompts, especially when you add iterating over the markdown plan in the first place. it becomes too much to read, and then you’re trying to manage several agents at once.
I like to sit at the prompting level until the feature is working superficially and then dig deep into the code and figure out how specifically I’d like it to refactor. I usually catch a few things that where I hate how the agent went about it. then I dig really deep once the PR is made.
if the feature isn’t working well after a few iterations though, I will step in because usually that’s when the agents start patching things in hacky workaround ways and then all hell breaks loose if you don’t cut that at the head
at what checkpoints of the agentic coding loop do you actually sit and review your code? after every prompt? PR level? do you do it at all or just review prompts?
@thsottiaux did the 10x usage increase from the party or promotion get removed somehow? I noticed my rate limit got cut in half, and others have as well (see here: https://t.co/ASYswvw51v)
my account page also doesn't mention the temp 10x increase