catchy headline: 17470 token transfers per second achieved on testnet. better read on anon.
In january I took the time to do a deep dive on writing efficient solana programs. To put it into practice, I wrote a token program that is zerocopy and no_alloc from end to end. It’s quite optimized and supports batch invocations, memoizes several verifications across instructions within a batch, etc, etc.
It does a transfer in ≈271 cus, and a batched 2x transfer (common DeFi workflow) in ≈463 cus and saves an invocation – a 10x improvement over tokenkeg at 4500-4900 cus per invocation (and more for TransferChecked). Short of handwriting bpf, it’s probably close to as good as you can get with better readability and maintainability; there’s definitely not another 10x improvement to be made. Using this standard may bring token CU usage from ≈8-10% of blockspace to 1-2% of blockspace.
It supports transmutation to and from tokenkeg – i.e. can “bridge” to and from this standard. i’m thinking it’d serve well until we get runtime v2 and a fd token program which may be a year or two away. Curious to get thoughts from community on a complementary standard.
Pairs well with a 1.18 vintage scheduler (cc @apfitzge). These transactions will be insanely prioritized over many other transactions due to the low resource requests.
After many many weeks of waiting, got access to a testnet RPC today. Here are some of the results. The program is GigabithNd6HmU4nRFPHXAkBK9nAtvNuHnSavWi3G7Zj.
Here’s a testnet block with 2120 transactions (batched 2x transfer) between the same two accounts:
https://t.co/SYIwwGlSzW
(somewhat unfairly) extrapolating here with 400ms block times, that's 5300 TPS, or 10600 transfers per second
Here’s a testnet block with 3494 transactions (batched 2x transfer) between only four pairs of accounts.
https://t.co/J5RSwBfHdl
(somewhat unfairly) extrapolating here with 400ms block times, that's 8735 TPS, or 17470 transfers per second
These tests were by no means hitting any limits (the only limit maybe being hit here was the 10 mb/s upload I have at home haha). These blocks are not full; this last one used 29m/48m cus.
The efficiency of onchain programs are due for an overhaul.
Is anybody using VR/AR glasses for coding? I once tried the @XREAL_Global Air for a few minutes and I really liked it but maybe I'm missing some obvious choice(?)
@LinusEkenstam I think it is important to consider that there are safety regulations in place especially in a major market like the EU that prevent arbitrary car designs.
https://t.co/jCZx0YK7Ix
I secure Postgres tables usually via RLS, but I noticed those get quickly nested with multiple tables.
A good way for me to keep the policies transparent has been to refactor common checks into separate functions.
Here an example using @supabase
Claude-2 looks super interesting! In terms of benchmarks its not far off from GPT-4, has a huge context window and cheaper prices.
@AnthropicAI can you give an estimated timeline on a release date for Singapore?
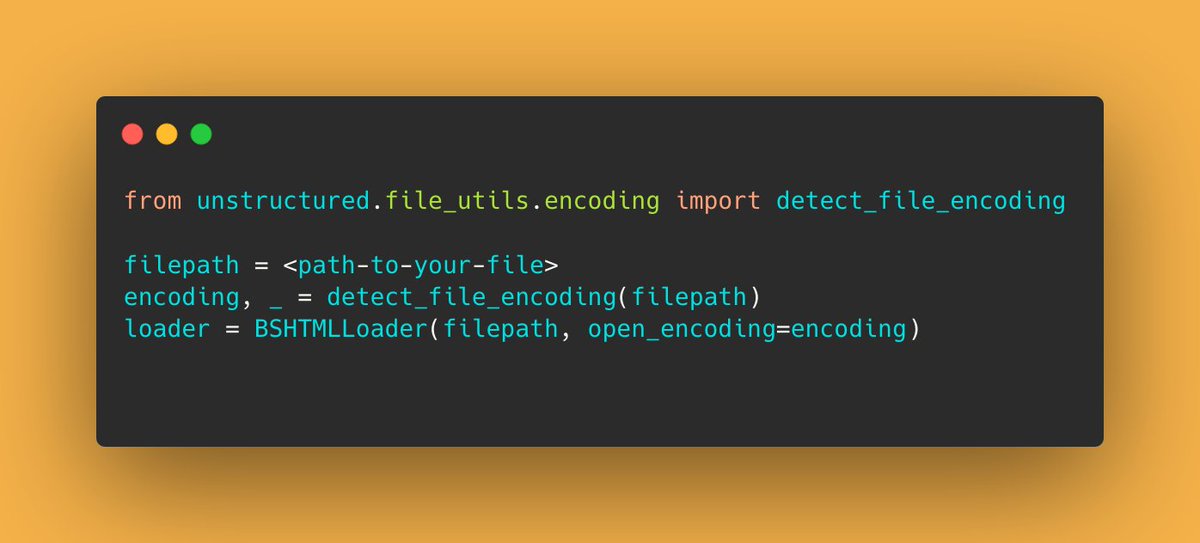
When using one of the @langchain loaders I stumbled across encoding errors for some files.
Fortunately, there inside the unstructured package there exists a method that helps to detect the encoding which you can use for most data loaders like below.
Interesting user flow when intending to test out Threads and creating an Instagram as part of that. Received this within an hour of signup. Literally have not done any action on either one account since creation
Quick note – we've transitioned from the deprecated vicuna benchmark to a more advanced MT-bench, including more challenging tasks and addressing biases/limitations in gpt4 eval.
We find OpenChat's performance on MT-bench is similar to wizardlm-13b.
That's said, there remains a significant gap between open models and GPT-3.5, which is exactly what we aim to emphasize with MT-bench - to highlight this discrepancy. Though not flawless, it's one step towards a better chatbot evaluation.
Please check out our paper/blog for more technical details and leaderboard for complete rankings.
Blog: https://t.co/lSQoopBnQG
Leaderboard: https://t.co/lHWL4Yzot1
MT-bench Paper: https://t.co/FxKJTBMLuu
@supabase This is great! Maybe you can consider to add format transformation (e.g. jpeg to webp) for further optimization.
I believe Astro has a similar feature .
https://t.co/IyybzG9y8I
Another top OS LLM! Soon OS models will be able to perform on the same level as today's benchmark model, GPT-4. UltraChat is not for commercial use. https://t.co/tpBHznpMxQ