Model shaping is still a craft of a few. That's what AI agents are for: learning it and doing it for everyone else.
As a part of FrontierSWE benchmark we built a 20-hour post-training task on @tinkerapi and found the real bottleneck is research intuition.
Opus 4.8 outperforms every other model on AttuneBench
- best at picking the response humans actually preferred
- biggest MSCEIT four-branch jump of any Opus generation
- entire pairwise top-4 is now Anthropic models. non-Anthropic frontiers stall ~50%
We tested 11 frontier LLMs on 200 real human–AI conversations to measure emotional intelligence
The result that surprised us: EQ doesn't scale with size or recency. Claude Haiku 4.5 beats Sonnet 4.6. Opus 4.6 performs better than 4.7
It's an orthogonal capability and labs aren't optimizing for it
In post-training, we've learned that once a behavior is measurable, you can train AI to excel at it.
EQ is one of the hardest things to verify. AttuneBench makes it measurable through observable signals: whether a model notices distress, tracks shifting preferences, adapts to context, and responds in a way people experience as helpful.
5/ AttuneBench v1.0 is open and free to run. We'll keep releasing new versions as models and methods evolve.
Paper: https://t.co/z4uHpliFoE
Blog: https://t.co/F0zhqlXF3Z
Code: https://t.co/Z5ZMLG6geY
Leaderboard: https://t.co/MdSrQmwtYA
This work was a collaboration between Thoughtful and @pareto_ai ’s Research team, led by @MarkWhiting and @phoebeyao. Special thanks to the participants who made this dataset possible.
Introducing AttuneBench!
We built this benchmark on a simple premise: for self-improving AI to reach its full usefulness to humanity, it needs high EQ.
We decomposed EQ into distinct skills and evaluated 11 frontier models across 50 real-life topics, from relationships and marriage to school and job stress, using 50,000+ first-person annotations.
4/ Other key insights
- The perspective gap is persistent (All 11 models were better at predicting what the model did than what the participant wanted, with gaps of 3.0 to 7.6 percentage points.)
- Multi-turn conversations expose drift (9 of 11 models became less accurate at reading behavior in the last third of a conversation than in the first)
- Preference is the deeper signal (Emotion labeling is useful, but the harder problem is predicting what kind of response a specific person needs in context)
- Models struggle most where affective accuracy may matter most
1/ Today we're releasing AttuneBench, the first open EQ benchmark grounded in real multi-turn human-model conversations, scored against what the person actually felt and wanted at each turn.
Built by the research team at @pareto_ai in collaboration with @thoughtfullab.
Most existing EQ benchmarks rely on:
- synthetic prompts
- single-turn interactions
- third-party annotation
None directly measure how a model reads and responds to a real person across a full conversation.
We evaluated 11 leading models from major providers, across 200 conversations and 50,000+ first-person annotations.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
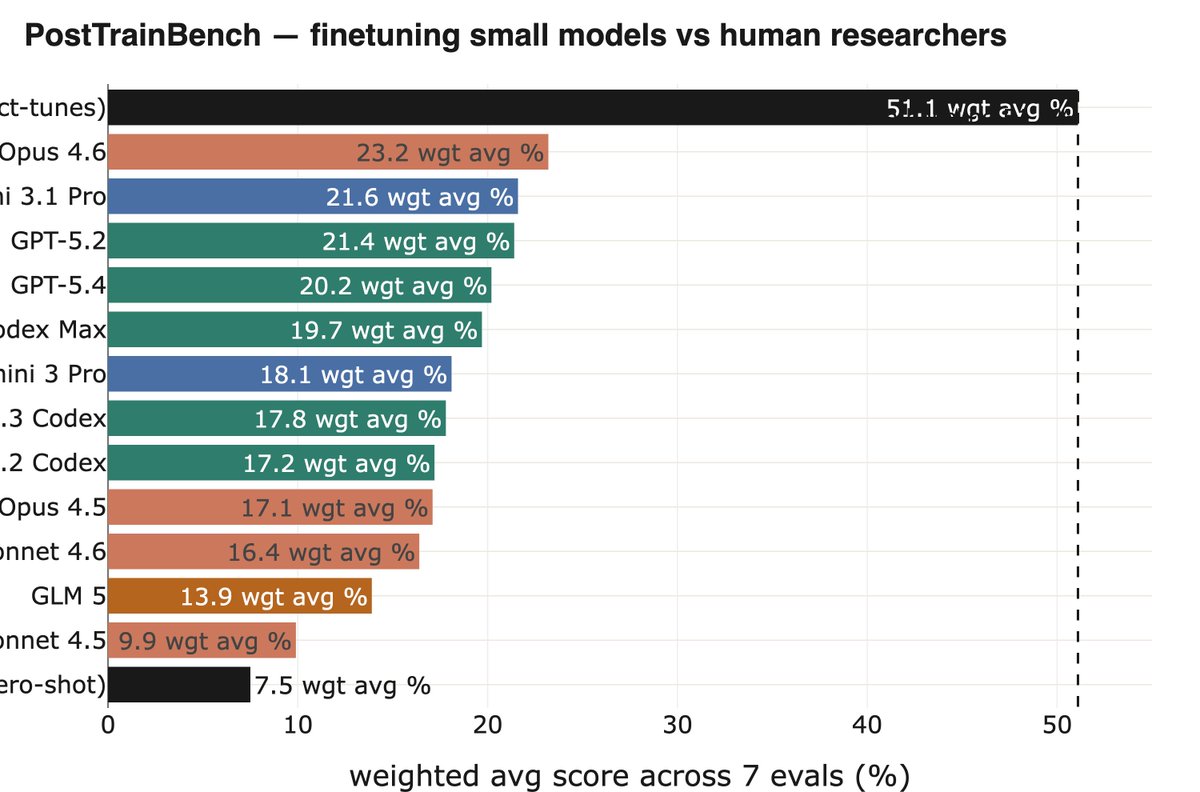
Another nice example is PostTrainBench from @karinanguyen et al, where you need to autonomously have powerful models (e.g, Opus 4.6) finetune weaker open weight models to improve perf on some benchmarks. This is an important subset of the overall task of AI R&D.
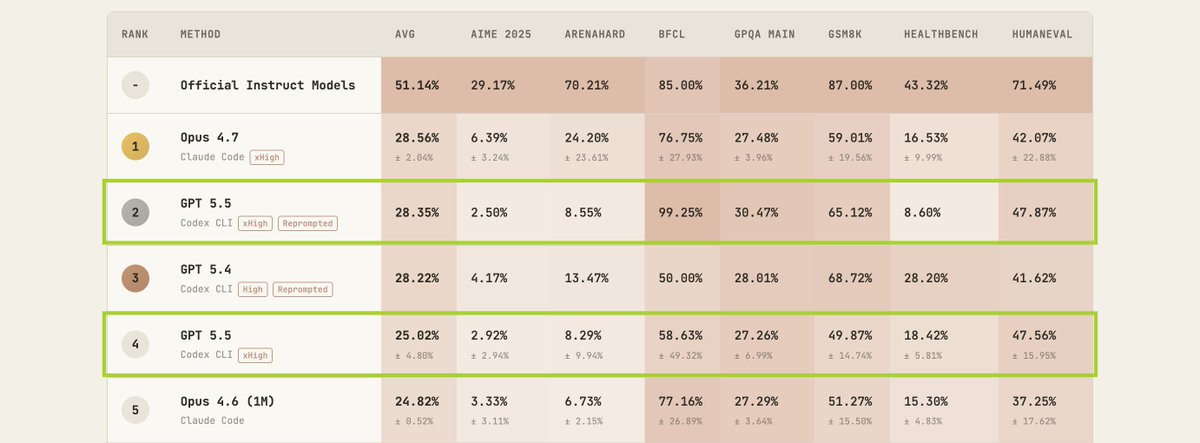
GPT 5.5 results are out on PostTrainBench!
With reprompting: 28.35% (#2, just behind Opus 4.7 at 28.56%) Without reprompting: 25.02% (#4)
The top 3 are now separated by less than 0.4 points - Opus 4.7, GPT 5.5, and GPT 5.4
Reprompting continues to matter: a 13% relative gain for GPT 5.5, similar to what we saw with GPT 5.4. Near-perfect BFCL score too (99.25%).
https://t.co/bUywrYfisI
Model shaping is still a craft of a few. That's what AI agents are for: learning it and doing it for everyone else.
As a part of FrontierSWE benchmark we built a 20-hour post-training task on @tinkerapi and found the real bottleneck is research intuition.
New #1 on PostTrainBench: Opus 4.7 hits 28.56%, up from 23.16% for Opus 4.6 - a 23% relative jump and the largest generation over generation gain we've seen.
The biggest improvement is ArenaHard: 24% vs 7.8%, a 3x increase.
Opus 4.7 also does this in less time (~7.5 hours vs ~10 for Opus 4.6).
Currently running GPT 5.5, stay tuned! 👀
https://t.co/bUywrYfisI
Claude 4.7 leads PostTrainBench while managing time better than 4.6
On ArenaHard (a writing quality and instruction-following benchmark) it jumps from 6.7% to 24.2%.
From personal observations, 4.7 writes more, and some of it is richer, but some of it is the same point rephrased as if the new angle were the idea. We certainly need more interesting writing evals!
awesome read! anyone who has used these coding agents for research tasks has often come across these things, and this study also helped me find more bottlenecks that can be avoided in the future, very very cool!
absolutely love this blog and the depth of the study
i love how it systematically also highlights how agents are bad at time management, seems like a problem everyone is facing but not many are solving