Super thrilled to share that our work, SRL-CLIP, won the Best Paper Award at the CV4Smalls #CVPR2026 workshop! 🏆 Huge thanks to my amazing co-authors @zeeshank95 and @MakarandTapaswi .
Also, a big thank you to the organizers (@shaydamoezzi and team) for putting together such a thoughtful workshop. With the current trend of "scaling everything," it is incredibly refreshing to focus on data inefficiency as a design opportunity rather than a limitation. Data efficiency is one of the main pillars needed to improve real-world video understanding.
Hi all! Today I will present our work, SRL-CLIP, a recipe to efficiently adapt CLIP to videos at the CV4Smalls CVPR workshop in Room 102. I have an oral talk scheduled at 2 pm followed by the poster session. Please do stop by! Work done with @zeeshank95@MakarandTapaswi#CVPR2026
MINERVA-Cultural is a step toward helping the world build more equitable and diverse VLMs 🌍. Huge thanks to all my co-authors and the team!. Check out the paper here: https://t.co/b6L08Ix1t2 and the dataset here: https://t.co/W3K2me5WS6 #CVPR2026#AI#ComputerVision (7/7)
Frontier models have become excellent at understanding videos. But what happens when we test them outside the comfort zone of Western, English-centric data? In our #CVPR2026 (Highlight) work, we pushed these models to their limits to see if they can function effectively in diverse global contexts. The results? They are struggling. Work done with @NagraniArsha@skawshik11@Harman26Singh@dinesh_tewari1@0xtob@CordeliaSchmid Anelia Angelova @shachi_dave (1/7)
This allows us to independently assess each intermediate step of the model's thought process. 🔍 Through our graph-based error tracing, we discovered that roughly 75% of all model failures actually stem from the visual perception of cultural elements. 🤯(6/7)
Hi all! Today I will present our work, SRL-CLIP, a recipe to efficiently adapt CLIP to videos at the CV4Smalls CVPR workshop in Room 102. I have an oral talk scheduled at 2 pm followed by the poster session. Please do stop by! Work done with @zeeshank95@MakarandTapaswi#CVPR2026
Grateful to be recognized as an Outstanding reviewer at #CVPR2026. Always happy to do my part and give back to the community. This CVPR is very special for me because we also have 1 Main paper (Highlight) and 1 workshop paper (Best paper candidate). See you all in Denver! 🚀
We are grateful to all of the 17,491 reviewers who helped make #CVPR2026 possible. We are especially pleased to recognize the following Outstanding Reviewers, whose high-quality reviews (as judged by their Area Chairs) placed them among the top 5% of reviewers.
The Project Aria team is excited to be part of the Third Joint Egocentric Vision (EgoVis) Workshop at #CVPR2026! 👓✨
Don’t miss the latest Project Aria updates as we dive into the future of egocentric perception. Check out the full program of invited speakers below!
📅 June 3, 2026
📍 Colorado Convention Center | Room 704/706
🔗 https://t.co/g1FA6Cx4RU
⚡️@liuziwei7 , @mapo1 , @doughty_hazel
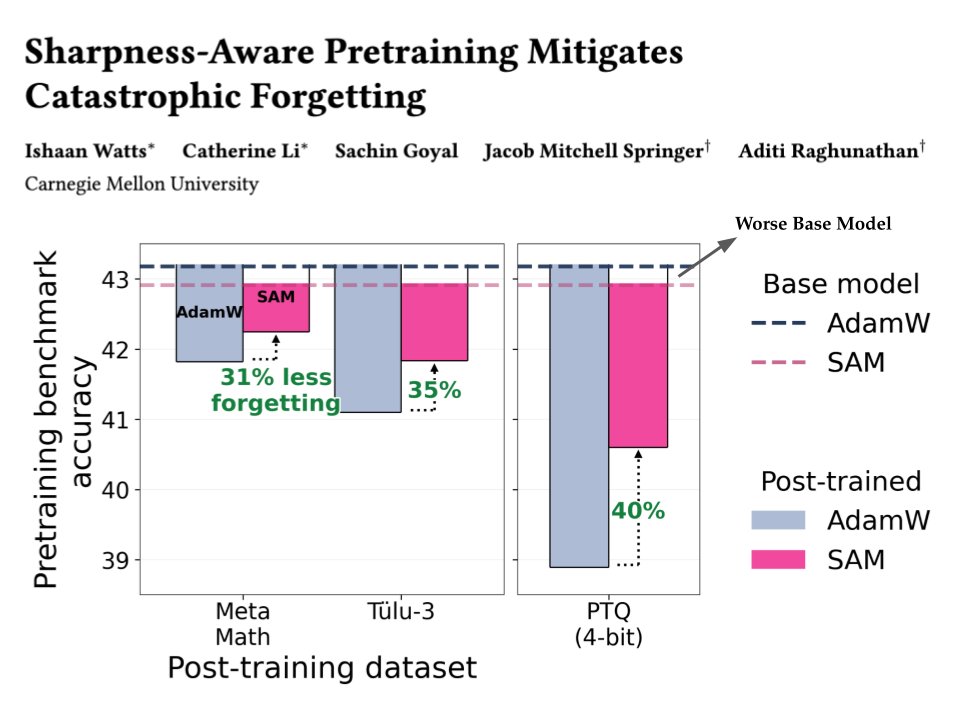
Spending billions to train the "best" base model? You might be optimizing the wrong thing! 🎯
We show that controlling sharpness during mid-training leads to over 35% less forgetting after fine-tuning / quantization... even when the base model itself gets worse.
🧵 Takeaways for pretraining:
- Use SAM (Sharpness-Aware-Minimization) in the final steps (~10%)
- Try much higher learning rates (yes, even ~10× larger)
1/9
Pretrained ViTs like DINOv2 or CLIP are great, but they produce fixed, generic representations that encode the most salient visual concepts (e.g., "cat").
In human vision, prior priming with language changes how people parse an image. We believe visual encoders should do the same
🚨 Introducing Steerable Visual Representations, a new family of visual features you can steer with text towards specific visual concepts.
Can LLMs Self-Verify? Much better than you'd expect.
LLMs are increasingly used as parallel reasoners, sampling many solutions at once.
Choosing the right answer is the real bottleneck.
We show that pairwise self-verification is a powerful primitive.
Introducing V1, a framework that unifies generation and self-verification:
💡 Pairwise self-verification beats pointwise scoring, improving test-time scaling
💡 V1-Infer: Efficient tournament-style ranking that improves self-verification
💡 V1-PairRL: RL training where generation and verification co-evolve for developing better self-verifiers
🧵👇
Our paper was desk rejected @NeurIPSConf! Even before the main deadline! "Non-academic title and abstract" 🙈
Thankfully, @SIGGRAPHAsia was around the corner and a perfect fit for our work on improving robustness of multi-subject multi-attribute layout-guided T2I models!
🧵1/9
Researchers consider themselves very successful if they win one test-of-time award (and one is more than enough). Ross @inkynumbers has been winning them nonstop over the past year: CVPR 2024, ICCV 2025, and now NeurIPS 2025, because winning just one was too easy for him!
Having known him for many years (first as a climbing partner and then as a colleague), I can’t say I’m surprised. When he sets his mind to something, he perfects it, whether it is making the best vision model, climbing a 5.12d, or continuing the sally-up sally-down push-up challenge until the rest of the team gives up.
And to all his collaborators who only worked with him remotely and didn’t get to see him in person every day: you missed out. He is fun to work with but he is even more fun in person. I'm attaching the proof below. I have some true gem videos of his goofy side that I won’t share (saving them for when I need to blackmail him), but here is a photo of Ross pretending to be a lizard under our office sun lamp.
Congratulations to Ross and all his co-authors.
#NeurIPS2025
The NeurIPS Test of Time Award recognizes papers that have made lasting contributions to machine learning. For 2025 the award goes to…(https://t.co/HtaOs96F8R) #NeurIPS2025#NeurIPSanDiego"
Late life update 🚀 I started my PhD at @UCBerkeley after an incredible time at @GoogleDeepMind. It was exciting to work on Gemini over the past couple of years.
These days I am interested in reasoning/improving RL, agents, and diffusion language models. Looking forward to contributing to open science. Also thrilled to be back in the Bay Area.
Grateful to mentors, collaborators, and folks who supported me, @partha_p_t@PengchuanZ@nitish_gup@trevorcohn@xiangrenNLP@divy93t@ManishGuptaMG1, Parag Singla, friends, and family.
Excited to be at @NeurIPSConf #NeurIPS2025 this week. Looking forward to meeting folks. Feel free to DM if you'd like to chat!
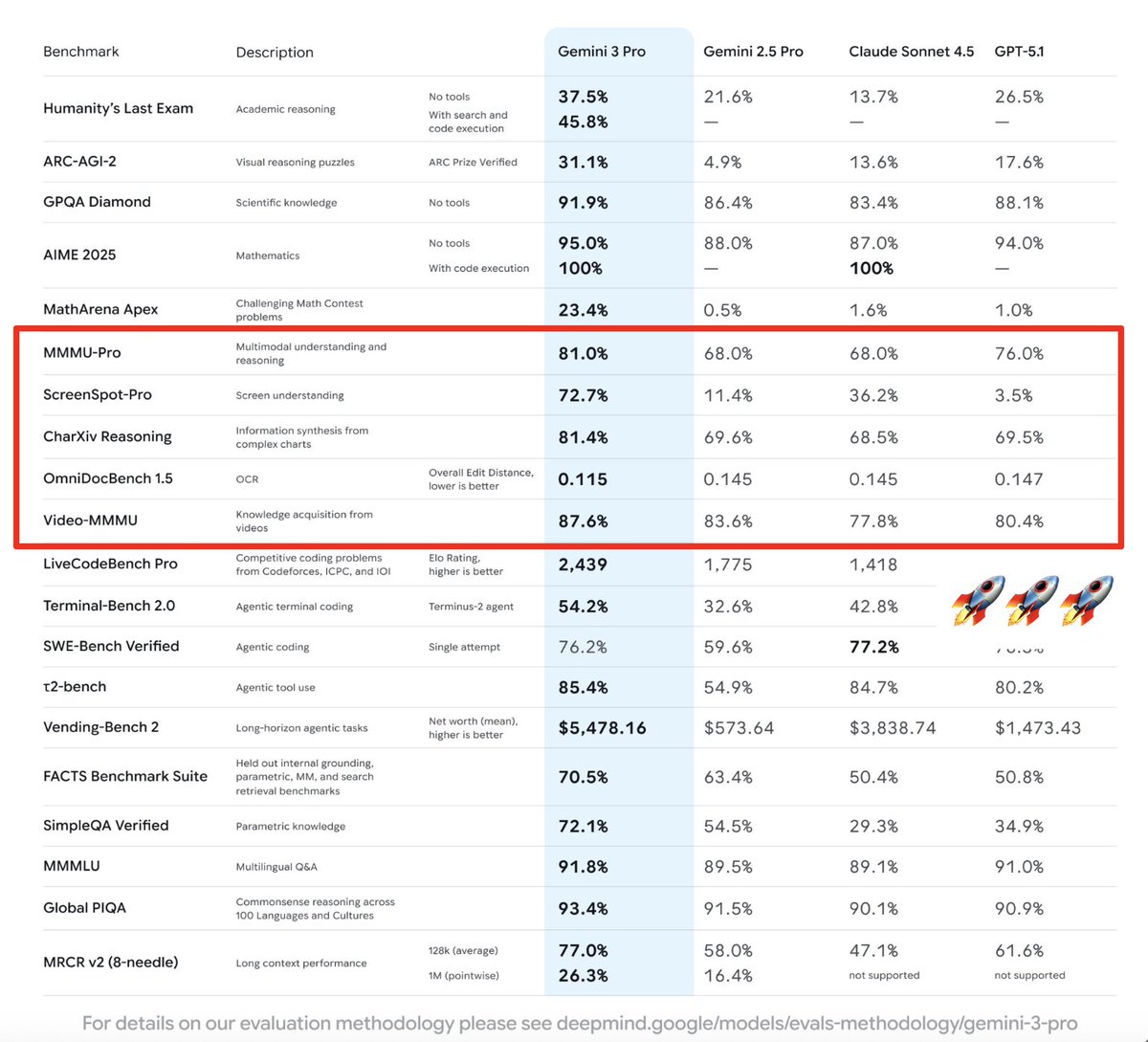
Really proud of what we have achieved with Gemini 3 🚀!
The Gemini MM team has worked relentlessly across image 🖼️ and video 🎥 from pre-training to post-training to simply deliver the best multimodal in the world 👏!
Looking forward to what you will build🫡!